







已经研究了一段时间的hadoop了,由于最近事情实在太多,完全抽不出时间来整理资料,今天总算有时间了,整理下资料,也算对这段时间的总结吧。在这互联网时代,大数据的发展已经是势不可挡,顺应时代潮流,冲进互联网风口,研究hadoop也让我心情澎湃.详细的说下hadoop的环境搭建,因为这个过程中对初学者来说是会出现各种各样的问题:
首先说下正确的搭建方式,然后在说下我们团队在搭建环境中出现的各种问题以及解决方案:
1. 创建好对应的hadoop用户和hadoop组
把这个步骤放在第一位是因为为了方便管理,因为到时候的hadoop解压后的文件就是放在hadoop用户下的hadoop组下,所以jdk也是要属于hadoop用户,详细的命令:
sudo addgroup hadoop //创建hadoop组
sudo adduser -ingroup hadoop hadoop //创建hadoop用户在此组下面
其实也可以在root用户下操作的,之所以要新增一个hadoop用户和组,是因为root用户要处理的事太多了,如果让root操作hadoop可能会造成安全性的问题
接下来就让hadoop用户获得root的权限,修改etc/sudoers文件即可,详细命令为:
sudo gedit /etc/sudoers/
把root的权限复制一份交给hadoop:如图

至此,第一步工作顺利完成
下载对应版本的jdk并进行解压和环境变量的配置
经过了第一步,我们已经有了hadoop用户和组,不要浪费资源,直接登陆hadoop用户开搞:su hadoop
输入密码之后登陆hadoop
然后我们解压我们的jdk,注意,2.60版本的hadoop需要的是1.7以上版本的jdk的支持,不然也是不会装成功的我这里是把jdk安装在了/usr/local目录下,注意,由于一开始的此文件权限太低,jdk无法复制进来,故先给权限给/usr/local
sudo chmod /usr/local 777
把jdk复制进去之后,在调回 sudo chmod /usr/local 777,进入jdk所在的目录 cd /usr/local接着我们来进行解压jdk: sudo tar -xzvf jdkXXX
经过一长串的解压,我们就可以配置环境变量了,这个步骤尤为关键,非常的关键,大部分的hadoop配置失败可能都在jdk配置这有问题 有三种配置方法:
第一种:sudo gedit /src/profile
第二种:source ~/.bashrc
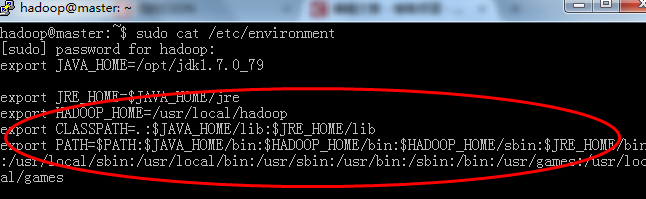
第三种:sudo gedit /etc/enviroment
我个人推荐第三种,因为在第一二种配置之后最后还是会读取environment文件,所以配置第三种是比较保险的
配置如下(每个人的机器情况不一样,信息视情况而定):
配置好之后,一定要执行source命令,使得刚刚配置的环境变量立即生效,不然到了最后你会很痛苦的。
好,之后需要作的是替代掉原来系统的老掉牙的jdk,这里也是要非常的谨慎,命令如下:
sudo update-alternatives –install /usr/bin/java java /usr/local/java-7-sun/bin/java 300
sudo update-alternatives –install /usr/bin/javac javac /usr/local/java-7-sun/bin/javac 300
sudo update-alternatives –config java
万一配置错误,则删掉重配:sudo update-alternatives –remove-all 变量名
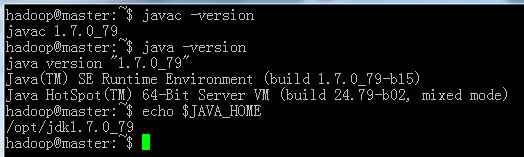
之后进行jdk测试,要注意的是一定要测试java_home,不然在最后hadoop也是会失败,一定要保证java_home的成功
好了,到这一步jdk顺安装完成
3.配置好host文件
这一步是为了下一步ssh免密码登陆做准备我们这里部署的是完全真机集群环境开发hadoop研究,修改host文件则可以通过主机名绑定对应的ip地址实现各个节点的访问,
遇到的问题:每次重启机器ip都会改变
解决:绑定好ip
在系统中点击网络设置(窗口右上角)->新增一个网络->ip设置手动->配置好ip,子网掩码,网关,dns保存
然后通过重启虚拟机使得生效,在root用户下执行 shutdown -r now命令重启虚拟机
配置的host命令和详细信息如图:
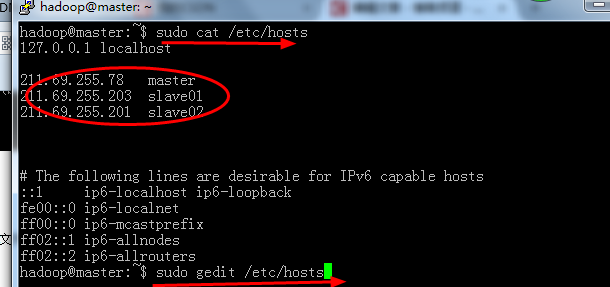
至此,第三部确定完成,注意,每个节点都要配置hsots文件,如果节点过多则可以通过对应的脚本去实现.
