






线上故障主要会包括 CPU、磁盘、内存以及网络问题,而大多数故障可能会包含不止一个层面的问题,所以进行排查时候尽量四个方面依次排查一遍。同时例如 jstack、jmap 等工具也是不囿于一个方面的问题的,基本上出问题就是 df、free、top 三连,然后依次 jstack、jmap 伺候,具体问题具体分析即可。
cpu:
一般来讲我们首先会排查 CPU 方面的问题。CPU 异常往往还是比较好定位的。原因包括业务逻辑问题(死循环)、频繁 gc 以及上下文切换过多。而最常见的往往是业务逻辑(或者框架逻辑)导致的,可以使用 jstack 来分析对应的堆栈情况。
使用 jstack 分析 CPU 问题
我们先用 ps 命令找到对应进程的 pid(如果你有好几个目标进程,可以先用 top 看一下哪个占用比较高)。
接着用top -H -p pid来找到 CPU 使用率比较高的一些线程
步骤:
1、找到 cpu 占有率最高的 java 进程号
使用命令: top -c 显示运行中的进程列表信息, shift + p 使列表按 cpu 使用率排序显示
PID = xxxx 的进程,cpu 使用率最高
2、根据进程号找到 cpu 占有率最高的线程号
使用命令: top -Hp {pid} ,同样 shift + p 可按 cpu 使用率对线程列表进行排序
十进制的 xxxx转成十六进制 xxxx
Jstack -l PID >> 123.txt 导出到本地
根据二进制编号对应文件,分析到开发代码层
然后将占用最高的 pid 转换为 16 进制printf '%x\n' pid得到 nid
接着直接在 jstack 中找到相应的堆栈信息jstack pid |grep 'nid' -C5 –color
