






目录
划分训练集(trainning set)与检验集(test set)——train_test_split()函数
机器学习概念
机器学习是一门人工智能(AI)的分支,它让计算机能够通过数据学习并改进任务执行的能力,而无需进行显式的编程。简单来说,机器学习就像给计算机提供一个例子,然后让它自己找到解决问题的方法。
举个例子,假设你想要训练一个计算机识别猫咪的照片。你可以给计算机提供许多张不同猫咪的照片作为“训练数据”。计算机会分析这些照片,自己学会识别猫咪的特征,比如耳朵的形状、眼睛的位置等。一旦它学会了这些特征,你就可以让它看一些新的照片,它就能判断出这些照片里是否包含猫咪。
机器学习的关键在于“学习”这个词。计算机不是简单地执行我们告诉它的任务,而是通过数据自主地学习如何完成任务。这使得计算机能够适应新的情况,处理复杂的任务,甚至发现我们人类可能都没注意到的问题。
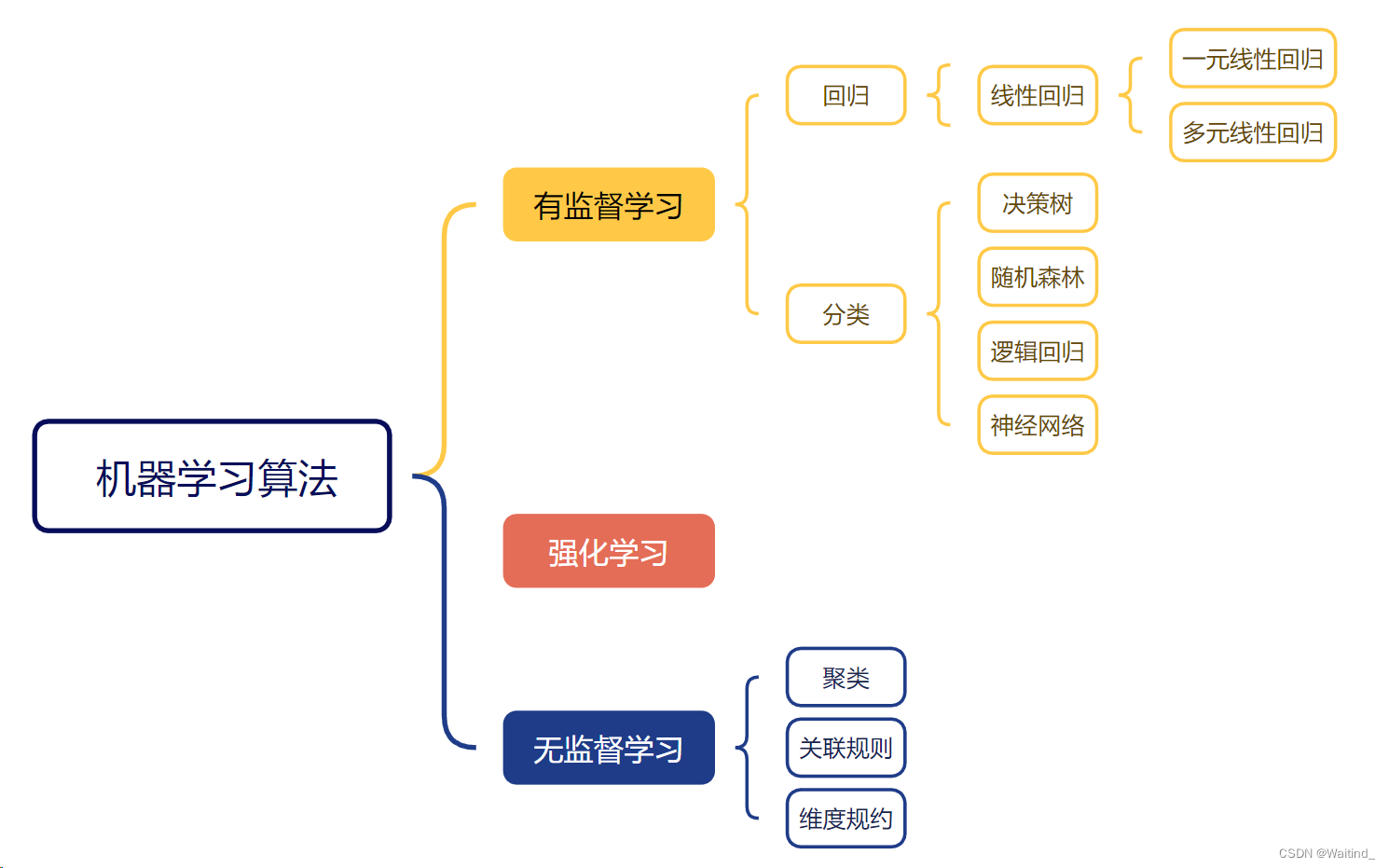
有监督学习和无监督学习
有监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)是机器学习的两种主要类型,它们在学习数据和目标上的方式有所不同。
有监督学习就像是一个老师指导学生的过程。在这个模式中,我们给计算机提供了一组带有正确答案的数据作为训练集。计算机通过分析这些数据,学习如何识别模式和特征,从而能够对新的、未见过的数据做出准确的预测或分类。比如,我们给计算机提供了一组关于不同水果的图片,并告诉它哪些是苹果,哪些是香蕉。计算机学会了之后,就能识别出新的水果图片中哪些是苹果。
无监督学习则更像是一个学生自己探索知识的过程。在这种情况下,计算机被给予的数据没有标签或正确的答案。计算机需要自己找出数据中的模式、关联性和结构。这种学习方式常用于数据挖掘和数据分析,目的是发现数据中的有趣趋势或关系。比如,计算机可能被给予一组匿名顾客购买行为的数据,它需要自己找出哪些商品经常一起购买。
简而言之,有监督学习是计算机在已知答案的情况下学习,而无监督学习是计算机在自己发现答案的情况下学习。
有监督学习
输入数据带有标签。
无监督学习
输入数据不带标签。
标签
在机器学习中,“标签”是指给数据添加的标记或注释,它们提供了关于数据的信息或数据的正确答案。标签是非常重要的,因为它们允许计算机知道它正在学习的是什么,并且可以用作评估计算机模型性能的标准。
以水果图片为例,标签可以是图片中水果的名称,比如“苹果”、“香蕉”或“橙子”。在分类问题中,标签用于告诉计算机每个数据样本属于哪个类别。在回归问题中,标签可能是数值,如水果的重量或价格。
在训练过程中,计算机使用带标签的数据来学习如何识别和预测新的数据样本的标签。一旦模型训练完成,它可以对未见过的数据进行预测,即对新图片进行“分类”或“预测”它们属于哪个类别。
