







数据预处理
数据预处理的过程
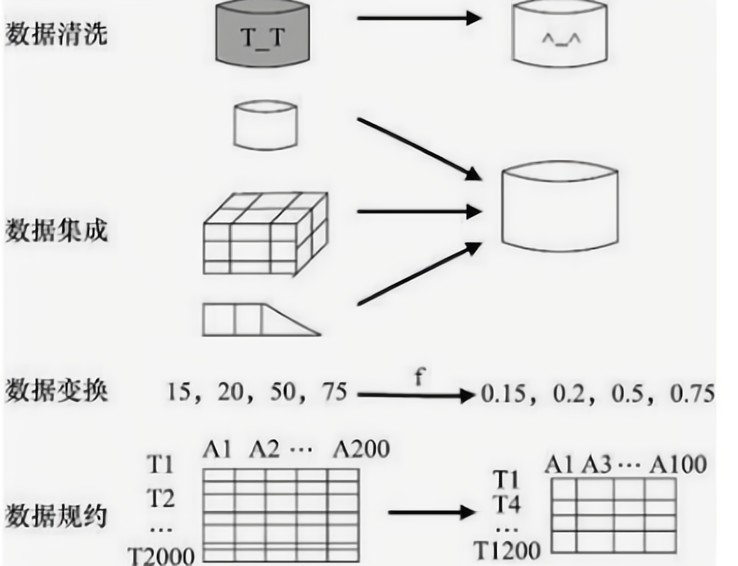
数据预处理的目的:
1)提高数据质量
2)让数更好地适应特定的挖掘技术或工具
数据预处理工作量占整个数据挖掘工作量的60%
1 数据清洗
数据清洗主要是删除原始数据集中的无关数据、重复数据,平滑噪声数据,筛选掉与挖掘主题无关的数据,处理缺失值、异常值等。

缺失值处理
常用的三种缺失值处理方法:
-
删除记录:
- 优点:简单直接,最有效
- 缺点:以减少历史数据来换取数据的完备,会造成资源的大量浪费,丢弃了大量隐藏在这些记录中的信息。尤其是在数据集本来就包含很少记录的情况下,删除少量记录就可能严重影响分析结果的客观性和正确性。
-
不处理:
- 一些模型可以将缺失值作为一种特殊的取值,允许直接在含有缺失值的数据上进行建模。
-
数据插补:
插补方法 方法描述 均值/中位数/众数插补 根据属性值的类型,用该属性取值的平均数/中位数/众数进行插补 使用固定值 将缺失的属性值用一个常量替换 最近临插补 在记录中找到与缺失样本最接近的样本的该属性作为插补 回归方法 对带有缺失值的变量,根据已有数据与其有关的其他变量的数据建立拟合模型来预测缺失值的属性值 插值法 利用已知点建立合适的插值函数f(x),未知值由对应点xi求出的函数值f(xi)近似替代。常用插值法有拉格朗日插值、hermite插值、分段插值、样条插值
异常值处理
常用的异常值处理方法:
| 异常值处理方法 | 方法描述 |
|---|---|
| 删除含有异常值的记录 | 直接将含有异常值的记录删除 |
| 视为缺失值 | 利用缺失值的处理方法进行处理 |
| 平均值修正 | 可用前后两个观测值的平均值修正该异常值 |
| 不处理 | 直接在具有异常值的数据集上进行挖掘建模 |
注意:有些异常值可能蕴含着有用的信息,因此,要先分析异常值出现的可能原因,再判断是否应该舍弃。例如:信用卡盗刷
2 数据集成
数据集成是将多个数据源合并存放在一个一致的数据存储位置中的过程。
注意:来自多个数据源的现实实体的表达形式是不一样的,有可能不匹配,要考虑实体识别问题和属性冗余问题,从而将源数据在最底层上加以转换、提炼和集成。
主要处理方法:
- 实体识别
- 冗余属性识别
- 数据变换
- 属性构造
- 小波变化
实体识别
实体识别从不同数据源识别出现实世界的实体,它的任务是统一不同源数据的矛盾之处。
常见的实体识别如下:
- 同名异义:数据源 A中的属性ID和数据源B中的属性ID分别描述的是菜品编号和订单编号,即描述的是不同的实体。
- 异名同义:数据源A中sales_dt和数据源B中sales_date都是描述销售日期,即A. sales_dt=B. sales_date。
- 单位不统一:描述同一个实体时分别用不同的单位,如kg和斤。
冗余属性识别
- 同一属性多次出现
- 同一属性命名不一致导致重复
有些冗余属性可以用相关分析检测。给定两个数值型的属性A和属性B,根据其属性值,用相关系数度量一个属性在多大程度上蕴含另一个属性。
数据变换
数据变换主要是对数据进行规范化处理,将数据转换成“适当的”形式,以适用于数据挖掘任务及算法的需要。
常见的变换有:
- 简单函数变换
- 规范化
- 连续数据离散化
简单函数变换
- 简单函数变换是对原始数据进行某些数学函数变换,常用的包括平方、开方、取对数、差分运算等。
- 简单函数变换常用来将不具有正态分布的数据变换成具有正态分布的数据。在时间序列分析中,简单的对数分析、差分分析可以将非平稳序列转换为平稳序列。
