







本文根据 CAA 百科全书翻译,作为学习笔记以便查阅。
原文链接:C++ Coding Rules
目录
1.13 尽量为每个类提供默认构造函数、析构函数、复制构造函数和赋值运算符
3.2 永远不要在组件上实现该组件已实现接口的 OM 方式派生接口
3.4 始终以 OM 方式从 CATBaseUnknown 派生扩展
3.5 永远不要从实现多个接口的扩展中以 C++ 方式派生扩展
1、适用于 C++ 的规则
1.1 始终为每个 C++ 或 C 实体创建头文件
为每个类、接口、结构、全局枚举、全局函数和宏创建单独的头文件,并仅将实体的声明放入头文件中,保持头文件与实体同名。例如:
CATBaseUnknown 类的头文件为 CATBaseUnknown.h 。
1.2 始终使用预编译指令括住头文件
这样做可以防止代码重复包含头文件。例如:
#ifndef CATBaseUnknown_h
#define CATBaseUnknown_h
... // #include 语句
... // 前向声明和类声明
#endif
1.3 审慎使用 #include
在头文件中使用 #include 包含每个文件时始终思考:是否真的需要包含此文件,使用前向声明是否足够?
正确的做法如下:
- 类用作基类时,使用 #include 包含其头文件,例如:
#include "BaseClass.h"
class DerivedClass :public BaseClass
{
...
};- 类的实例用作数据成员时,使用 #include 包含其头文件,例如:
#include "CATClass.h"
class MyClass
{
private:
CATClass _myObject;
};- 类的引用、值或指针用作函数返回值或参数时,或类的指针用作数据成员时,使用其前向声明,例如:
class CATUnicodeString;
class MyClass
{
public:
void SetTitle(const CATUnicodeString& iTitle);
CATUnicodeString& GetTitle();
void SetName(const CATUnicodeString iName);
CATUnicodeString GetName();
void setId(const CATUnicodeString* iId);
CATUnicodeString* GetId();
private:
CATUnicodeString *Title, *Name, *Id;
};对于每个被包含的头文件,请检查是否实际使用了文件中的类、枚举、宏、typedef 类型或 #define 参数,否则删除它。
不要包含无用的 C++ 头文件(如 stream.h 或 iostream.h),因为它们可能的静态数据成员无论是否使用都需要分配内存。
永远不要从其他文件复制和粘贴整个 #include 语句集,这是最愚蠢的做法,这样做将更难对有用和无用的头文件进行区分。如果包含无用的头文件,不但代码会变得冗余,管理模块依赖项和构建模块所需的时间也会变长。
1.4 审慎使用命名空间
尽量避免使用命名空间以保护实现代码,通过将头文件放在框架的 PrivateInterfaces 或 LocalInterfaces 目录下来避免与其他框架的名称冲突。
对于更可见的头文件中,遵守相关命名规则应该可以避免使用命名空间。但是,命名空间可以用于解决名称过于通用的枚举值的名称冲突问题。
永远不要在 Object Modeler 接口、扩展、实现、TIE及实现先决条件的类中使用命名空间。
不要在位于框架 PublicInterfaces 和 ProtectedInterfaces 目录的头文件中直接使用 using namespace 语句,尽量使用域解析运算符,例如:
// 应尽量避免的用法
using namespace std;
// 推荐的用法
std::cout << "hello world !" << std::endl;1.5 不要使用线程
多线程的复杂性引发的问题多于解决的问题。
1.6 不要使用模板
模板不能移植到不同的操作系统,尤其是编译器和链接编辑器的支持性。
1.7 不要使用多重继承
多重继承引发的主要问题是多个成员歧义,无论它们是来自不同基类的同名成员,或相同基类的多重继承的成员。应使用 Object Modeler 提供的其他方式(如接口和组件)来进行处理,并保持 C++ 的单一继承。
1.8 不要使用虚拟继承
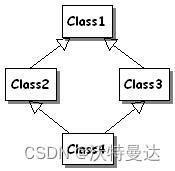
虚拟继承主要用于解决多重继承中菱形继承(图 1)的成员歧义问题,由于不应使用多重继承,因此也不要使用虚拟继承。
1.9 始终使用 Public 继承
继承方式有 public、protected、private 三种,基类中的成员在不同继承模式下的派生类中的可见性如下表:
| 基类中成员的可见性 | 派生类中成员的可见性 | ||
| public | protected | private | |