标签的质量对机器学习的成功至关重要。如果标签不准确或不完整,计算机可能无法正确学习,导致性能不佳的模型。因此,在机器学习项目中,花时间确保标签的准确性和一致性是非常重要的。
加载内置小规模数据
| 小规模数据集 | ||
| 命令 | 数据描述 | 适合的方法 |
| load_boston() | 波士顿的房价数据 | 回归 |
| load_iris() | 鸢尾花(iris)数据集 | 分类 |
| load_diabetes() | 糖尿病(diabetes)数据集 | 回归 |
| load_digits() | 手写体数据集 | 分类 |
| load_linnerud() | 体能训练数据集 | 多元回归 |
| load_wine() | 酒类数据集 | 分类 |
| load_breast_cancer() | 威斯康星乳腺癌 | 分类 |
eg1:
from sklearn import datasets
iris = datasets.load_iris()
irisDf = pd.DataFrame(iris.data,columns=iris.feature_names)
irisDf['class'] = iris.target
irisDf.head()sklearn 是 scikit-learn机器学习算法库的常见别名
datasets 是 scikit-learn 中的一个模块,包含了多种预先加载的数据集。
eg2:
diabetes = datasets.load_diabetes()
diabetesDf = pd.DataFrame(diabetes.data,columns=diabetes.feature_names)
diabetesDf['target'] = diabetes.target
diabetesDf.head()加载内置大规模数据
| 命令 | 数据描述 | 适合的方法 |
| fetch_olivetti_faces() | Olivetti人脸识别数据 | 分类 |
| fetch_20newsgroups() | 包括20个话题的新闻文本数据 | 分类 |
| fetch_20newsgroups_vectorized() | 包括20个话题的新闻文本向量化数据 | 分类 |
| fetch_lfw_people() | 带标签的人脸识别数据 | 分类 |
| fetch_lfw_pairs() | 带标签的人脸识别数据 | 分类 |
| fetch_covtype() | 森林植被类型数据 | 分类 |
| fetch_rcv1() | 路透社英文新闻文本数据 | 分类 |
| fetch_kddcup99() | 网络入侵检测数据 | 分类 |
| fetch_california_housing() | 加利福尼亚房价数据 | 回归 |