规范化
- 数据标准化(归一化)处理是数据挖掘中的一项基本工作。
- 为了消除指标之间的量纲和取值范围差异的影响,需要进行标准化处理,将数据按照比例进行缩放,使之落入一个特定的区域,便于进行综合分析。
- 例如:将工资收入属性值映射到[-1,1]或[0,1]内。
常见的规范化方法:
最小-最大规范化:离差标准化
x ∗ = x − min max − min x^{*}=\frac{x-\min }{\max -\min } x∗=max−minx−min
优点:保留原来数据中存在的关系,方法简单。缺点:若数值集中且某个数值很大,则规范后各值会接近于0,并且相差不大。若将来遇到超过[min,max]的属性值时,会引起系统错误,需要重新确定min和max。
零-均值规范化:标准差标准化
x ∗ = x − x ‾ δ x^{*}=\frac{x-\overline{\mathrm{x}}}{\delta} x∗=δx−x
x ‾ \overline{\mathrm{x}} x为原始数据均值,𝛿 为标准差。经过该方法处理的数据的均值为0,标准差为1。
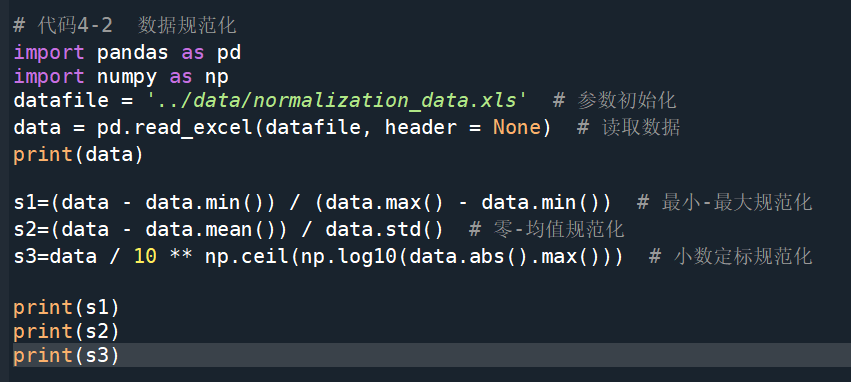
小数定标规范化
x ∗ = x 1 0 k x^{*}=\frac{x}{10^k} x∗=10kx
通过 移动属性值的小数位数,将属性值映射到[-1,1]之间,移动的小数位数取决于属性值绝对值的最大值。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pFHJmFZE-1666254460246)(C:/Users/THUNOEROBOT/AppData/Roaming/Typora/typora-user-images/image-20220827223333617.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JtZZHfQ8-1666254460247)(C:/Users/THUNOEROBOT/AppData/Roaming/Typora/typora-user-images/image-20220827223344854.png)]
连续属性离散化
- 一些数据挖掘算法,如 ID3 算法、Apriori 算法要求数据是分类属性形式(离散的)。这就要求将连续属性变换成分类属性,即连续属性离散化。
- 离散化的过程:在数据的取值范围内设定若干个离散的划分点,将取值范围划分为一些离散区域,最后用不同的符号或整数值代表落在每个子区间中的数据值。即离散化需要确定分类数和将连续属性映射到这些分类中。
- 常见的离散化方法
- **等宽法:**将属性的值域分成具有相同宽度的区间,区间的个数由数据本身的特点决定或者用户指定。 对于离群点敏感,倾向于不均匀地把属性值分不到各个区间。
- **等频法:**将相同数量的记录放进每个区间。 为了满足区间固定个数,相同的数值可能被划分到不同区间中。
- **基于聚类分析的方法:**首先将连续属性的值用聚类算法进行聚类,然后将聚类得到的簇进行处理,合并到一个簇的连续属性值做同一个标记。
属性构造
利用已有的属性集构出新的属性,并加入到现有的属性集当中。
例如:防窃漏电诊断建模时,已有的属性:供入电量、供出电量。理论上供入电量和供出电量应该是相等的。但由于传输过程中存在电能损耗,使得供入电量略大于供出电量。如果该条线路上的一个或者多个大用户存在窃漏电行为,会使得供入电量明显大于供出电量。
