






目录
随机森林与原始决策树、先剪枝决策树、后剪枝决策树关于ROC曲线的比较

分类模型的功能
- 描述性建模:识别哪些属性决定一个数据记录属于哪个类别
- 预测性建模:根据已知的数据记录的属性,自动识别该数据记录属于的类别
分类模型的适用领域
1.非常适合分类属性是二元或者标称类型(分类型)的数据集
2.不适用于分类属性是序数或连续类型的数据集,因为没有考虑标签之间的顺序大小关系
分类算法:
k最近邻分类
决策树
随机森林
朴素贝叶斯分类
逻辑回归
神经网络
支持向量机
决策树

决策树的sklearn实现
假设现有如下数据集
debt=[['是','否','否','是','否','否','是','否','否','否'],
['单身','已婚','单身','已婚','离异','已婚','离异','单身','已婚','单身'],
[125,100,70,120,95,60,220,85,75,90],
['否','否','否','否','是','否','否','是','否','是']]
debttrain = pd.DataFrame(debt, index=['有房者','婚姻状况','年收入','拖欠贷款']).T
debttrain .T 是DataFrame对象的转置操作,会将DataFrame进行转置,使得列变成新的行,行变成新的列。

将用于预测的标称属性转换成0-1二元属性
#df = pandas.get_dummies(data, columns=None)
debttrainOH = pd.get_dummies(debttrain, columns=['有房者','婚姻状况'])
debttrainOH
debttrainY = debttrainOH.pop('拖欠贷款') #pop方法用于移除列
debttrainYdebttrainOH如下图所示

debttrainY如下图所示

建立决策树模型
from sklearn import tree
dtDebt = tree.DecisionTreeClassifier(criterion='gini')这串代码建立了一个名为dtDebt的决策树模型
criterion : str 类型,不纯性的度量,可以是 gini 和 entropy ,默认是 gini
想象一下,你有一堆红色和蓝色的球,红色和蓝色的球混合在一起。如果你闭上眼睛随机拿一个球,你无法确定下一次拿到的球颜色是什么,因为红蓝球混合在一起,颜色不纯。现在,如果你把红球放在一边,蓝球放在另一边,那么每一边都是同一种颜色的球,这时你就说这堆球的颜色是纯的。
在决策树中,Gini系数就是用来衡量一堆数据“颜色”纯不纯的。如果数据集中的样本都是同一类,那么Gini系数就是0,表示数据纯;如果数据集中有不同类的样本混合在一起,Gini系数就会大于0,数值越高表示数据越不纯。
决策树在生长过程中,会在每个节点尝试根据不同的特征将数据分割成两部分,每次分割都会计算使用Gini系数来衡量分割后的数据纯度。然后选择一个能使得子集Gini系数最小的特征进行分割,这样分割后的子集就会更“纯”,也就是更接近于全部属于同一类的数据。通过不断这样的分割,决策树就能逐渐“理解”数据的结构,最终形成一个能够对新的数据进行分类的模型。
训练决策树模型——dt.fit(X,Y)
dtDebt.fit(debttrainOH, debttrainY)将决策树可视化
tree.plot_tree(decision_tree,max_depth=None,feature_names=None,
class_names= None,filled=False,ax=None)-
decision_tree: 这是你想要可视化的训练好的决策树模型。 -
max_depth: 这个参数指定了要绘制的树的最大深度。如果设置为None,整个树将会被绘制。 -
feature_names: 这是一个特征名称列表(字符串),它将被用来标记树中的节点。如果没有提供,特征名称将会根据训练数据的列名称自动生成。 -
class_names: 这是一个类名称列表(字符串),它将被用来标记树的叶子。如果没有提供,类名称将会根据训练数据中的唯一类自动生成。 -
filled: 这个参数指示是否根据它们的类值来着色节点的颜色。如果设置为True,叶子将被根据它们的类标签着色。 -
ax: 这个参数允许你指定绘制树的 matplotlib 轴对象。如果没有提供,将创建一个新的图形和轴。
figdt,axdt = plt.subplots(figsize=(25,15))
_ = tree.plot_tree(dtDebt,filled=True,feature_names=list(debttrainOH.columns),
class_names=dtDebt.classes_,ax=axdt)plt.subplots函数返回两个对象:figdt是一个Figure对象,它代表了整个图形,而axdt是一个Axes对象,它代表了图形中的一个轴,在这个例子中是一个子图。
- figdt:这个变量名通常代表"figure data",它存储了创建的图形对象。你可以通过这个对象来设置图形的整体属性,比如标题、坐标轴标签、legend等。
- axdt:这个变量名通常代表"axis data",它存储了图形中单个轴(在这个例子中是一个子图的轴)的对象。通过这个对象,你可以添加线条、散点、图像等,并进行各种设置,如设置轴的范围、添加图例、设置网格线等。
figsize=(25,15)是一个元组,指定了图形的大小。这里的尺寸是以英寸为单位的。所以,这个图形将被创建为宽25英寸、高15英寸。