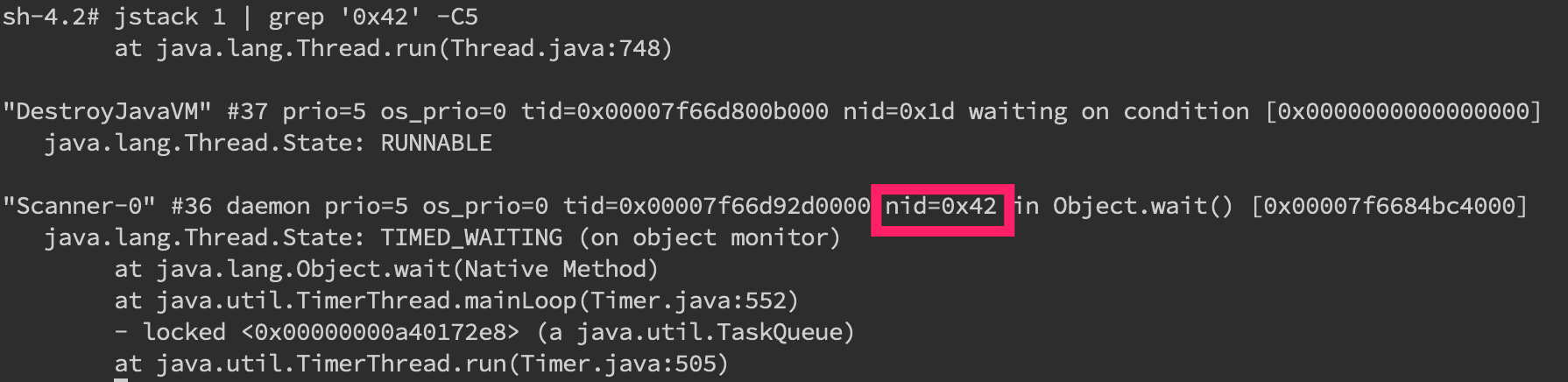
可以看到我们已经找到了 nid 为 0x42 的堆栈信息,接着只要仔细分析一番即可。
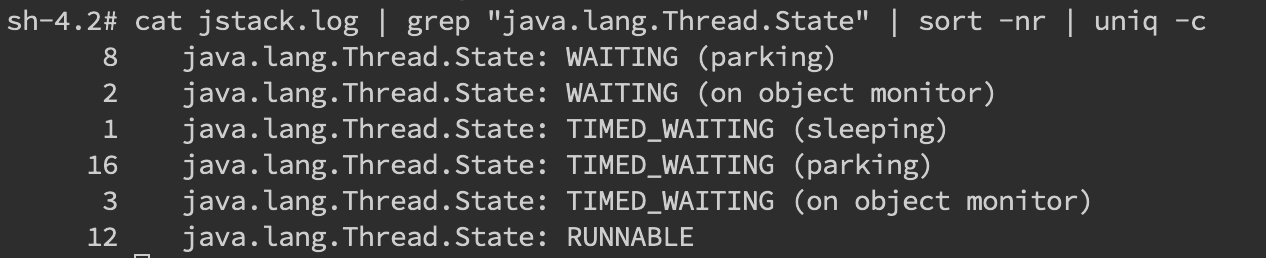
当然更常见的是我们对整个 jstack 文件进行分析,通常我们会比较关注 WAITING 和 TIMED_WAITING 的部分,BLOCKED 就不用说了。我们可以使用命令cat jstack.log | grep "java.lang.Thread.State" | sort -nr | uniq -c来对 jstack 的状态有一个整体的把握,如果 WAITING 之类的特别多,那么多半是有问题啦。
频繁 gc
当然我们还是会使用 jstack 来分析问题,但有时候我们可以先确定下 gc 是不是太频繁,使用jstat -gc pid 1000命令来对 gc 分代变化情况进行观察,1000 表示采样间隔(ms),S0C/S1C、S0U/S1U、EC/EU、OC/OU、MC/MU 分别代表两个 Survivor 区、Eden 区、老年代、元数据区的容量和使用量。YGC/YGT、FGC/FGCT、GCT 则代表 YoungGc、FullGc 的耗时和次数以及总耗时。如果看到 gc 比较频繁,再针对 gc 方面做进一步分析
针对频繁上下文问题,我们可以使用vmstat命令来进行查看
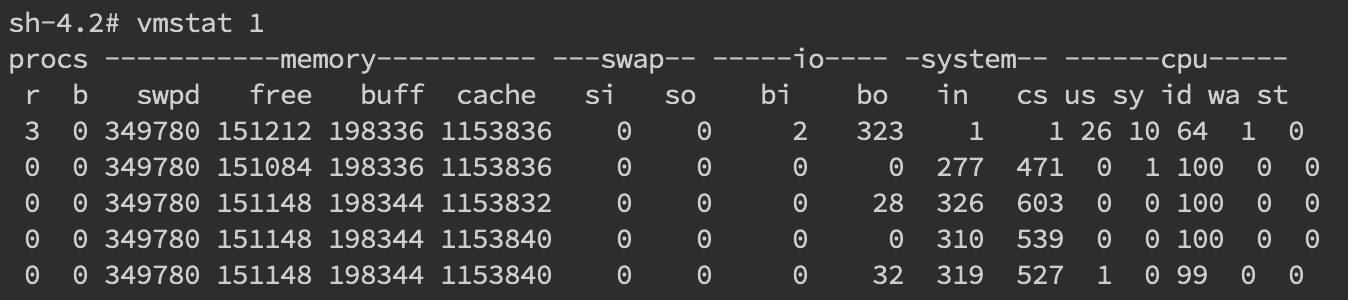
cs(context switch)一列则代表了上下文切换的次数。
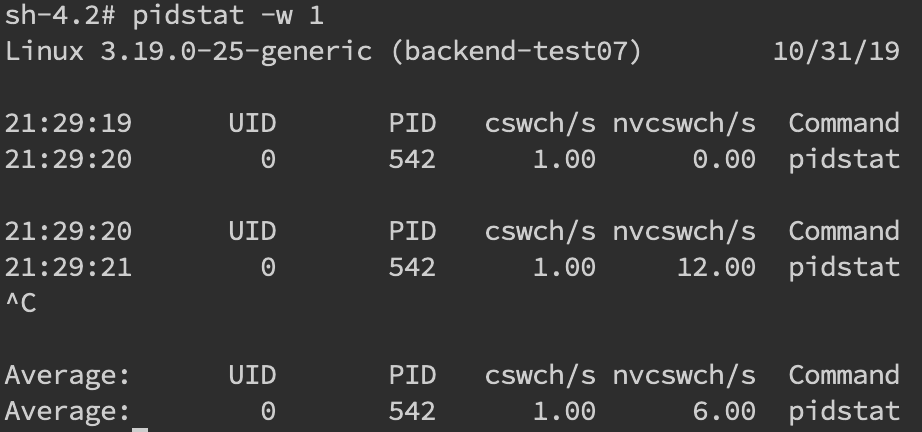
如果我们希望对特定的 pid 进行监控那么可以使用 pidstat -w pid命令,cswch 和 nvcswch 表示自愿及非自愿切换。