eg1:
calh = datasets.fetch_california_housing()
calhDf = pd.DataFrame(calh.data,columns=calh.feature_names)
calhDf['HouseValue'] = calh.target
calhDf.head()sklearn 机器学习一般流程

建立有监督学习模型(如分类算法)的一般方法
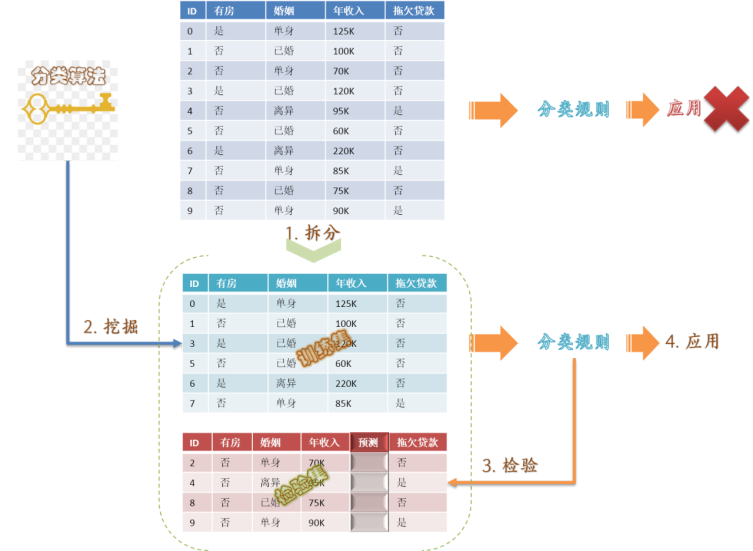
划分训练集(trainning set)与检验集(test set)——train_test_split()函数
在机器学习和数据分析中,特征数据和目标数据是两个基本概念:
特征数据(Feature Data):
特征数据通常是指用来描述数据样本特性的数据。在机器学习中,这些数据被用来作为模型输入,帮助模型学习和预测。
例如,如果我们要构建一个模型来预测房价,那么房价数据将是目标数据,而影响房价的其他因素,如房屋的大小、位置、年龄等,将是特征数据。
目标数据(Target Data):
目标数据,又称为标签数据,是指我们想要预测或解释的数据。在机器学习任务中,目标是模型试图预测的值。
若房价是我们想要预测的目标,则它是目标数据。
在实际应用中,特征数据和目标数据通常是一起提供的,例如在一个数据集中,特征数据可能包括身高、体重、年龄等,而目标数据则是健康状况或疾病诊断。在机器学习任务中,模型需要学习如何从特征数据中提取信息,并使用这些信息来预测或分类目标数据。
train_test_split()函数:
from sklearn.model_selection import train_test_split
trainX, testX, trainY, testY =
train_test_split(特征数据集X,目标数据集Y,test_size=0.25, random_state=None, shuffle=True)test_size :检验集的规模
可为float浮点数类型,取值范围 [0,1] ,表示检验集占原数据集的比例
可为int整数类型,表示检验集包含的数据记录的绝对数量
默认为0.25
random_state :随机数种子
整数,用于设置随机状态,以保证结果的可重复性。
每次调用函数时,只要 random_state 保持不变,结果都将保持一致。
shuffle :是否在分割之前对数据随机打乱,以确保训练集和测试集都是随机分布的
train_test_split()函数返回值为分割好的训练集与检验集,与输入的 *array 的类型相同、顺序相同















 1944
1944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