预测
dtDebt.classes_classes_ 变量可能存储了这个决策树中所有节点的可能输出类别。
![]()
预测样本是否属于目标类别
预测类别是一个二元分类的输出(是或不是)
dtDebt.predict(debttestOH) ![]()
预测样本属于目标类别的具体概率
预测所属类别概率是一个具体的概率值,表示样本属于目标类别的可能性大小
dtDebt.predict_proba(debttestOH)
Titanic生存的决策树分类
读取数据
titRawDf = pd.read_csv('./data/analysis/train.csv')
titRawDf.head()
修改列名顺序和索引
titDf = titRawDf.loc[:,
['PassengerId','Pclass','Sex','Age','SibSp','Parch','Fare','Embarked','Survived']]
titDf.set_index('PassengerId',inplace=True)
titDf.head()
数据预处理
删除包含缺失值的行
titDf.dropna(axis=0,how='any',inplace=True)one-hot编码
titDf.dtypes
应将数据类型为object的属性转换成0-1二元属性
titX = titDf.iloc[:,:-1]
titY = titDf['Survived']
titX.head()
titXOH = pd.get_dummies(titX,columns=['Sex','Embarked'])
titXOH.head()
分割训练集与测试集

from sklearn.model_selection import train_test_split
titTrainX,titTestX,titTrainY,titTestY =
train_test_split(titXOH,titY,random_state=100)
建立决策树模型
titDt = tree.DecisionTreeClassifier(random_state=10)-
random_state=10:这是一个参数,用于指定分类器的随机状态。在决策树算法中,随机状态可以用来保证结果的可重复性。 -
当你设置
random_state为一个固定的数值(在这里是10)时,无论你在什么时候运行你的代码,只要其他参数不变,生成的决策树都是相同的。这在你需要复现实验结果时非常有用。
在训练集上训练决策树模型
titDt.fit(titTrainX,titTrainY)可视化决策树
figtit,axtit = plt.subplots(figsize=(20,15))
_ = tree.plot_tree(titDt,feature_names=list(titTrainX.columns),
class_names=['未生还','生还'],filled=True,ax=axtit,max_depth=3)Graphviz
Graphviz 是一个开源的图形可视化工具,它提供了一个简单的界面来将结构化数据转换成图形。它主要用于创建图表、网络、树、流程图等可视化图形,非常适合用于展示复杂的数据关系和结构。
tree.export_graphviz(decision_tree, feature_names=None,
class_names=None, filled=False)-
decision_tree:sklearn决策树模型对象 -
feature_names:这是一个列表,包含了特征列的名称。用于在可视化中显示特征名称 -
class_names:这是一个列表,包含了类标签的名称,用于在可视化中显示类标签的名称 -
filled:是否应该用不同的颜色填充决策树的节点,以表示不同的类别
!pip install graphviz #Python中安装Graphviz包
import graphviz
titDot = tree.export_graphviz(titDt,feature_names=list(titTrainX.columns),
class_names=['未生还','生还'],filled=True)titDtGraph = graphviz.Source(titDot)
titDtGraph 创建一个Source对象,该对象包含了一个由tree.export_graphviz函数生成的DOT源代码字符串,并将其存储在变量titDtGraph中
-
titDtGraph:这是一个变量名,用于存储创建的Source对象的引用。可以根据喜好来命名这个变量。 -
graphviz.Source:这是创建Source对象的方法。graphviz是graphviz库中的一个模块,而Source是该模块下的一个类。Source类用于表示一个DOT源文件,可以包含图形定义。 -
titDot:这是传递给Source构造器的DOT源代码字符串。这个字符串应该是一个有效的DOT格式的图形定义,通常是通过tree.export_graphviz函数生成的。
保存决策树图片
graph.render(filename=None, directory=None, cleanup=False, format=None)filename:保存的文件名称directory:保存的文件所在的路径cleanup:删除中间文件format:保存的图片格式,例如png,pdf
titDtGraph.render(filename='titDt',directory='./img/classification/',
cleanup=True,format='pdf')Titanic决策树模型在训练集上的分类性能的度量
混淆矩阵
- 由分类模型做出的正确和错误的分类结果构成的矩阵
- True Positive (TP):正确预测为正类P的样本数量。
- False Negative (FN):错误预测为负类N的样本数量。
- False Positive (FP):错误预测为正类P的样本数量。
- True Negative (TN):正确预测为负类N的样本数量。

