







堆排序算法
简介:堆是一棵完全二叉树,其中每个节点的值都大于等于(或小于等于)其左右子节点的值。堆分为最大堆和最小堆两种,最大堆的根节点是整个堆中的最大值,最小堆的根节点是整个堆中的最小值。
在堆排序中,首先将待排序的数据组织成一个二叉堆。然后,取出堆顶元素,将其与堆底最后一个元素交换位置,并将堆的大小减1。接着将堆顶元素下沉,使得剩余元素重新组成一个堆。重复上述操作,即可完成排序。
堆排序具有良好的时间复杂度,最坏时间复杂度为O(nlogn),空间复杂度为O(1)。相比其他排序算法,堆排序在大数据量时表现更优秀。
一. 基础知识
-
最大堆的定义:一个大小为n的堆是一颗包含n个结点的完全二叉树,树中的每个结点的关键字值大于等于其双亲结点的关键字值。(最小堆则是小于等于其双亲结点关键字值)
当这颗完全二叉树以顺序对方式存储时,事实上排成了结点序列( k 0 k_0 k0, k 1 k_1 k1, k 2 k_2 k2, k 3 k_3 k3 ,…, k n − 1 {k_{n-1}} kn−1)。
所以最大堆中元素的关系:k[i]>=k[2i+1] && k[i] >=k[2i+2] -
堆排序思想
- 将初始序列构成最大顶堆,则heap[0]为最大元素
- 将堆顶元素heap[0]与最后一个元素交换,此时得到新的序列(heap[0],heap[1],heap[2],…heap[n-2]),heap[n-1]。其中heap[n-1]为最大元素,将不参与新的建堆过程
- 由于交换元素后,原序列将不满足堆性质,对上步生成的n-1个元素重新进行建堆过程,即重复(1),(2).
-
建堆与排序图解
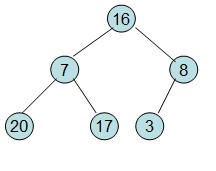




参考:建堆图解
二. 算法实现
#include <stdio.h>
#include <iostream>
using namespace std;
void create_heap(int *heap,int n);
void adjust_down(int *heap,int r,int n);
int main()
{
int arr[] = {16,7,3,20,17,8,13};
int size = 7;
while(size>1) {
create_heap(arr,size);
int temp = arr[size-1];
arr[size-1] = arr[0];
arr[0] = temp;
size--;
}
for(int i =0;i<7;i++)
cout << arr[i] << " ";
cout << endl;
return 0;
}
// n is upper index
void adjust_down(int *heap, int r, int n)
{
int child = 2*r + 1;
int temp = heap[r];
while (child <= n) {
if((child<n) && (heap[child+1] > heap[child])) child++;
if(temp>heap[child]) break;
heap[(child-1)/2] = heap[child];
child = 2 * child + 1;
}
heap[(child-1)/2] = temp;
}
void create_heap(int *heap,int n)
{
for(int i=(n-1)/2;i>-1;i--)
{
adjust_down(heap, i, n-1);
}
}
三.注意的问题
-
建堆过程中,heap[(child-1)/2] = heap[child],这一句我开始理解为heap[r]=heap[child],其实这样是不对的,因为建堆过程中,有向下调整的过程,临时值temp = heap[r]并不是简单的和第一代子结点交换就行,而是一直向下调整,直到合适的位置
-
create_heap函数中的n代表的是最大索引,而不是关键字个数
-
每次建堆都要用到下调堆结构函数,索引i的子代结点的索引为
2*i+1, 2*i+2















 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