磁盘:
磁盘问题和 CPU 一样是属于比较基础的。首先是磁盘空间方面,我们直接使用df -hl来查看文件系统状态

更多时候,磁盘问题还是性能上的问题。我们可以通过 iostatiostat -d -k -x来进行分析
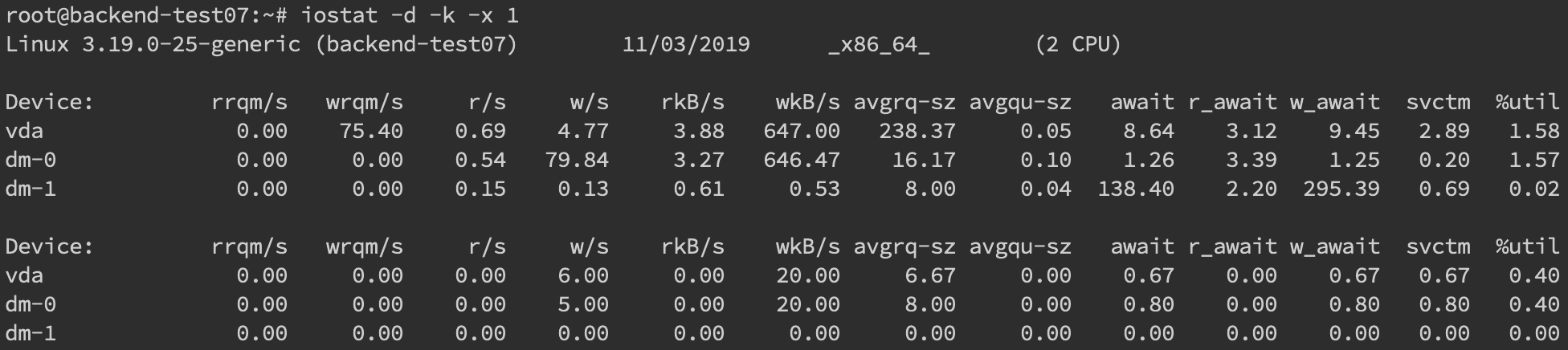
最后一列%util可以看到每块磁盘写入的程度,而rrqpm/s以及wrqm/s分别表示读写速度,一般就能帮助定位到具体哪块磁盘出现问题了。
另外我们还需要知道是哪个进程在进行读写,一般来说开发自己心里有数,或者用 iotop 命令来进行定位文件读写的来源。
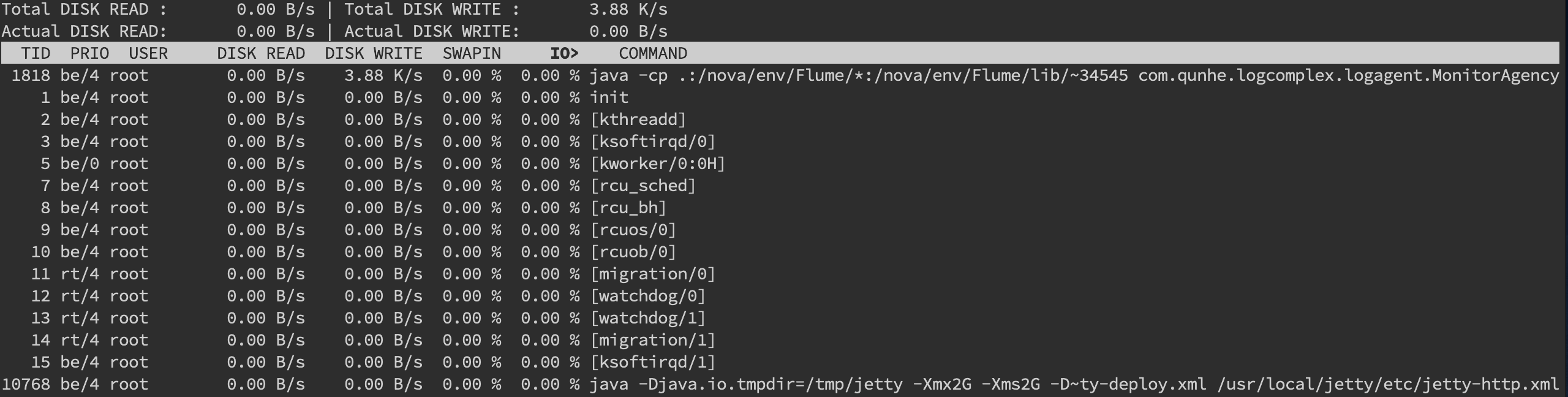
不过这边拿到的是 tid,我们要转换成 pid,可以通过 readlink 来找到 pidreadlink -f /proc/*/task/tid/../..。

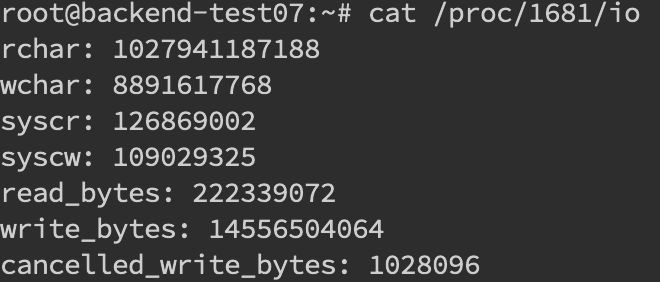
找到 pid 之后就可以看这个进程具体的读写情况cat /proc/pid/io
我们还可以通过 lsof 命令来确定具体的文件读写情况lsof -p pid
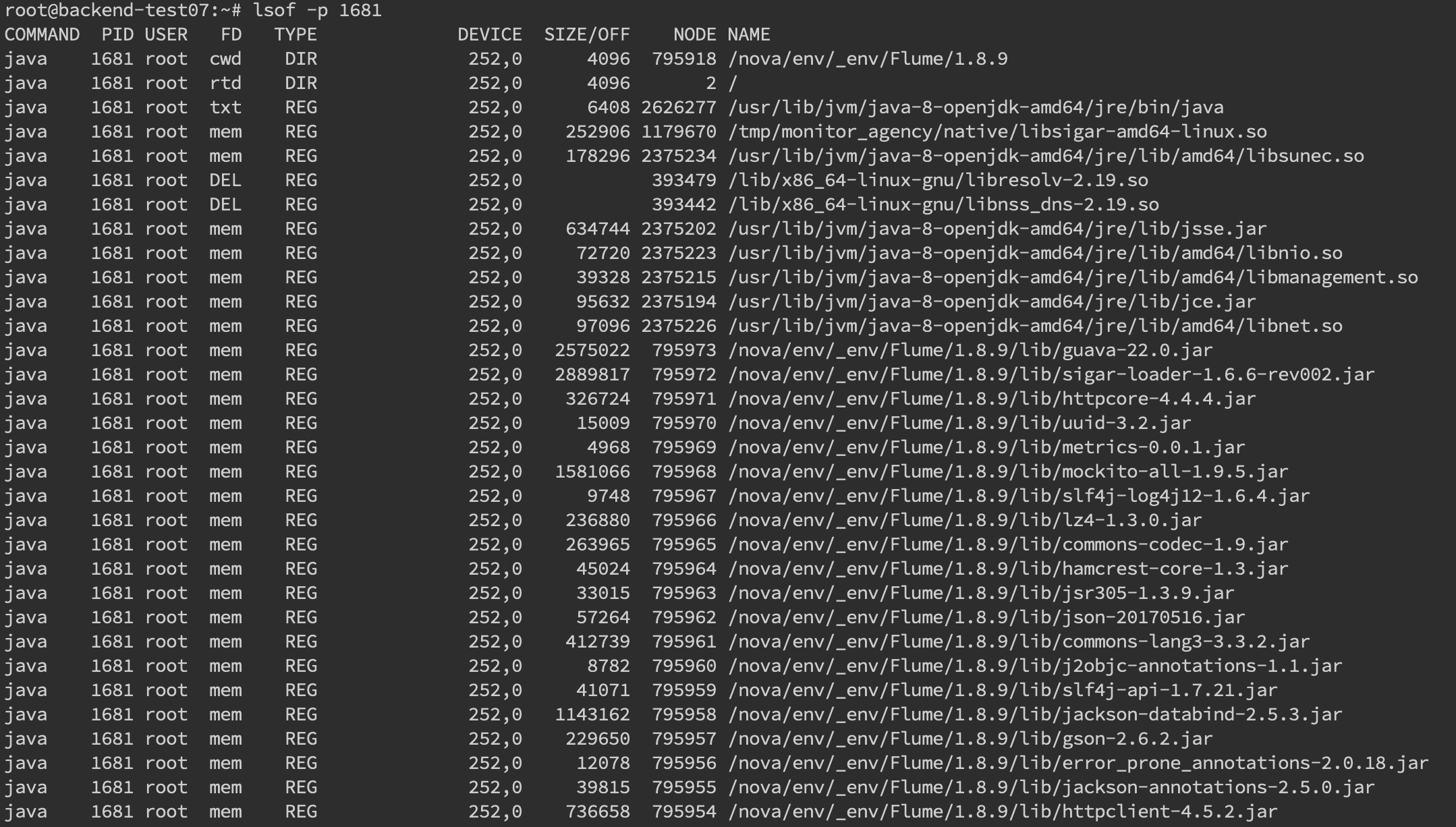
内存:
1、找到内存占有率最高的进程号
使用命令: top -c 显示运行中的进程列表信息, shift + m 按内存使用率进行排序
2、利用 jmap 生成堆转储快照
命令: jmap -dump:format=b,file={path} {pid}
3、利用 MAT 分析堆转储快照
GC:
堆内内存泄漏总是和 GC 异常相伴。不过 GC 问题不只是和内存问题相关,还有可能引起 CPU 负载、网络问题等系列并发症,只是相对来说和内存联系紧密些,所以我们在此单独总结一下 GC 相关问题。
常见 的 Young GC、Full GC
针对 gc 日志,我们就能大致推断出 youngGC 与 fullGC 是否过于频繁或者耗时过长,从而对症下药。我们下面将对 G1 垃圾收集器来做分析,这边也建议大家使用 G1-XX:+UseG1GC。
java8之前很多都是使用CMS算法,不做论述
youngGC 过频繁
youngGC 频繁一般是短周期小对象较多,先考虑是不是 Eden 区/新生代设置的太小了,看能否通过调整-Xmn、-XX:SurvivorRatio 等参数设置来解决问题。如果参数正常,但是 young gc 频率还是太高,就需要使用 Jmap 和 MAT 对 dump 文件进行进一步排查了。
youngGC 耗时过长
耗时过长问题就要看 GC 日志里耗时耗在哪一块了。以 G1 日志为例,可以关注 Root Scanning、Object Copy、Ref Proc 等阶段。Ref Proc 耗时长,就要注意引用相关的对象。Root Scanning 耗时长,就要注意线程数、跨代引用。Object Copy 则需要关注对象生存周期。而且耗时分析它需要横向比较,就是和其他项目或者正常时间段的耗时比较。比如说图中的 Root Scanning 和正常时间段比增长较多,那就是起的线程太多了。

触发 fullGC
G1 中更多的还是 mixedGC,但 mixedGC 可以和 youngGC 思路一样去排查。触发 fullGC 了一般都会有问题,G1 会退化使用 Serial 收集器来完成垃圾的清理工作,暂停时长达到秒级别,可以说是半跪了。
