







microsoft/BitNet最快推理!!!
| AI学习交流qq群 | 873673497 |
| 官网 | turingevo.com |
| 邮箱 | wmx@turingevo.com |
| github | https://github.com/turingevo |
| huggingface | https://huggingface.co/turingevo |
| 日期 | 论文 |
|---|---|
| 10/21/2024 | 1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs |
| 10/17/2024 | bitnet.cpp 1.0 released. |
| 03/21/2024 | The-Era-of-1-bit-LLMs__Training_Tips_Code_FAQ |
| 02/27/2024 | The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits |
| 10/17/2023 | BitNet: Scaling 1-bit Transformers for Large Language Models |
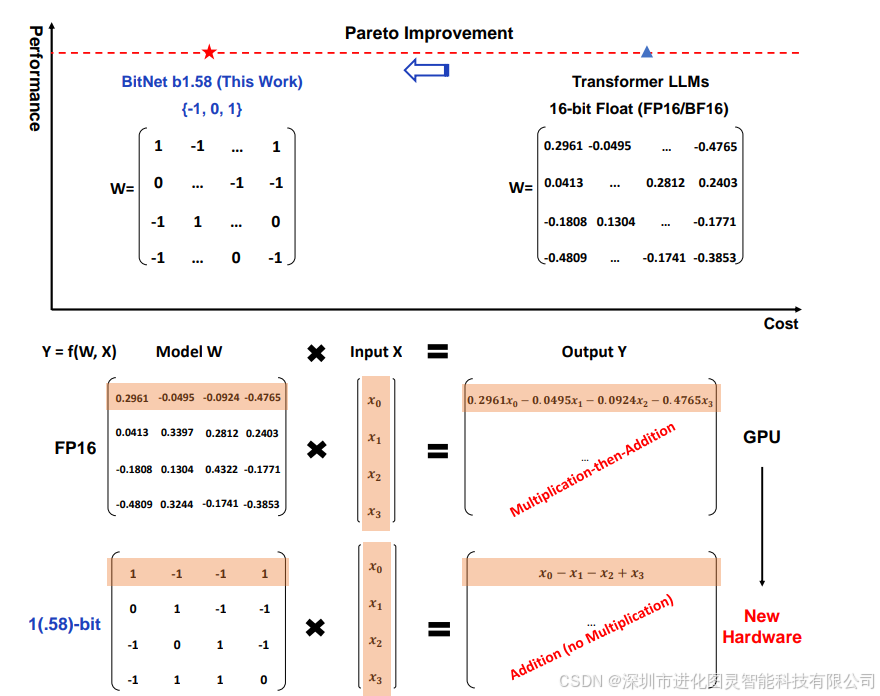
其中 b1.58 量化 ,直接把矩阵浮点乘法 变 整数加法,更高效、更节能
system
| os | ubuntu22.04 |
| cpu | x86_64 |
1 下载源码
源码地址 https://github.com/microsoft/BitNet
git clone --recursive https://github.com/microsoft/BitNet.git
cd BitNet
2 安装依赖环境
使用conda
conda create -p ./venv python=3.9
conda activate ./venv
pip install -r requirements.txt
3 下载模型
| Model | Parameters | CPU | Kernel | ||
|---|---|---|---|---|---|
| I2_S | TL1 | TL2 | |||
| bitnet_b1_58-large | 0.7B | x86 | ✔ | ✘ | ✔ |
| ARM | ✔ | ✔ | ✘ | ||
| bitnet_b1_58-3B | 3.3B | x86 | ✘ | ✘ | ✔ |
| ARM | ✘ | ✔ | ✘ | ||
| Llama3-8B-1.58-100B-tokens | 8.0B | x86 | ✔ | ✘ | ✔ |
| ARM | ✔ | ✔ | ✘ | ||
模型 Llama3-8B-1.58-100B-tokens 下载到 /media/wmx/soft1/huggingface_cache/Llama3-8B-1.58-100B-tokens
4 下载配置编译器
llvm : https://github.com/llvm/llvm-project/releases
我这下载的是 LLVM-19.1.3-Linux-X64
放在路径 /media/wmx/ws1/software/LLVM-19.1.3-Linux-X64
在 BitNet/CMakeLists.txt 添加 指定clang 编译器相关路径
set(CMAKE_CXX_STANDARD_REQUIRED true)
set(CMAKE_C_STANDARD 11)
set(CMAKE_C_STANDARD_REQUIRED true)
set(THREADS_PREFER_PTHREAD_FLAG ON)
# 在上面4行代码下添加 :
###------------------- wmx add llvm clang
set(CMAKE_CXX_COMPILER /media/wmx/ws1/software/LLVM-19.1.3-Linux-X64/bin/clang++)
set(CMAKE_C_COMPILER /media/wmx/ws1/software/LLVM-19.1.3-Linux-X64/bin/clang)
include_directories(/media/wmx/ws1/software/LLVM-19.1.3-Linux-X64/include)
link_directories(
/media/wmx/ws1/software/LLVM-19.1.3-Linux-X64/lib
/media/wmx/ws1/software/LLVM-19.1.3-Linux-X64/lib/x86_64-unknown-linux-gnu/
)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -stdlib=libc++")
set(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} -stdlib=libc++ -lc++ -lc++abi")
###------------------- wmx add llvm clang
5 添加脚本 wmx_test.sh
BitNet/wmx_test.sh
# 激活虚拟环境
conda activate ./venv
export LLVM_BASE=/media/wmx/ws1/software/LLVM-19.1.3-Linux-X64
export LD_LIBRARY_PATH=$LLVM_BASE/lib:$LLVM_BASE/lib/x86_64-unknown-linux-gnu:$LD_LIBRARY_PATH
# /media/wmx/soft1/huggingface_cache/Llama3-8B-1.58-100B-tokens
# /media/wmx/soft1/huggingface_cache/bitnet_b1_58-large
raw_model=/media/wmx/soft1/huggingface_cache/Llama3-8B-1.58-100B-tokens
# 构建 & 转换模型
setup_env(){
echo "setup_env"
python setup_env.py -md $raw_model -q i2_s
}
# ------------------ run_inference ----------------------------------
model_path=/media/wmx/soft1/huggingface_cache/bitnet_b1_58-large/ggml-model-i2_s.gguf
p1="Daniel went back to the the the garden. \
Mary travelled to the kitchen. Sandra journeyed to the kitchen.\
Sandra went to the hallway. John went to the bedroom. Mary went back to the garden.\