混淆矩阵可以用来计算多种性能指标,例如:
- 准确率(Accuracy):(TP + TN) / (TP + TN + FP + FN)
- 召回率(Recall)或真正率(True Positive Rate):TP / (TP + FN)
- 精确率(Precision):TP / (TP + FP)
- F1分数(F1 Score):2 * (Precision精确率 * Recall召回率) / (Precision精确率 + Recall召回率)
- 假正率(False Positive Rate):FP / (FP + TN)
- P-R曲线(由精确率和召回率构成的图线,x轴为召回率,y轴为精确率)
-
ROC曲线(x轴是FPR假正率,y轴是TPR召回率或真正率)

绘制混淆矩阵
from sklearn import metrics
metrics.confusion_matrix(y_true, y_pred)
metrics.plot_confusion_matrix(estimator, X,y_true, values_format=None)y_pred:分类模型预测的类标签构成的数组estimator:训练好的分类器X:训练集中的预测属性y_true:真实类标签构成的数组,训练集中的目标标签value_formats:数字的显示格式
from sklearn import metrics
titTrainYPre = titDt.predict(titTrainX)
metrics.confusion_matrix(titTrainY, titTrainYPre)
metrics.plot_confusion_matrix(titDt,titTrainX,titTrainY,values_format='.0f')
计算准确率
metrics.accuracy_score(y_true, y_pred)metrics.accuracy_score(titTrainY,titTrainYPre) ![]()
计算召回率
metrics.recall_score(y_true, y_pred, pos_label=1) pos_label=1 表示我们将标签为1的实例作为正类。
print(f'未生还的分类的召回率是
{metrics.recall_score(titTrainY,titTrainYPre,pos_label=0)}')未生还的分类的召回率是0.5969230769230769
print(f'生还的分类的召回率是
{metrics.recall_score(titTrainY,titDt.predict(titTrainX),pos_label=1)}')生还的分类的召回率是0.9808612440191388
计算精确率
metrics.precision_score(y_true, y_pred, pos_label=1)print(f'未生还的分类的精确率是
{metrics.precision_score(titTrainY,titTrainYPre,pos_label=0)}')未生还的分类的精确率是0.9878419452887538
print(f'生还的分类的精确率是
{metrics.precision_score(titTrainY,titTrainYPre,pos_label=1)}')生还的分类的精确率是1.0
计算F1分数
metrics.f1_score(y_true, y_pred, pos_label=1)print(f'未生还的分类的F1_score是
{metrics.f1_score(titTrainY,titTrainYPre,pos_label=0)}')未生还的分类的F1_score是0.9938837920489296
print(f'生还的分类的F1_score是
{metrics.f1_score(titTrainY,titTrainYPre,pos_label=1)}')生还的分类的F1_score是0.9903381642512078
绘制P-R曲线图(x轴为召回率,y轴为精确率)
sklearn.metrics.plot_precision_recall_curve(estimator, X, y, pos_label)metrics.plot_precision_recall_curve(titDt,titTrainX,titTrainY,pos_label=0) 
AP:average precision score,PR曲线下围成的面积,越大越好
绘制ROC曲线图(x轴是FPR,y轴是TPR)
sklearn.metrics.plot_roc_curve(estimator, X, y, pos_label)metrics.plot_roc_curve(titDt,titTrainX,titTrainY,pos_label=0) 
AUC:area under curve,ROC曲线下面积,越大越好
Titanic决策树模型在检验集上的分类性能的度量
生成检验集的类别预测
titTestYPre = titDt.predict(titTestX)分类性能指标
print(f'对检验集的分类准确率是
{metrics.accuracy_score(titTestY,titTestYPre)}')
print(f'在检验集上未生还分类的召回率是
{metrics.recall_score(titTestY,titTestYPre,pos_label=0)}')
