







User ainta has a permutation p1, p2, ..., pn. As the New Year is coming, he wants to make his permutation as pretty as possible.
Permutation a1, a2, ..., an is prettier than permutation b1, b2, ..., bn, if and only if there exists an integer k (1 ≤ k ≤ n) where a1 = b1, a2 = b2, ..., ak - 1 = bk - 1 and ak < bk all holds.
As known, permutation p is so sensitive that it could be only modified by swapping two distinct elements. But swapping two elements is harder than you think. Given an n × n binary matrix A, user ainta can swap the values of pi and pj (1 ≤ i, j ≤ n, i ≠ j) if and only if Ai, j = 1.
Given the permutation p and the matrix A, user ainta wants to know the prettiest permutation that he can obtain.
The first line contains an integer n (1 ≤ n ≤ 300) — the size of the permutation p.
The second line contains n space-separated integers p1, p2, ..., pn — the permutation p that user ainta has. Each integer between 1 andn occurs exactly once in the given permutation.
Next n lines describe the matrix A. The i-th line contains n characters '0' or '1' and describes the i-th row of A. The j-th character of the i-th line Ai, j is the element on the intersection of the i-th row and the j-th column of A. It is guaranteed that, for all integers i, j where 1 ≤ i < j ≤ n, Ai, j = Aj, i holds. Also, for all integers i where 1 ≤ i ≤ n, Ai, i = 0 holds.
In the first and only line, print n space-separated integers, describing the prettiest permutation that can be obtained.
7 5 2 4 3 6 7 1 0001001 0000000 0000010 1000001 0000000 0010000 1001000
1 2 4 3 6 7 5
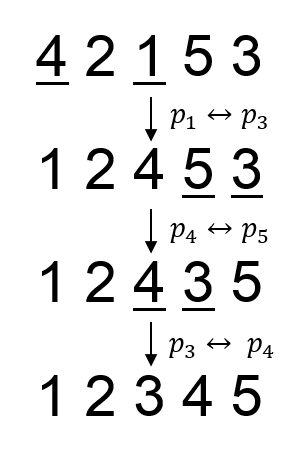
5 4 2 1 5 3 00100 00011 10010 01101 01010
1 2 3 4 5
In the first sample, the swap needed to obtain the prettiest permutation is: (p1, p7).
In the second sample, the swaps needed to obtain the prettiest permutation is (p1, p3), (p4, p5), (p3, p4).
A permutation p is a sequence of integers p1, p2, ..., pn, consisting of n distinct positive integers, each of them doesn't exceed n. The i-th element of the permutation p is denoted as pi. The size of the permutation p is denoted as n
题目大意:
#include <iostream>
#include <string.h>
#include <cstring>
#include <string>
#include <algorithm>
#include <stack>
#include <queue>
#include <stdio.h>
#include <stdlib.h>
#include <cstdlib>
#include <cmath>
#include <math.h>
#include <vector>
#include <map>
#include <time.h>
#include <ctime>
using namespace std;
#define M 305
#define inf 0xfffffff
int num[M];
int father[M];
int sum[M];
typedef struct{
int k; //记录结点的在num数组的位置
int value; //记录结点的值
bool vis; //记录结点是否被访问
}Node;
vector <Node> p; //相同父结点的值push到vector中
void merge(int a, int b);
int find(int a);
void Sort(); //用来排序的自定义函数
int main()
{
int n;
cin >> n;
memset(num,0,sizeof(num));
memset(sum,0,sizeof(sum));
int a;
char ch;
for(int i = 1; i < M; i++)
father[i] = i;
for(int i = 1; i <= n; i++)
cin >> num[i];
getchar();
for(int i = 1; i <= n; i++)
{
for(int j = 1;j <= n; j++)
{
cin >> ch;
if(ch == '1') //如果为1,合并两个元素
merge(i,j);
}
getchar();
}
for(int i = 1; i <= n; i++) //统计一个父结点出现的次数
sum[find(i)]++;
for(int i = 1; i <= n; i++)
{
if(sum[i] > 1) //父节点的次数出现两次及以上才进行操作
{
p.clear();
a = find(i); //找到父结点
for(int j = 1; j <= n; j++) //重新找有相同父结点的元素
{
if(find(j) == a)
{
Node node;
node.k = j;
node.value = num[j];
node.vis = false;
p.push_back(node);
}
}
Sort();
}
}
for(int i = 1; i <= n; i++)
printf("%d ",num[i]);
printf("\n");
return 0;
}
int find(int a)
{
while(a!=father[a])
a = father[a];
return a;
}
void merge(int a, int b)
{
int num1, num2;
num1 = find(a);
num2 = find(b);
if(num1 != num2)
father[num1] = num2;
}
void Sort()
{
int min;
int mini;
int minj;
int i, j;
for(i = 0; i < p.size(); i++)
{
min = inf;
for(j = 0; j < p.size(); j++) //找出最小元素
{
if((p[j].value < min) && (!p[j].vis))
{
min = p[j].value;
mini = p[j].k;
minj = j;
}
}
p[minj].vis = true;
num[p[i].k] = min; //将最小元素插入到i的位置
}
}















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









