






一、熵权法简介
说到熵权法就得先说熵,在信息论中,熵是对不确定性的一种度量,可判断一个事件的随机性及无序程度。用熵值来判断某个指标的离散程度,指标的离散程度越大,该指标对综合评价的影响越大。
下面举一个例子来直观的看看熵:考试成绩
如果有某一门课“不易拉开差距”,意味着这一门课对最终总成绩排名影响很小。比如如果所有人的化学成绩相同,意味着“整齐划一”,相应混乱程度就低。
在本模型中,混乱程度低对应着熵值接近1,评价总成绩时可给该指标赋予低权重;相对的,如果说数学的分差距较大,如果去掉这门课,总成绩排名可能会出现变化。
二、适用赛题
数据全面、缺少文献或主观题目依据的题目
- 例如评价河流水质,已知河流的含氧量、PH值、细菌密度、生物密度等数据
- 但缺乏水质的文献资料,或者文献内说法不一
- 即文献很难帮助我们确定影响水质最重要的因素是哪一个
- 也很难告诉我们其余指标的重要程度如何衡量
- 此时可使用熵权法,根据数据本身建立评价体系
注意事项
- 熵权法与其他方法(层次分析法、TOPSIS法等)最大的区别就是完全客观
- 追求“公平公正”的情况,可以优先考虑熵权法
- 但有时“完全客观”也是缺点,难以将数据之外的因素考虑进去
三、模型流程

四、流程分析
1.数据标准化
标准化的原因
- 评价体系中,存在数值越大越好的正项指标,和数值越小越好的负向指标
- 不同指标数量级也可能不同;且求熵的公式中用到对数函数,变量不允许有负值
标准化
- 正向指标标准化
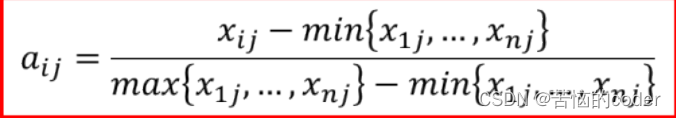
- 负向指标标准化
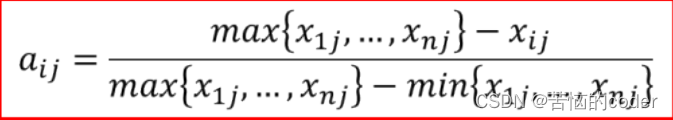
标准化之后,数据所有值在[0, 1]区间内,且都是数值越大、现实意义越好。
2.计算熵值和变异程度
首先得求每个评价对象在各个指标中的比重,可理解为统计意义上某种情况出现的概率

有了比重可以求熵值,对于第j个指标,其熵值ej为
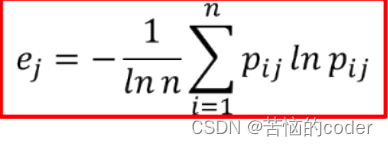
而变异程度与熵值有关
- 第j个指标的变异程度:gj = 1 - ej
- 显然熵值越大、变异程度越小,代表该指标越有序,该指标的信息量也就越小
注:上面的公式与热力学息息相关,这里不对公式作证明。
3.计算权重和综合评分
通过变异程度求权重
- 计算第j个指标的权重

- 指标的变异程度越大、信息量越大,相应指标的权重也越大
通过权重和比重求综合评价值
- 计算第i个评价对象的综合评价值

- 该公式对不同科目加权求和,得到每个评价对象的平均值,评价值越大越好
- pij和wj都是原始数据求得的,完全客观,不掺杂主观成分
将综合评价值由大到小排序,排序完成。
















 4526
4526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