print(f'在检验集上生还分类的召回率是
{metrics.recall_score(titTestY,titTestYPre,pos_label=1)}')
print(f'在检验集上未生还分类的精确率是
{metrics.precision_score(titTestY,titTestYPre,pos_label=0)}')
print(f'在检验集上生还分类的精确率是
{metrics.precision_score(titTestY,titTestYPre,pos_label=1)}')
print(f'在检验集上未生还分类的F1_score是
{metrics.f1_score(titTestY,titTestYPre,pos_label=0)}')
print(f'在检验集上生还分类的F1_score是
{metrics.f1_score(titTestY,titTestYPre,pos_label=1)}')
#绘制P-R曲线
metrics.plot_precision_recall_curve(titDt,titTestX,titTestY)
#绘制ROC曲线
metrics.plot_roc_curve(titDt,titTestX,titTestY)Titanic决策树的剪枝
为什么需要剪枝?
生成的决策树过于复杂,对训练集的过度拟合
决策树算法没有考虑数据中存在噪声
过拟合: 想象一下,你是一名学生,正在学习一首新的诗歌。起初,你可能会注意诗歌的结构、韵律和每个词的意思。随着时间的推移,你开始注意到诗中的每一个标点符号、每个字的笔划甚至纸张的质感。你对这首诗的理解变得越来越细致,甚至能够背诵它。这时,你对这首诗的了解已经非常深入,几乎可以算得上是“过度”理解了。
在机器学习中,过拟合就像是你对诗歌的过度理解。模型在学习数据时,不仅学会了数据中的规律,还学到了其中的噪声和细节,这些在实际应用中并不重要。因此,当模型遇到新的、从未见过的数据时,它可能会表现得不太好,因为它把那些不必要的细节也当作了重要的特征。
数据中的噪声: 噪声就像是在你的学习材料中突然出现的一些无关的信息。想象一下,你正在准备考试,但是你的学习材料中混进了一些无关的、可能是错误的信息。这些信息可能会干扰你的学习,使你分心,导致你在考试中得不到好成绩。
在机器学习中,噪声就是数据集中的随机波动或者错误。这些噪声可能是由于测量错误、数据收集过程中的问题或者数据传输中的错误造成的。机器学习模型如果不能很好地处理这些噪声,就可能会学到错误的模式,导致在实际应用中表现不佳。
剪枝方法
先剪枝
后剪枝
想象一下,你正在培养一棵苹果树。在苹果树成长的过程中,你需要定期修剪树枝,以保证树木健康成长并结出好果实。
先剪枝(Pre-pruning): 这就像是在苹果树还很小的时候就开始修剪。你观察树的成长,并在树还年轻的时候去掉一些过长、过密的树枝。这样做可以让树木的资源集中在美国主干和主要分支上,有助于树木更健康地成长。
在机器学习中,先剪枝就是在模型还在训练的过程中,通过设定一些规则(比如树的最大深度或者节点最少样本数等),阻止模型过度复杂,避免它学习到太多的细节和噪声。
后剪枝(Post-pruning): 相反,后剪枝是在苹果树已经长大,长出很多枝条和叶子之后进行的修剪。这时,你可以更加仔细地评估每一根树枝是否有必要保留,是否对结出好果实有帮助。可能会发现一些虽然长得很好,但实际上并不结苹果的枝条,就可以把它们剪掉。
在机器学习中,后剪枝是在模型训练完成,生成了一个完整的模型之后,通过评估每个节点的性能,去除那些对预测任务没有实际帮助的部分,从而简化模型。
选择先剪枝还是后剪枝,通常取决于数据集的大小、复杂度以及计算资源的可用性。
对titanic决策树先剪枝
建立先剪枝的决策树模型
titDtForp = tree.DecisionTreeClassifier(max_depth=5,
min_samples_split=10,min_samples_leaf=10) max_depth:int类型或None,树的最大深度。推荐初始设置为3,先观察生成的决策树对数据的初步拟合状况,再决定是否要增加深度
min_samples_split:int类型或float类型,划分一个内部结点需要的最少的样本数量。
min_samples_leaf:int类型或float类型,每个叶结点需要包含的最少的样本数量。
训练模型
titDtForp.fit(titTrainX,titTrainY)可视化决策树
titDotForp = tree.export_graphviz(titDtForp,
feature_names=list(titTrainX.columns),class_names=['未生还','生还'],filled=True)
titDtForpGraph = graphviz.Source(titDotForp)
titDtForpGraph决策树在训练集上的性能
titTrainYPreForp = titDtForp.predict(titTrainX)
print(f'先剪枝的决策树在训练集上的F1_score是
{metrics.f1_score(titTrainY,titTrainYPreForp)}')
metrics.plot_roc_curve(titDtForp,titTrainX,titTrainY)先剪枝的决策树在训练集上的F1_score是0.787128712871287

