







机器学习基础算法
机器学习基础
线性模型
决策树
朴素贝叶斯
SVM
集成学习(Boosting、随机森林)
一、机器学习概述
1、机器学习
定义: 假设用 P 来评估计算机程序在某任务类 T 上的性能,若一个程序通过利用经验 E 在 T 中任务上获得了性能改善,则我们就说关于 T 和 P,该程序对 E 进行了学习。
术语:
- 示例(instance)/ 样本(sample): 一个对象。
- 数据集(data set):一组对象的集合。
- 属性(attribute)/ 特征(feature):对象在某方面的表现或性质的事项。
- 属性值 / 特征值:对象的属性/特征的取值。
- 样本空间(sample space):属性张成的空间,空间大小=各属性可能取值个数的乘积。
- 假设空间(hypothesis):各属性的可能取值的组合,各属性的取值可能为 *(通配),空集也是一种可能的取值组合。
- 泛化(generalization): 学得的模型适用于新样本的能力。
- 监督学习(supervised learning):训练样本有标记,分类和回归。
- 无监督学习(unsupervised learning):训练样本无标记,聚类。
可以把学习的过程看作一个在假设空间进行搜索的过程,搜索的目标是找到与训练集匹配(fit)的假设。可能存在多个匹配的假设,称为版本空间(version space)。根据归纳偏好(尽可能特殊 / 尽可能一般)选择符合的假设作为模型。
2、模型评估与选择
过拟合与欠拟合:有学习算法和数据内涵共同决定
- 过拟合:算法学习能力强,数据量/特征少,把个别样本的特征总结为数据集的普遍规律,泛化性能差。
- 欠拟合:算法学习能力差,数据量/特征多,学习到的规律过于普遍,训练集的预测结果差。
评估方法:训练集、验证集
- 留出法:把数据集拆分成训练集、验证集
- 自助法:有放回的随机采样
- 交叉验证法:

调参和最终模型:
- 调参:网络搜索,或者用指数法不断缩小调参的范围。
- 最终模型:划分测试集,在验证集上对不同模型进行评估选出最优的,然后在测试集上测试最终模型的性能。
偏差与方差:
- 偏差:度量学习算法的期望预测与真实结果的偏离程度,即拟合能力。偏差大钱拟合。
- 方差:度量同样大小的训练集的变动所导致的学习性能的变化,即数据扰动所造成的影响。方差大过拟合。
- 偏差和方差是冲突的。
二、线性模型
1、基本形式

2、线性回归(linear regression)