线损率
=
供入电量
−
供出电量
供入电量
∗
100
%
线损率=\frac{供入电量-供出电量}{供入电量}*100\%
线损率=供入电量供入电量−供出电量∗100%
3 数据规约
数据规约产生更小且保持原数据完整性的新数据集,在归约后的数据及上进行分析和挖掘将提高效率。
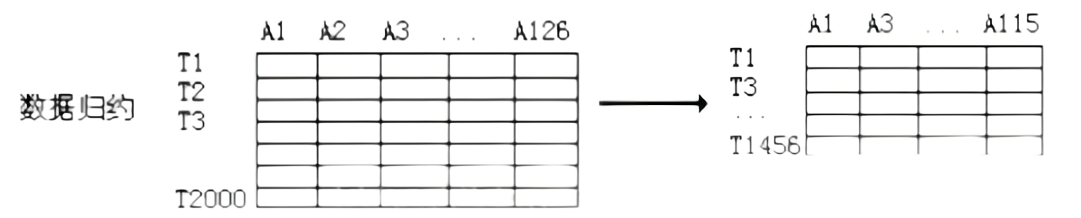
- 数据归约意义:
- 1)降低无效、错误数据对建模的影响,提高建模的准确性。
- 2)少量且具有代表性的数据将大幅缩减数据挖掘所需的时间。
- 3)降低储存数据的成本。
- 常用的归约:
- 属性归约
- 数值归约
属性归约
- 通过属性合并创建新属性维数,或通过直接删除不相关的属性来减少属性维数,从而提高数据挖掘的效率,降低计算成本。
- 属性归约的目标是寻找最小的属性子集并确保新数据自己的概率分布尽可能接近原来数据集的概率分布。
属性归约常用方法
| 属性归约方法 | 方法描述 | 方法解析 |
|---|---|---|
| 合并属性 | 将一些旧属性合并为新属性 | 初始属性集 {A1,A2,A3,A4,B1,B2,C} {A1,A2,A3,A4} ->A {B1,B2}->B =>归约后的属性集: {A,B,C} |
| 逐步向前选择 | 从一个空属性集开始,每次从原来属性 集合中选择一个当前最优的属性添加到 当前属性子集中。直到无法选出最优属性 或满足一定阈值结束为止。 | 初始属性集 {A1,A2,A3,A4,A5,A6} {}=>{A1}=>{A1,A4} =>归约后的属性集 {A1,A4,A6} |
| 逐步向后选择 | 从一个全属性集开始,每次从当前属性 集合中选择一个当前最差的属性并将其 从当前属性子集中剔除。直到无法选出最差 属性或满足一定阈值结束为止。 | 初始属性集 {A1,A2,A3,A4,A5,A6} =>{A1,A3,A4,A5,A6} =>{A1,A4,A5,A6} =>归约后的属性集 {A1,A4,A6} |
| 主成分分析 | 用较少的变量去解释原始数据中的大部分变量, 即将许多相关性很高的变量转化成彼此相互独立 或不相关的变量。 | |
| 决策树归纳 | 对原始数据做一个分类归纳学习,获得 一个初始的决策树,所有没有出现在这个 决策树上的属性均可以认为是无关属性, 因此,将这些属性从初始集合中删除 就可以获得一个较优的属性子集。 | 初始属性集 {A1,A2,A3,A4,A5,A6} =>归约后的属性集 {A1,A4,A6} |
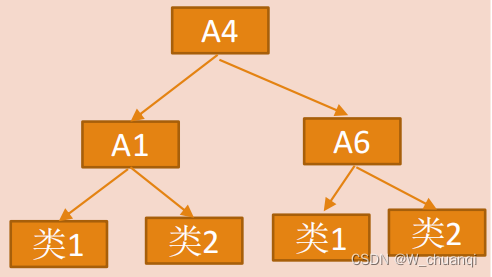
数值归约
通过选择替代的、较小的数据来减少数据量
- 有参数方法:使用一个模型来评估数据,只需存放参数,而不需要存放时机数据,如回归和对数线性模型。
- 无参数模型:需要存放实际数据,如直方图、聚类、抽样
Python主要数据预处理函数
Interpolate:数据插值 ——》缺失值 SciPy
Unique: 去除数据中的重复元素, pandas/numpy
Isnull: 判断是否空值 pandas
Notnull:判断是否非空值 pandas
PCA:对指标变量矩阵进行主成分分析 Scikit-learn
Random: 生成随机矩阵 Numpy
















 1374
1374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