在训练集上与未剪枝的决策树比较
titTrainDisp = metrics.plot_roc_curve(titDtForp,titTrainX,titTrainY,
label='forward-pruning')
metrics.plot_roc_curve(titDt,titTrainX,titTrainY,ax=titTrainDisp.ax_,
label='original')
# titTrainDisp.ax_:得到绘图的轴
决策树在检验集上的性能
titTestYPreForp = titDtForp.predict(titTestX)
print(f'先剪枝的决策树在训练集上的F1_score是
{metrics.f1_score(titTestY,titTestYPreForp)}')
metrics.plot_roc_curve(titDtForp,titTestX,titTestY)
在检验集上与未剪枝的决策树比较
titTestDisp = metrics.plot_roc_curve(titDtForp,titTestX,titTestY,
label='forward-pruning')
metrics.plot_roc_curve(titDt,titTestX,titTestY,ax=titTestDisp.ax_,
label='original')
# titTestDisp.ax_:获得绘图的轴
对titanic决策树后剪枝
建立后剪枝的决策树模型
titDtPostp = tree.DecisionTreeClassifier(ccp_alpha=0.035,random_state=10)训练决策树
titDtPostp.fit(titTrainX,titTrainY)
可视化决策树
titDotPostp = tree.export_graphviz(titDtPostp,
feature_names=list(titTrainX.columns),class_names=['未生还','生还'],
filled=True)
titDtPostpGraph = graphviz.Source(titDotPostp)
titDtPostpGraph在训练集上的分类性能
titTrainYPrePostp = titDtPostp.predict(titTrainX)
print(f'后剪枝的决策树在训练集上的F1_score是
{metrics.f1_score(titTrainY,titTrainYPrePostp)}')
titTrainDisp = metrics.plot_roc_curve(titDt,titTrainX,titTrainY,label='original')
metrics.plot_roc_curve(titDtForp,titTrainX,titTrainY,
label='forward-pruning',ax=titTrainDisp.ax_)
metrics.plot_roc_curve(titDtPostp,titTrainX,titTrainY,
label='post-pruning',ax=titTrainDisp.ax_)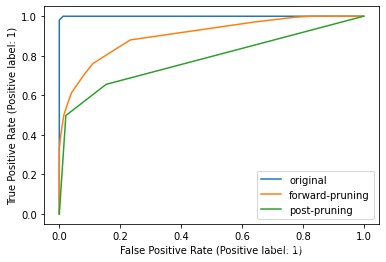
在检验集上的分类性能
titTestYPrePostp = titDtPostp.predict(titTestX)
print(f'后剪枝的决策树在检验集上的F1_score是
{metrics.f1_score(titTestY,titTestYPrePostp)}')
titTestDisp = metrics.plot_roc_curve(titDt,titTestX,titTestY,label='original')