|---|---|---|---|
| public | public | protected | private |
| protected | protected | protected | private |
| private | private | private | private |
要保证派生类中的成员可见性与基类相同,应使用 public 继承。
1.10 不要使用友元
如果两个类在概念上是一个对象,共享相同的生命周期,例如当一个“大”对象分成多个部分时(如发动机是汽车的一部分),你可能会这样做,但使用友元会破坏对象的封装性,面对这种情况,请考虑使用聚合作为替代技术。
1.11 始终使用私有数据成员
为保证类的封装性,将数据成员设置为私有,并将访问的方法设置共有。
1.12 避免使用静态数据成员
静态是内存碎片的同义词,还需要静态成员函数来处理静态数据成员。在定义静态数据成员之前,请确保此数据对类的所有实例(如实例计数器)确实是通用的,而不仅仅是对其中的某些实例。
1.13 尽量为每个类提供默认构造函数、析构函数、复制构造函数和赋值运算符
客户端将假设这些基本函数始终存在。
警告:如果这样做会破坏对象的逻辑,则不要这样做。例如某些对象绝对需要在其构造函数中引用其他的对象,不要为它们提供默认构造函数,或者最好提供默认构造函数和 Init 方法来传递初始化参数。
对于扩展:此规则对于扩展尤其适用。需要注意的是,客户端从不直接调用这些函数,因此复制构造函数和赋值运算符对于扩展类是无用的,并且会增加代码大小,但如果不提供的话,编译器会自动添加,为避免如此,应在类的私有域将复制构造函数和赋值运算符声明为非虚拟,且不提供实现,这样编译器就不会自动添加,也不会提供默认实现,唯一要记住的是不要在扩展类的代码中调用它们。
1.14 始终将类的析构函数声明为虚函数以便类的派生
当使用基类的指针指向派生类的对象时,这一点非常重要。
假设如下:
class A
{
public:
A();
~A();
...
};
class B : public A
{
public:
B();
~B();
...
};
int main()
{
...
B* pB = new B(); // 先调用 A 类构造函数,然后调用 B类构造函数
A* pA = pB;
...
delete pA; // 仅调用 A 类析构函数
...
return 0;
}在上面的情况中,pA 是 A 类的指针,指向的是 B 类对象,由于 A 类的析构函数不是虚函数,因此仅调用 A 类的析构函数,不调用 B 类的析构函数,从而导致内存泄漏。
如果 A 类的析构函数是虚函数,则首先调用 B 类的析构函数,然后调用 A 类的析构函数,且不会发生内存泄漏,如下所示:
class A
{
public:
A();
virtual ~A();
...
};
class B : public A
{
public:
B();
virtual ~B();
...
};
int main()
{
...
B* pB = new B(); // 先调用 A 类构造函数,然后调用 B类构造函数
A* pA = pB;
...
delete pA; // 先调用 B 类析构函数,然后调用 A 类析构函数
...
return 0;
}1.15 不要在类的私有域中声明虚函数
虚函数是为了在派生类中重写,私有域中的虚函数在派生类不可见,无法重写。
1.16 始终将可能被重写的函数声明为虚函数
首先,虚函数应声明在共有域或受保护域中,例如:
class CATClass
{
public:
...
virtual HRESULT ComputeUsingAGoodAlgorithm(); // 可以在派生类进行重写
HRESULT ComputeUsingMyAlgorithm(); // 不能在派生类进行重写
...
};客户端代码使用派生类时可以继承并重写这些函数,从而实现对象的多态处理。应将所有可能使类成为基类的函数声明为虚函数,并在派生类中重写这些函数。这样做可以保证类的扩展性。
建议:除非类为不可派生的类,否则应始终应用此规则。
1.17 避免使用内联函数
虽然内联函数可以减少函数调用开销提高程序执行速度,但一般情况下仍然应避免使用内联函数,因为对内联函数的任何修改都会强制客户端应用程序重新生成。
建议:仅当需要非常小的函数提高性能时才使用内联函数,在大型函数中将失去内联函数的优势,选择使用内联函数时应进行性能分析。
- 永远不要创建内联虚函数
编译器很难实现这些方法,它会在所有包含内联虚函数头文件的可执行代码源文件中添加这些方法的实现,即使类和方法未使用也是如此,这将增加此类的客户端所有模块的大小。
- 永远不要创建内联构造函数
构造函数的实现应放在类的源代码文件中,所以永远不要像下面这样做:
class MyClass : public MyParentClass
{
inline MyClass(int i) : MyParentClass(i, "WhyNot"), _MyPointer(NULL) {}
...