fullGC 的原因可能包括以下这些,以及参数调整方面的一些思路:
- 并发阶段失败:在并发标记阶段,MixGC 之前老年代就被填满了,那么这时候 G1 就会放弃标记周期。这种情况,可能就需要增加堆大小,或者调整并发标记线程数-XX:ConcGCThreads。
- 晋升失败:在 GC 的时候没有足够的内存供存活/晋升对象使用,所以触发了 Full GC。这时候可以通过-XX:G1ReservePercent来增加预留内存百分比,减少-XX:InitiatingHeapOccupancyPercent来提前启动标记,-XX:ConcGCThreads来增加标记线程数也是可以的。
- 大对象分配失败:大对象找不到合适的 region 空间进行分配,就会进行 fullGC,这种情况下可以增大内存或者增大-XX:G1HeapRegionSize。
- 程序主动执行 System.gc():不要随便写就对了。
另外,我们可以在启动参数中配置-XX:HeapDumpPath=/xxx/dump.hprof来 dump fullGC 相关的文件,并通过 jinfo 来进行 gc 前后的 dump
jinfo -flag +HeapDumpBeforeFullGC pid
jinfo -flag +HeapDumpAfterFullGC pid
jinfo -flag +HeapDumpBeforeFullGC pid
jinfo -flag +HeapDumpAfterFullGC pid
这样得到 2 份 dump 文件,对比后主要关注被 gc 掉的问题对象来定位问题。
网络:
web层在论述















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