metrics.plot_roc_curve(titDtForp,titTestX,titTestY,
label='forward-pruning',ax=titTestDisp.ax_)
metrics.plot_roc_curve(titDtPostp,titTestX,titTestY,
label='post-pruning',ax=titTestDisp.ax_)
Titanic的随机森林模型
想象一下你要去一个陌生的城市,你想要知道怎么到达一个特定的地方。你可以问很多当地人,每个当地人可能会给你一个不同的答案,有的可能会告诉你走这条路,有的可能会告诉你走那条路。如果只有很少的当地人给你答案,你可能会有一个不太准确的路线。但是,如果你问了很多人,综合起来,你可能会得到一个非常准确的路线。
随机森林就像这个情况。它是由很多棵决策树组成的,每棵决策树都是用来解决同一个问题的,但是每棵树都是在一个不同的数据集上训练的,就像你向不同的人询问路线。每棵树都会尝试找出最好的方式来预测结果,比如识别一张图片中的物体或者预测一个人的信用评分。然后,随机森林会综合所有树的结果,给出一个最终的预测。因为每棵树都是在一个不同的数据集上训练的,它们可能会找到不同的特征来预测结果,但是当它们一起工作时,就能给出一个更准确、更可靠的预测。
建立随机森林模型
from sklearn import ensemble
rbRandTree = ensemble.RandomForestClassifier(random_state=10)
rbRandTree.fit(titTrainX,titTrainY)训练集分类效果检验
rbRandTrainYPre = rbRandTree.predict(titTrainX)
metrics.accuracy_score(rbRandTrainYPre,titTrainY)
metrics.f1_score(rbRandTrainYPre,titTrainY,pos_label=1)
metrics.f1_score(rbRandTrainYPre,titTrainY,pos_label=0)检验集分类效果检验
rbRandTestYPre = rbRandTree.predict(titTestX)
metrics.accuracy_score(rbRandTestYPre,titTestY)
metrics.f1_score(rbRandTestYPre,titTestY,pos_label=1)
metrics.f1_score(rbRandTestYPre,titTestY,pos_label=0)随机森林与原始决策树、先剪枝决策树、后剪枝决策树关于ROC曲线的比较
randTreeDisp = metrics.plot_roc_curve(rbRandTree,titTestX,titTestY,
label='random forest')
metrics.plot_roc_curve(titDt,titTestX,titTestY,
label='original',ax=randTreeDisp.ax_)
metrics.plot_roc_curve(titDtForp,titTestX,titTestY,
label='forward pruning',ax=randTreeDisp.ax_)
metrics.plot_roc_curve(dts[40],titTestX,titTestY,
label='post pruning',ax=randTreeDisp.ax_)















 1969
1969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