};- 永远不要在内联函数中调用其他方法
在内联函数中调用其他方法导致的调用开销会让内联的优势丧失,此外一些编译器还会在所有源文件包含此内联函数头文件的执行代码中将其实现为静态函数,所以永远不要像下面这样做:
class MyClass
{
public:
inline int foo(int i) { return i * GetValue(); }
...
};1.18 不要重载基本运算符
除非对任何人都是显而易见的,否则不要重载基本运算符。
建议:提供重载基本运算符前,请先验证其是否符合此运算符的原本属性。例如人们对 “+” 运算符的预期是可以交换的,不要提供不符合的,如字符串连接。
1.19 不要在头文件中添加非声明性代码
这对代码的大小来说是灾难性的,且会使其与客户端代码耦合,导致每次修改都需要重新生成。
注意下面的代码,它在类的头文件中不是声明性代码,而是可执行代码,它调用了类的构造函数,并在所有包含此头文件的类中创建了一个实例。
MyClass obj;
请看下面的例子:
#ifndef MyClass_h
#define MyClass_h
class MyClass
{
...
};
MyClass AnInstance;
#endif此代码在每个包含此头文件的源代码中创建一个 MyClass 类的实例,在共享库或动态链接库加载到内存中时调用其构造函数,并在退出时调用析构函数,该实例通常是核心转储。应首选以下声明方式:
extern ExportedByCATModuleName const MyClass AnInstance;
并在对应的源文件中添加以下代码:
const MyClass AnInstance;1.20 不要使用隐式类型强制转换
将类的实例作为方法参数或在表达式中传递时,请检查其类型是否与预期类型匹配,或使用显式类型强制转换来获取此类型。否则,编译器会尝试将实际类型隐式转换为所需的类型。当存在两种不同的转换方式时,某些编译器会因为歧义而报告错误,还有一些编译器则自动做出选择且不会报告错误,这种情况更糟,因为只有在运行时才能检测到错误。应将实例显式转换为适当的类型以控制实际执行的类型转换。
例如:假设 MyInt 类封装了一个基本类型的整数值:
class MyInt
{
public:
MyInt(int iInt); // 构造函数
MyInt operator + (MyInt); // 运算符重载
operator int(); // 转换为 int 类型
private:
int a;
};表达式 (x + 1) 是歧义的,因为它可以解释为以下任一情况:
// 将 x 转换为 int 类型后使用 int 类型的 + 运算符,结果为 int 类型值
(x.operator int() + 1);
或者
// 将 1 构造成 MyInt 实例后使用 MyInt 类型的 + 运算符,结果为 MyInt 实例
(x.operator + (MyInt(1)));如果构造函数和转换函数都可以将一个对象转换为另一个对象,则也会发生相同的歧义。
以下是此类表达式的编译结果:
MyInt y1 = x + 1; // error AIX, IRIX, HP-UX, Windows / OK Solaris
int y2 = x + 1; // error AIX, IRIX, HP-UX, Windows / OK Solaris
int y3 = int(x) + 1; // OK
MyInt y4 = x + (MyInt(1)); // OK对于这种情况可以通过在构造函数前加 explicit 前缀使编译器报告错误(对于 AIX 和 Solaris 未知),如下所示:
class MyInt
{
public:
explicit MyInt(int iInt); // 构造函数
MyInt operator + (MyInt); // 运算符重载
operator int(); // 转换为 int 类型
private:
int a;
};
// 此类表达式的编译结果
MyInt y1 = x + 1; // error IRIX, HP-UX, Windows
int y2 = x + 1; // OK IRIX, HP-UX, Windows
int y3 = int(x) + 1; // OK
MyInt y4 = x + (MyInt(1)); // error HP_UX / OK IRIX, Windows1.21 仅使用合法类型
合法类型是可以分配给变量的类型,分为标量类型和非标量类型,详见下表:
| 类型 | 含义 |
|---|---|
| CATBoolean | 可以取值 TRUE (1) 或 FALSE (0) ,此类型不是 C++ 内置类型,使用使需包含 SystemTS 框架的 CATBoolean.h 头文件。 |
| char | |
| wchar_t | UNICODE 字符。 |
| short | |
| int | |
| float | 遵循 IEEE 754-1985 标准定义的 32 位浮点数。 |
| double | 遵循 IEEE 754-1985 标准定义的 64 位浮点数。 |
| unsigned char | |
| unsigned short | |
| unsigned int |
| 类型 | 含义 |
|---|---|
| char* | 非 NLS 字符串。 |
| wchar_t* | Unicode 字符串。 |
| CATString | 使用 ISO 10646 代码页编码的字符串,也称为 7 位 ASCII。 |