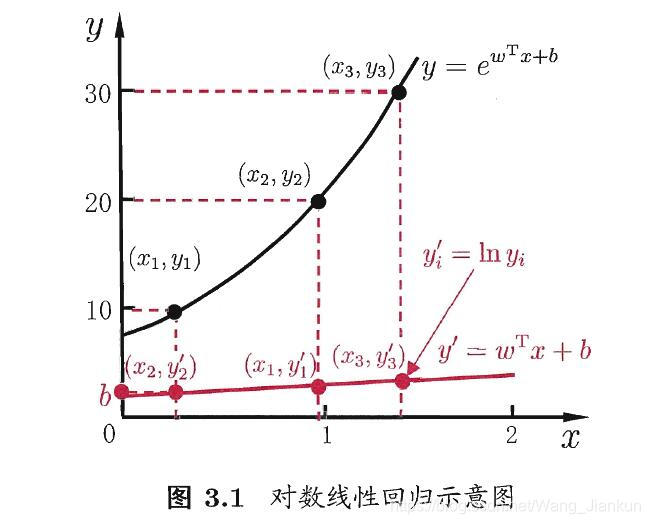
3、逻辑回归(logistic regression)
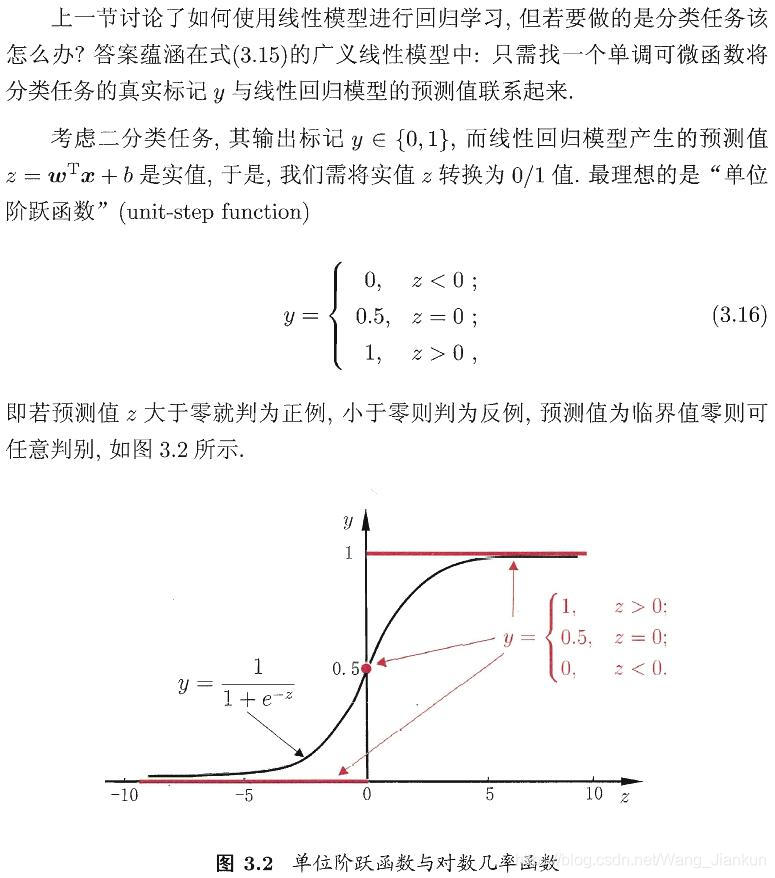


4、多分类


5、样本不平衡



三、决策树(Decision Tree)
1、决策树算法


2、信息熵(ID3、C4.5)



3、基尼系数

4、剪枝


四、朴素贝叶斯(Navie Bayes)


五、SVM
1、SVM基本型
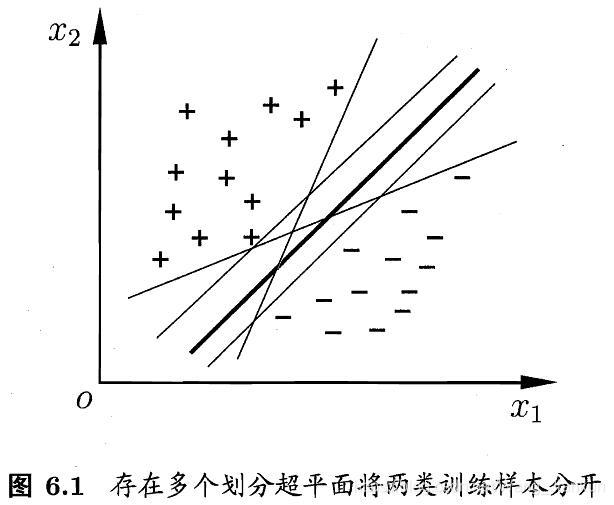
基于训练集 D 在样本空间中找到一个划分超平面,将不同类别的样本分开,这样的超平面可能有很多。SVM 功能是找到那个对训练样本局部扰动的容忍性最好的那个超平面,即划分超平面产生的分类结果最鲁棒,泛化能力最强。


