






 本文介绍了决策树的基本概念,包括ID3、C4.5/CART算法及其改进,重点展示了如何使用Python实现ID3算法和CART算法。同时,文中提及了信息增益、信息熵、增益率和基尼指数等关键指标。
本文介绍了决策树的基本概念,包括ID3、C4.5/CART算法及其改进,重点展示了如何使用Python实现ID3算法和CART算法。同时,文中提及了信息增益、信息熵、增益率和基尼指数等关键指标。
一、决策树定义
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别(在分类中)或一个实值(在回归中)。从根到叶节点的每条路径代表了一个分类规则。决策树学习的目的是为了产生一颗泛化能力强,即处理未见示例能力强的决策树。
二、构建决策树的三种方法
-
ID3算法:使用信息增益来选择划分属性。信息增益越大,则意味着使用该属性进行划分所获得的“纯度提升”越大。
- 信息熵公式:

- 信息增益公式:

- 信息熵公式:
-
C4.5算法:是ID3算法的改进,使用增益率来选择划分属性,以解决信息增益偏向于选择取值较多的属性的问题。
- 增益率公式:
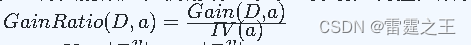
- 其中
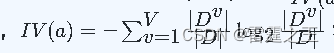 ,称为属性a的“固有值”。
,称为属性a的“固有值”。
- 增益率公式:
-
CART算法:既可以用于分类也可以用于回归。CART树是二叉树,内部节点特征的取值为“是”和“否”。对于分类问题,CART使用基尼指数来选择划分属性。
- 基尼指数公式:

- 基尼指数公式:
三、使用Python实现ID3和CART决策树
1.ID3算法实现
ID3算法主要步骤
-
选择最佳划分属性:
- 计算数据集中每个属性的信息增益。
- 选择信息增益最高的属性作为划分属性。
-
划分数据集:
- 根据选定的划分属性将数据集分成若干个子集,每个子集对应于划分属性的一个值。
-
递归构建子树:
- 对每个子集递归地执行步骤1和步骤2,直到满足停止条件(如所有样本属于同一类别、没有剩余属性或信息增益低于某个阈值)。
phyon代码实现ID3
import numpy as np
class Node:
def __init__(self, feature=None, threshold=None, left=None, right=None, *, value=None):
self.feature = feature
self.threshold = threshold
self.left = left
self.right = right
self.value = value
def is_leaf_node(self):
return self.value is not None
class ID3Classifier:
def __init__(self, min_samples_split=2, max_depth=100, n_feats=None):
self.min_samples_split = min_samples_split
self.max_depth = max_depth
self.n_feats = n_feats
self.root = None
def fit(self, X, y):
self.n_feats = X.shape[1] if not self.n_feats else min(self.n_feats, X.shape[1])
self.root = self._grow_tree(X, y)
def predict(self, X):
return np.array([self._traverse_tree(x, self.root) for x in X])
def _grow_tree(self, X, y, depth=0):
n_samples, n_features = X.shape
n_labels = len(np.unique(y))
# Stopping criteria
if (depth >= self.max_depth or n_labels == 1 or n_samples < self.min_samples_split):
leaf_value = self._most_common_label(y)
return Node(value=leaf_value)
feat_idxs = np.random.choice(n_features, self.n_feats, replace=False)
# Greedily select the best split according to information gain
best_feat, best_thresh = self._best_criteria(X, y, feat_idxs)
# Grow the children that result from the split
left_idxs, right_idxs = self._split(X[:, best_feat], best_thresh)
left = self._grow_tree(X[left_idxs, :], y[left_idxs], depth+1)
right = self._grow_tree(X[right_idxs, :], y[right_idxs], depth+1)
return Node(best_feat, best_thresh, left, right)
def _best_criteria(self, X, y, feat_idxs):
best_gain = -1
split_idx, split_thresh = None, None
for feat_idx in feat_idxs:
X_column = X[:, feat_idx]
thresholds = np.unique(X_column)
for threshold in thresholds:
gain = self._information_gain(y, X_column, threshold)
if gain > best_gain:
best_gain = gain
split_idx = feat_idx
split_thresh = threshold
return split_idx, split_thresh
def _information_gain(self, y, X_column, split_thresh):
# Parent loss
parent_entropy = self._entropy(y)
# Generate split
left_idxs, right_idxs = self._split(X_column, split_thresh)
if len(left_idxs) == 0 or len(right_idxs) == 0:
return 0
# Compute the weighted avg. of the loss for the2.测试数据集结果。为了完整性,我们需要实现_most_common_label, _entropy, 和 _split 方法,以及数据集来测试代码。以下是一个补全后的版本,并附带一个简单的数据集进行测试:
import numpy as np
class Node:
# ...(类定义如上所示)
class ID3Classifier:
# ...(类定义如上所示)
def _most_common_label(self, y):
counter = np.bincount(y)
most_common = np.argmax(counter)
return most_common
def _entropy(self, y):
_, counts = np.unique(y, return_counts=True)
probabilities = counts / counts.sum()
entropy = sum(probabilities * -np.log2(probabilities))
return entropy
def _split(self, X_column, split_thresh):
left_idxs = np.argwhere(X_column <= split_thresh).flatten()
right_idxs = np.argwhere(X_column > split_thresh).flatten()
return left_idxs, right_idxs
# 创建一个简单的数据集
X = np.array([
[1, 0],
[1, 1],
[0, 0],
[0, 1],
[1, 0],
[0, 0],
[1, 1],
[0, 1],
[1, 0],
[1, 1]
])
y = np.array([0, 0, 1, 1, 0, 1, 0, 1, 1, 0]) # 二分类问题:0 和 1CART算法创建决策树
在Python中,使用CART(Classification and Regression Trees)算法创建决策树通常涉及使用现成的机器学习库,如scikit-learn。scikit-learn提供了DecisionTreeClassifier类,该类默认使用CART算法来构建决策树。 下面是一个使用scikit-learn的DecisionTreeClassifier来基于给定数据集创建决策树的示例:
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 给定的数据集
X = np.array([
[1, 0],
[1, 1],
[0, 0],
[0, 1],
[1, 0],
[0, 0],
[1, 1],
[0, 1],
[1, 0],
[1, 1]
])
y = np.array([0, 0, 1, 1, 0, 1, 0, 1, 1, 0])
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建CART决策树分类器
clf = DecisionTreeClassifier(criterion='gini', random_state=42)
# 训练决策树
clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
# 可视化决策树(需要安装graphviz库和pydotplus库)
# 注意:这部分代码在某些环境中可能无法运行,因为它依赖于系统级别的Graphviz工具
from sklearn.tree import export_graphviz
import pydotplus
dot_data = export_graphviz(clf, out_file=None,
feature_names=['feature_1', 'feature_2'],
class_names=['class_0', 'class_1'],
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_png('decision_tree.png')















 8619
8619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