| CATUnicodeString | Unicode 字符串。CATUnicodeString 应翻译为用户语言用于界面显示,或不翻译直接用作用户语言表示的字符串,如文件名。其他情况应使用 CATString 或 char*。 |
| enum <NAME>{<VALUE1>}</VALUE1></NAME> | 枚举整数值。 |
| <scalar type>[size] | 标量元素的数组,可以是固定大小或可变大小。固定大小的数组在用作输出参数时使用 * 表示法而非 [] 表示法定义,例如 float array[]* 是错误的,正确写法是 float array** 。 包含 3 个浮点数的数组定义:float myFixedArray[3] ; 包含可变数量浮点数的数组定义:float* myVariableArray 。 |
| struct | 由一个或多个类型的字段组成的结构。每个字段的类型仅限于表 1 中定义的合法类型。 |
| interface | Object Modeler 接口。当接口的确切类型未知时,应使用 CATBaseUnknown 类型而非 void* 。 |
| CATListOf <X> | 用于管理不同类型元素列表的集合类。 |
| <interface>_var | 智能指针,也称作 handler ,只能用作方法参数或返回值,不能新建。 |
另请参阅表 3,其中汇总了上述类型作为参数时的用法。
1.22 使用 const 关键字修饰常量、参数和方法
方法中的不可变参数应使用 const 关键字来修饰。使用 const 修饰标量类型的用法如下:
const int i; // 错误,i 是 int 类型常量,应当初始化
const int j = 5; // 正确,j 是 int 类型常量,且已初始化
int l = 5;
const int* k; // k 是一个指针类型变量,它指向的值是 int 类型常量
int* const m = &l; // m 是一个指针类型常量, 它指向的值是 int 类型变量
const int* const n = &l; // n 是一个指针类型常量,它指向的值是 int 类型常量这个规则可以与方法参数(尤其是输入参数)或返回值以及必须在构造函数中初始化的数据成员一起使用(常量数据成员必须在构造函数初始化列表中进行初始化)。成员函数可以声明为 const 以对常量进行操作(仅读取)。
1.23 合理使用域解析运算符
假设如下:
class A
{
public:
virtual void m();
};
class B : public A
{
public:
void m() override;
};
class C : public B
{
public:
void f();
};不要像下面这样在 C::f() 中调用 A::m() ,因为 C 类的实例同时也是一个 B 类的实例,实际指向的 m() 可能不符合预期。可以使用 B::() 或者 m() 。
void C::f()
{
A::m(); // 禁止这样做
B::m(); // OK
m(); // OK
}1.24 不要创建异常
使用异常来处理错误是经典的做法,但在大型应用程序中这样做是不可取的,因为所有对可能抛出异常的方法的调用都需要捕获并处理异常,但调用方法通常不知道该怎么处理。应使用 CATError 作为替代。
注意:某些 CATIA 的框架可能会抛出异常,应使用 CATTry、CATCatch 和 CATCatchOthers 宏来进行捕获和处理。
2、生命周期规则
2.1 管理接口指针的生命周期
一般来说,接口指针应:
- 在复制后立即调用 AddRef
- 不再需要时立即调用 Release
对 AddRef 的每次调用应关联调用 Release 。
下面的规则适用于方法参数:
- 对于输入参数:调用者应传入 AddRef 指针作为被调方法的输入参数,被调方法不应修改输入参数指针,也不应该调用 AddRef 和 Release ,调用者在被调方法返回可以继续使用指针,并在不再需要指针时立即调用 Release 。例如:
...
CATIPsiRepRefApplicativeDataAccess* piDataAccessOnRepRef = NULL;
... // 初始化 piDataAccessOnRepRef
CATIMmiPrtContainer* piSourceContainer = NULL;
... // 初始化用于调用 CreateApplicativeContainer 的其他参数
HRESULT rc = E_FAIL;
rc = piDataAccessOnRepRef->CreateApplicativeContainer(
(void**)&piSourceContainer, // piSourceContainer 调用了 AddRef
idAppliCont,
IID_CATIMmiPrtContainer,
"",
sourceAppliContId);
if (SUCCEEDED(rc) && (NULL != piSourceContainer))
{
rc = ::methodA(...,
piSourceContainer, // methodA 使用 piSourceContainer,但不修改它
...); // 没有调用 AddRef/Release
...
piSourceContainer->Release(); // piSourceContainer 不再需要
piSourceContainer = NULL;
...
