







#安装nltk等包直接用pip
#>>> 表示Python解释器正在等待输入
#Python IDLE Python本身计算器使用
#导入包和模块
from nltk.book import *#在提示符后输入名字直接找到文本
text1
sent1搜索文本
concordance函数,寻找上下文
>>> text1.concordance("monstrous")
Displaying 11 of 11 matches:
ong the former , one was of a most monstrous size . ... This came towards us ,
ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r
ll over with a heathenish array of monstrous clubs and spears . Some were thick
d as you gazed , and wondered what monstrous cannibal and savage could ever hav
that has survived the flood ; most monstrous and most mountainous ! That Himmal
they might scout at Moby Dick as a monstrous fable , or still worse and more de
th of Radney .'" CHAPTER 55 Of the Monstrous Pictures of Whales . I shall ere l
ing Scenes . In connexion with the monstrous pictures of whales , I am strongly
ere to enter upon those still more monstrous stories of them which are to be fo
ght have been rummaged out of this monstrous cabinet there is no telling . But
of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u#ALT+P 获取之前输入的命令,方便重复输入
similar函数 查找与搜索词有相似上下文的词
>>> text1.similar("monstrous")
true contemptible christian abundant few part mean careful puzzled
mystifying passing curious loving wise doleful gamesome singular
delightfully perilous fearlesscommon_contacts函数 搜索词共用两个或两个以上词汇的上下文
>>> text2.common_contexts(["monstrous", "very"])
a_pretty am_glad a_lucky is_pretty be_glad离散图 dispersion_plot
#需要包 Matplotlib 和 Numpy,用pip安装
>>>text4.dispersion_plot(['citizens', 'democracy', 'freedom', 'duties', 'America'])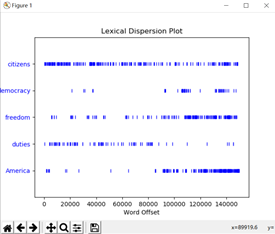
生成与某文本风格相似的随机文本,重复使用了源文本中常见的单词和短语
>>> text3.generate()获取文本长度
>>> len(text1)获取词汇表(删去重复)得出项目类型数而非词类型数
>>> set(text1)排序表 标点符号-大写-小写
>>>sorted(set(text1))词汇丰富度
>>> len(text3) / len(set(text3))计数一个单词在文本中出现的次数
>>>text3.count("smote")函数
text, count, total 是参数 形参 占位符
调用的时候传入实参
>>> def lexical_diversity(text):
return len(text) / len(set(text))
>>> def percentage(count, total):
return 100 * count / total链表 方括号表示
['Call' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