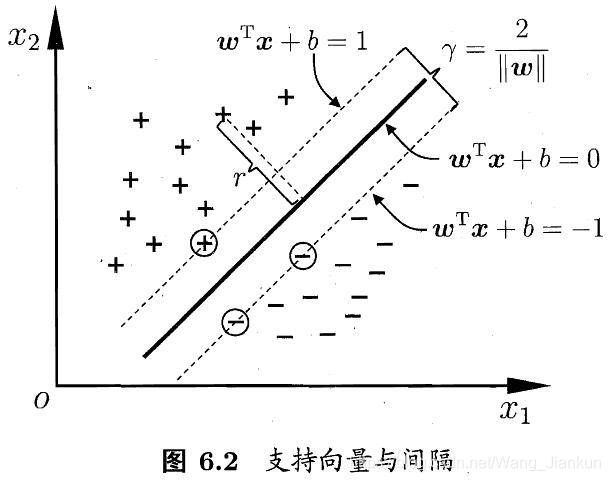


2、核函数
现实任务中,训练样本不一定是线性可分的(即一个划分超平面能将训练样本正确分类),通常是线性不可分。对于这样的问题,可将样本从原始空间映射到一个更高维的特征空间,使得样本在新的特征空间内线性可分。如果原始空间是有限维的(属性有限),那么一定存在一个高维特征空间使样本可分。




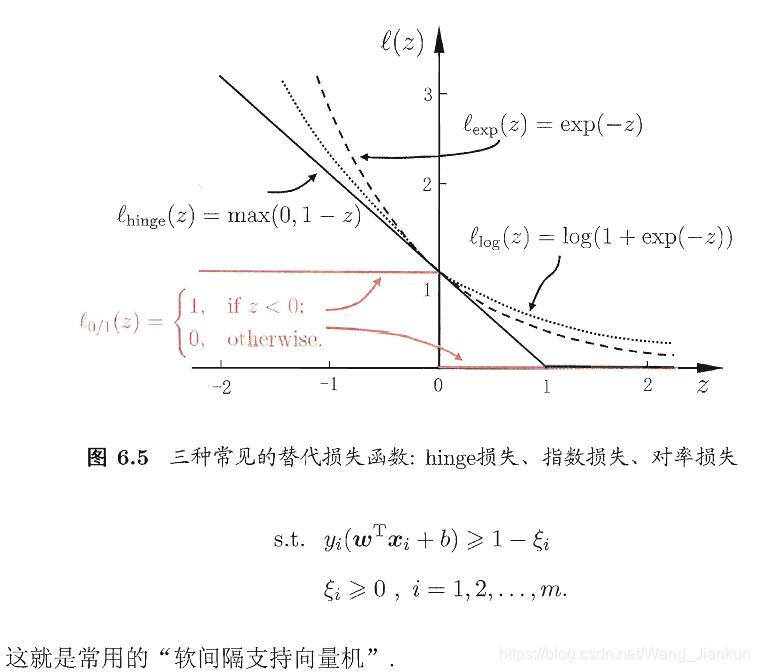
3、软间隔和正则化
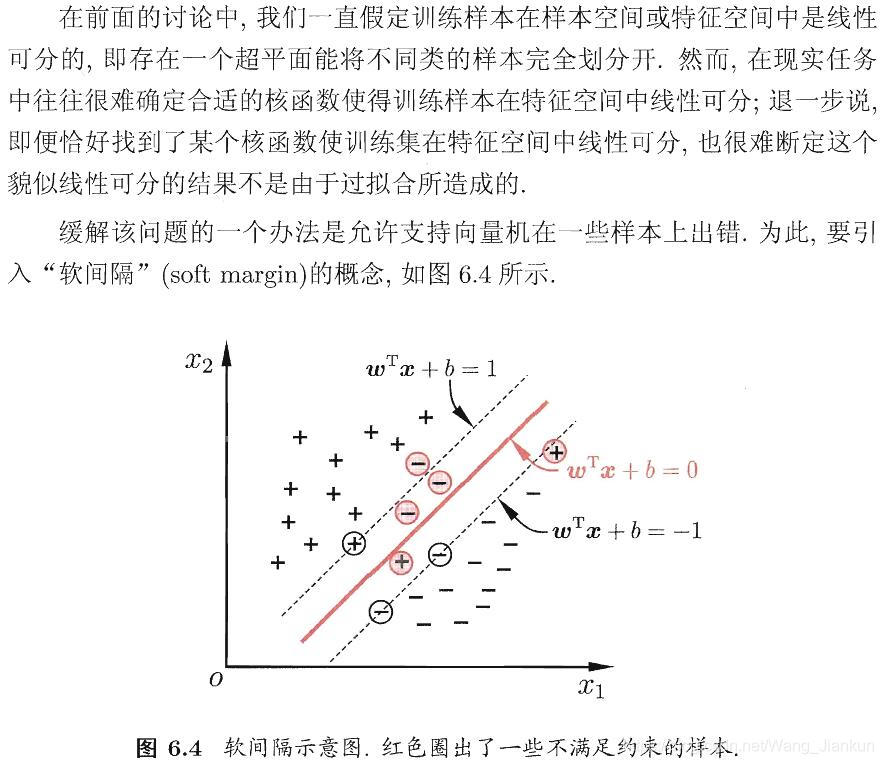
所有样本都必须划分正确,这称为硬间隔(hard margin),而软间隔则是允许某些样本不满足约束条件:


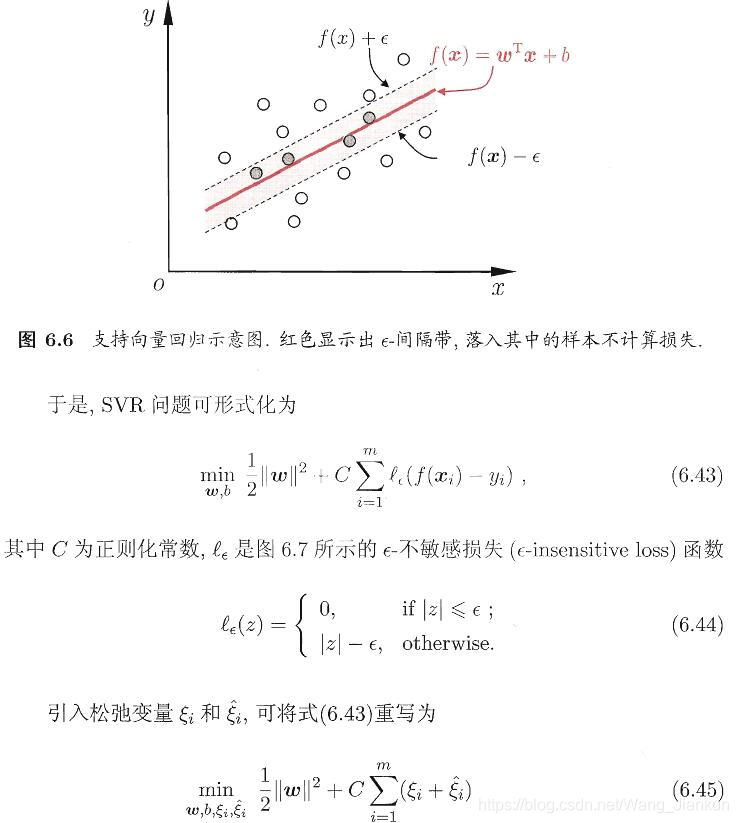
4、SVR

六、集成学习
1、个体与集成

弱学习器的性能应好于随机预测,通常使用的是较强的弱学习器。

2、Boosting

- 根据上一轮各样本的预测情况调整该轮各样本的权重,上一轮分错的样本权重加大
- 根据该弱学习器的预测效果分配最后预测的权重,预测效果越好权重越大
3、Bagging

- 采样剩余的36.8%的样本可用来做验证集对弱学习器的泛化性能进行估计。
4、随机森林


- 样本哟放回的随机采样
- 从决策树每个节点的属性集合随机选择 k 个
5、结合策略
数值型输出:
- 平均法:各个弱学习器的权重一样,对结果进行简单的平均
- 加权平均法:各个弱学习器的权重不一样,对结果进行加权平均
分类任务:
- 绝对多数投票法:任一类的得票超过半数则预测为该类,否则拒绝预测
- 相对多数投票法:预测为得票最多的类别
- 加权投票法:弱学习器的分类结果进行加权投票
学习法:
通过另一个学习器来学习如何结合,代表算法是Stacking。

GOOD LUCK!

















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