(3)配置ssh免密码登陆
玩过集群的人都知道,集群离不开相互通信,那么主从机的链接通信则是通过ssh实现的,简单的说下它的原理
服务端向客户端发出自己的公钥
客户端使用服务端的公钥加密通讯秘钥让后发给服务器端
如果通讯过程被截获,由于窃听者即使获知公钥和经过公钥加密的内容,但是不拥有私钥依然无法解密(RSA算法,一个不对称的算法,已经证实了逆推的不可行性,保证了私钥的唯一性)
服务器端接收到密文后,用私钥解密,获知通讯秘钥
ssh-keygen命令给服务器端产生私钥对,cp命令将服务器端公钥复制到客户端,因此客户端本身就拥有了服务端公钥,即可以免密码登陆
原理之后就是配置了:
首先先连接下自己的主机:ssh localhost ,如果没有错误的信息或者警告信息提示,那么恭喜,你的机子上已经安装过ssh了,否则就通过
sudo apt-get install openssh-server :安装服务器 ,会在根目录下生成一个.ssh目录,到时候公钥和私钥就生成在此文件夹下面
如果这一步都失败了,而且报错
E: Package openssh-server has no installation candidate //E:软件包 openssh-server 还没有可供安装的候选者
这时候你改直接更新apt-get:
sudo apt-get update 如果这一步也报错,那么,恭喜你,可能你的ubantu老掉牙了,需要更新下源了:
sudo apt-get clean
sudo mv /var/lib/apt/lists /var/lib/apt/lists.broke
sudo mkdir -P /var/lib/apt/lists/partial
sudo apt-get update
然后就等待update 完成之后,再sudo apt-get install openssh-server ,就能启动成功了。
接着我们进入.ssh目录: cd ~/.ssh
然后生成秘钥对(公钥和私钥) :ssh-keygen -t rsa 然后无脑回车,就会按照默认的选项将生成的密钥保存在.ssh/id_rsa文件中。如图:
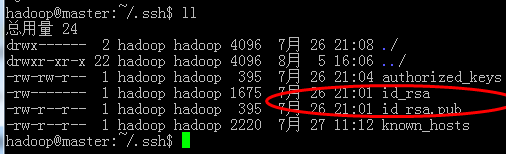
按照ssh的原理,我们要做的是把刚刚产生的公钥复制到一个叫authoried_keys中,然后将此文件夹发送给另外一个重机以实现无密码登陆
cp id_rsa.pub authorized_keys
scp authorized_keys hadoop@192.168.1.111:/home/hadoop/.ssh ——把刚刚产生的authorized_keys文件拷一份到主机B上.
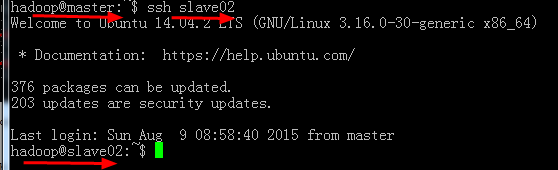
然后执行ssh slave02命令,没意外的话就成功实现了ssh无密码互联,如图:
(4)下载并解压hadoop安装包
这个和jdk的操作基本一样,但是有一个一定注意的:在給了/usr/local 777权限把hadoop压缩包放到下面后,一定要降低权限改例如755,否则会因为权限过高而导致ssh无密码链接失败,报的错误是connect refuse ,port 22 XXXXX,至此已经完成了50%的工作了.