Where is Mary?\nAnswer:"
p2="Introduce Mr. Trump"
run()
{
echo "run_inference prompt is :\n $1 \n "
python run_inference.py -m $model_path \
-n 6 \
-temp 0 \
-p "$1"
}
### usage :
# source wmx_test.sh
# setup_env
# run "$p1"
# run "$p2"
授权执行
chmod a+x wmx_test.sh
6 编译工程
1 编译工程
2 转换模型到 gguf
3 量化到 i2_s
source wmx_test.sh
setup_env
输出 :
(base) wmx@wmx-ubuntu:/media/wmx/soft1/AI-model/BitNet$ source wmx_test.sh
(/media/wmx/soft1/AI-model/BitNet/venv) wmx@wmx-ubuntu:/media/wmx/soft1/AI-model/BitNet$ setup_env
setup_env
INFO:root:Compiling the code using CMake.
INFO:root:Loading model from directory /media/wmx/soft1/huggingface_cache/Llama3-8B-1.58-100B-tokens.
INFO:root:GGUF model save at /media/wmx/soft1/huggingface_cache/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf
7 推理
source wmx_test.sh
run "$p1"
输出:
.................................................................
llama_new_context_with_model: n_batch is less than GGML_KQ_MASK_PAD - increasing to 32
llama_new_context_with_model: n_ctx = 2048
llama_new_context_with_model: n_batch = 32
llama_new_context_with_model: n_ubatch = 32
llama_new_context_with_model: flash_attn = 0
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: CPU KV buffer size = 288.00 MiB
llama_new_context_with_model: KV self size = 288.00 MiB, K (f16): 144.00 MiB, V (f16): 144.00 MiB
llama_new_context_with_model: CPU output buffer size = 0.12 MiB
llama_new_context_with_model: CPU compute buffer size = 5.00 MiB
llama_new_context_with_model: graph nodes = 870
llama_new_context_with_model: graph splits = 1
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
main: llama threadpool init, n_threads = 2
system_info: n_threads = 2 (n_threads_batch = 2) / 32 | AVX = 1 | AVX_VNNI = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 1 | NEON = 0 | SVE = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | RISCV_VECT = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 | LLAMAFILE = 1 |
sampler seed: 4294967295
sampler params:
repeat_last_n = 64, repeat_penalty = 1.000, frequency_penalty = 0.000, presence_penalty = 0.000
top_k = 40, tfs_z = 1.000, top_p = 0.950, min_p = 0.050, typical_p = 1.000, temp = 0.000
mirostat = 0, mirostat_lr = 0.100, mirostat_ent = 5.000
sampler chain: logits -> logit-bias -> penalties -> greedy
generate: n_ctx = 2048, n_batch = 1, n_predict = 6, n_keep = 1
Daniel went back to the the the garden. Mary travelled to the kitchen. Sandra journeyed to the kitchen. Sandra went to the hallway. John went to the bedroom. Mary went back to the garden. Where is Mary?
Answer: The garden.
Daniel went
llama_perf_sampler_print: sampling time = 0.07 ms / 63 runs ( 0.00 ms per token, 913043.48 tokens per second)
llama_perf_context_print: load time = 117.87 ms
llama_perf_context_print: prompt eval time = 564.99 ms / 57 tokens ( 9.91 ms per token, 100.89 tokens per second)
llama_perf_context_print: eval time = 48.44 ms / 5 runs ( 9.69 ms per token, 103.22 tokens per second)
llama_perf_context_print: total time = 614.03 ms / 62 tokens



















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









