






一、模型引出
1、问题的提出
根据前几篇文章我们知道,评价决策类的模型最后需要根据各个指标的重要程度进行加权,而之前的层次分析法和TOPSIS法的权重都是我们主观得到的,那有没有更为客观的方法呢?那我们接着引入之前的例题。
二、基本原理
1、基本概念
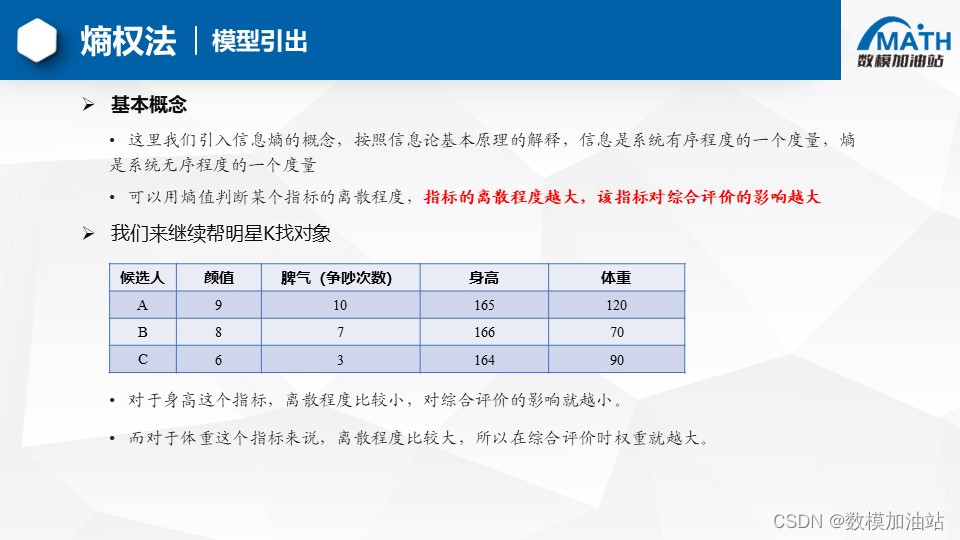
这里呢我们引入信息熵的概念,如果大家学过物理,就会知道熵代表着系统的紊乱程度,那如果按照信息论基本原理的解释,信息就是系统有序程度的度量,而熵呢是系统无序程度的度量,我们可以用熵值来判断某个指标的离散程度,那这个离散程度越大,就代表着信息熵值越小,那指标对于综合评价的影响也就越大,熵权法呢是一种非常客观的赋权方法,它可以靠数据本身来得出权重,那根据题目给出的既定的数据来判断权重,它依据的原理呢就是指标的变异程度越小,反应的信息量也就越少,对应的权值呢也就越低。

2、基本步骤
这个基本步骤还是比较简单的,第一步就是标准化,用每个指标除以这个指标所在列的平方和,当然这个列是代表着同一指标的数据。第二步是计算概率矩阵P,就是计算同一指标中某一样本所占的比重,说明白一点就是归一化,就是让指标除以它所在列的和。最后一步是计算熵权,那这里是熵权的公式有三个值,一个是ej,一个是dj,还有个wj,那接下来呢我们结合例题来看一下。
三、典型例题
这里呢,我们还是利用之前帮k哥选对象的例题,在之前的TOPSIS法中呢,我们已经得到了正向化矩阵,下一步就是进行正向化矩阵标准化,标准化就是用每个值除以它所在列的这些值的一个平方和,之后在开方。如果指标中有负数,就是指标值减去最小值除以最大值减最小值,下一步就要计算概率矩阵P了,概率矩阵P就是归一化,我们用每一个指标值除以所在列的和,那样就会得到一个0~1的数字,并且呢所有候选人这个数字加起来值是唯一的,最后我们计算熵权。(详细计算步骤请关注b站数模加油站)



四、相关代码
1、Matlab代码
(1)主代码
%% 1.对正向化后的矩阵进行标准化
% X=[9 0 0 0 ;8 3 0.9 0.5;6 7 0.2 1]
clear,clc;
X=input('指标矩阵X=');
[n,m] = size(X);
Z = X ./ repmat(sum(X.*X) .^ 0.5, n, 1);
disp('标准化矩阵 Z = ')
disp(Z)
%% 2.计算熵权
D = zeros(1,m); % 初始化保存信息效用值的行向量
for i = 1:m
x = Z(:,i); % 取出第i列的指标
p = x / sum(x);
% 注意,p有可能为0,此时计算ln(p)*p时,Matlab会返回NaN,所以这里我们自己定义一个函数
e = -sum(p .* mylog(p)) / log(n); % 计算信息熵
D(i) = 1- e; % 计算信息效用值
end
W = D ./ sum(D); % 将信息效用值归一化,得到权重
disp('权重 W = ')
disp(W)(2)函数代码
% 重新定义一个mylog函数,当输入的p中元素为0时,返回0
function [lnp] = mylog(p)
n = length(p); % 向量的长度
lnp = zeros(n,1); % 初始化最后的结果
for i = 1:n % 开始循环
if p(i) == 0 % 如果第i个元素为0
lnp(i) = 0; % 那么返回的第i个结果也为0
else
lnp(i) = log(p(i));
end
end
end
% % 注意:代码文件仅供参考,一定不要直接用于自己的数模论文中2、Python代码
import numpy as np # 导入numpy库,并简称为np
# 定义一个自定义的对数函数mylog,用于处理输入数组中的零元素
def mylog(p):
n = len(p) # 获取输入向量p的长度
lnp = np.zeros(n) # 创建一个长度为n,元素都为0的新数组lnp
for i in range(n): # 对向量p的每一个元素进行循环
if p[i] == 0: # 如果当前元素的值为0
lnp[i] = 0 # 则在lnp中对应位置也设置为0,因为log(0)是未定义的,这里我们规定为0
else:
lnp[i] = np.log(p[i]) # 如果p[i]不为0,则计算其自然对数并赋值给lnp的对应位置
return lnp # 返回计算后的对数数组
# 定义一个指标矩阵X
X = np.array([[9, 0, 0, 0], [8, 3, 0.9, 0.5], [6, 7, 0.2, 1]])
# 对矩阵X进行标准化处理,得到标准化矩阵Z
Z = X / np.sqrt(np.sum(X*X, axis=0))
print("标准化矩阵 Z = ")
print(Z) # 打印标准化矩阵Z
# 计算熵权所需的变量和矩阵初始化
n, m = Z.shape # 获取标准化矩阵Z的行数和列数
D = np.zeros(m) # 初始化一个长度为m的数组D,用于保存每个指标的信息效用值
# 计算每个指标的信息效用值
for i in range(m): # 遍历Z的每一列
x = Z[:, i] # 获取Z的第i列,即第i个指标的所有数据
p = x / np.sum(x) # 对第i个指标的数据进行归一化处理,得到概率分布p
# 使用自定义的mylog函数计算p的对数。需要注意的是,如果p中含有0,直接使用np.log会得到-inf,这里使用自定义函数避免这个问题
e = -np.sum(p * mylog(p)) / np.log(n) # 根据熵的定义计算第i个指标的信息熵e
D[i] = 1 - e # 根据信息效用值的定义计算D[i]
# 根据信息效用值计算各指标的权重
W = D / np.sum(D) # 将信息效用值D归一化,得到各指标的权重W
print("权重 W = ")
print(W) # 打印得到的权重数组W














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