(5):前面的工作之后,我们要做就是配置好hadoop的各种配置文件,提供给大家一个博客,上面是对这些文件参数的配置说明
http://blog.csdn.net/yangjl38/article/details/7583374
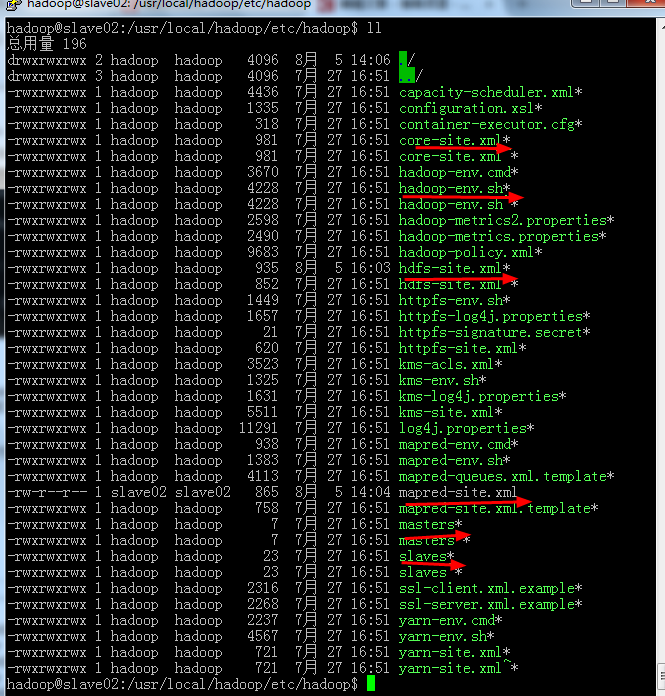
a:跳转到此目录下cd usr/local/hadoop/etc/hadoop,然后你能看到在此目录下面有一堆的配置文件,我们要做的是配置其中的几个
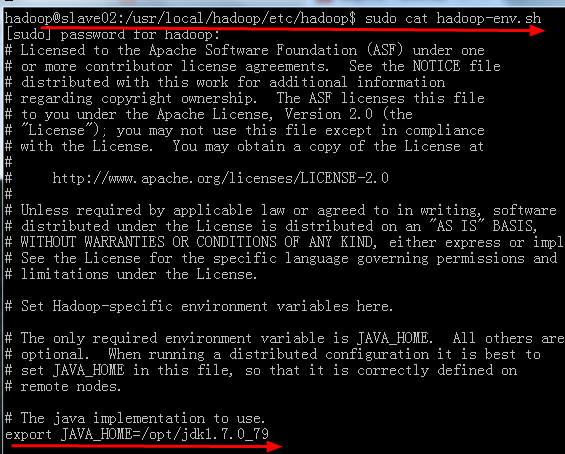
b:配置好hadoop-evn.sh文件,这是它的环境变量配置,hadoop依赖jdk环境,所以问要在此文件中配置好jdk(java_home)的位置
namenode是hdfs的核心
(6):配置hadoop-env.sh文件:
c:配置好core-site.xml
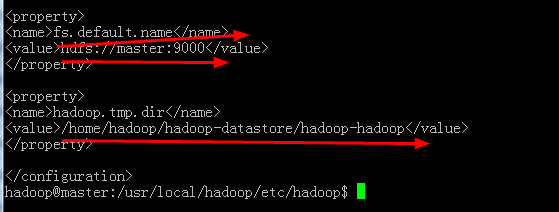
这个配置非常的重要:简单的说下里面的配置项:dfs.defult.name-value:主机的名字和对应的端口号,注意:真机集群一定要写上主机名或者对应的ip地址
hadoop.tmp.dir:存储名称节点的永久元数据的目录的列表.名称节点在列表中的每一个目录下都存储着元数据的副本,到时如果你不小心配置失败,请到此目录下面把对应的数据信息删除掉,然后重新配置
d:hdfs-site.xml,这个配置也非常的重要
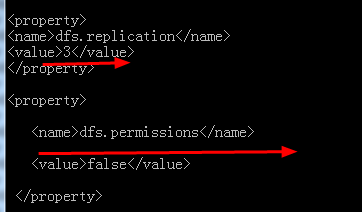
前面的规定了有多少个节点在集群中(包括主节点)
dfs.permission:文件操作时的权限检查标识别
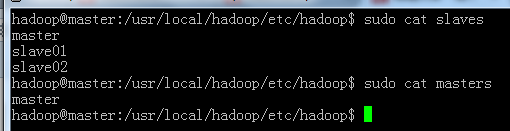
e:然后配置slaves,和master,这个比较简单:但是要注意的是slaves中必须要加入主机域名,不然最后会失败
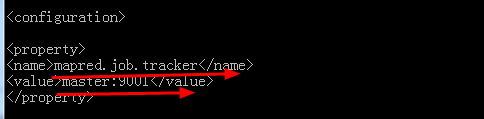
f:配置好mapred-site.xml 这个也是非常的重要,在hadoop中的2大支柱,除了hdfs就是map-reduce
(7):配置好之后直接向各节点复制haoop
scp -r /usr/local/hadoop hadoop@slave01:/usr/local
在slave节点上,分别把得到的hadoop文件的权限分配给hadoop用户组的hadoop用户,执行如下命令
sudo chown -R hadoop:hadoop hadoop 这个非常的重要,不执行这个hadoop没有权限的话直接导致失败
(8):接下来格式化namenode
第一次启动hadoop集群需要对namenode进行格式化,执行命令:bin/hdfs namenode -format
9:启动hadoop
sbin/start-all.sh
如果搭建不成功则sbin/stop-all.sh关闭服务,清除tmp和你配置的存储数据的文件夹,清空后,然后在配置
10:用jps检验各后台进程是否成功启动
master节点的50070端口,显示活着的节点不是1的话,恭喜你们,成功了















 3834
3834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