}此例中,CreateApplicativeContainer 方法返回了一个 AddRef 指针 piSourceContainer ,methodA 方法仅使用了该指针,没有对其进行修改,也没有调用 AddRef 和 Release ,methodA 方法返回后,piSourceContainer 可以继续使用,直到不需要时调用其 Release 并设置为 NULL 。
如果不使用返回 AddRef 指针的方法(例如本例的 CreateApplicativeContainer 或更通用的 QueryInterface)来初始化指针,则必须显式调用 AddRef ,就像下面这样:
if (SUCCEEDED(rc) && (NULL != piSourceContainer))
{
CATIMmiPrtContainer* piSourceContainer2 = piSourceContainer; // 复制指针
piSourceContainer2->AddRef(); // 立即调用 AddRef
rc = ::methodA(...,
piSourceContainer2, // methodA 使用 piSourceContainer2 ,但不修改它
...); // 没有调用 AddRef/Release
...
piSourceContainer2->Release(); // piSourceContainer 不再需要
piSourceContainer2 = NULL;
...
}- 对于输出参数:调用者应传入 NULL 指针作为被调方法的参数,不要传入 AddRef 指针,因为指针的值对于被调方法无用。被调方法对指针赋值后应立即调用 AddRef 方法,被调方法返回后,调用者使用指针,并在不再需要时立即调用 Release 。例如:
...
CATIMmiPrtContainer* piSourceContainer = NULL;
... // 初始化 piSourceContainer
HRESULT rc = E_FAIL;
CATICutAndPastable* piCCPOnSourceCont = NULL;
rc = piSourceContainer->QueryInterface(IID_CATICutAndPastable,
(void**)&piCCPOnSourceCont);
// 展开 QueryInterface
HRESULT QueryInterface(const IID& iid, void** ppv)
{
...
*ppv = ...; // piCutAndPastableOnSourceCont 复制了一个值
*ppv->AddRef(); // 立即调用 AddRef
...
}
... // 使用 piCCPOnSourceCont
piCCPOnSourceCont->Release(); // piCCPOnSourceCont 不再需要
piCCPOnSourceCont = NULL;
...此例中,调用者传递了 NULL 指针给 QueryInterface ,指针在 QueryInterface 方法中赋值并立即调用 AddRef ,之后调用者使用了指针,直到不需要时调用其 Release 并设置为 NULL 。
- 对于输入/输出参数:调用者应传入 AddRef 指针作为被调方法的参数,被调方法使用完指针后调用 Release,并在给指针赋予新的值后立即调用 AddRef ,被调方法返回后,调用者使用指针,并在不再需要时立即调用 Release 。例如:
...
CATIMmiPrtContainer* piSourceContainer = NULL;
... // 初始化 piSourceContainer
HRESULT rc = E_FAIL;
CATICutAndPastable* piCCPOnSourceCont = NULL;
rc = piSourceContainer->QueryInterface(IID_CATICutAndPastable,
(void**)&piCCPOnSourceCont); // 在 QueryInterface 调用 AddRef
CATICutAndPastable* piCCPOnSourceCont2 = piCCPOnSourceCont; // 复制指针
piCCPOnSourceCont2->AddRef(); // 立即调用 AddRef
HRESULT rc = pDoc->CalledMethod(&piCCPOnSourceCont2)
// 展开 CalledMethod
HRESULT CalledMethod(CATInit** ppv)
{
...
*ppv->Init() // 使用 piCCPOnSourceCont2
...
*ppv->Release(); // Release piCCPOnSourceCont2
*ppv = ...; // piCCPOnSourceCont2 复制了一个值
*ppv->AddRef(); // 立即调用 AddRef
...
*ppv->Init() // 再次使用 piCCPOnSourceCont2
...
}
... // 使用 piCCPOnSourceCont2
piCCPOnSourceCont2->Release(); // piCCPOnSourceCont2 不再需要
piCCPOnSourceCont2 = NULL;
...此例中,调用者使用 QueryInterface 初始化了指针 piCCPOnSourceCont ,这是一个 AddRef 指针,然后将这个指针传递到 CalledMethod 方法中,在 CalledMethod 方法中首先使用了指针的值,用完之后调用 Release ,然后 piCCPOnSourceCont 复制了一个值并立即调用 AddRef ,之后 CalledMethod 方法再次使用了指针,CalledMethod 方法返回后,调用者使用指针 piCCPOnSourceCont ,直到不需要时调用其 Release 并设置为 NULL 。
2.2 管理对象指针的生命周期
一般来说:new 和 delete 匹配使用, malloc 和 free 匹配使用。
- 对于输入参数:由调用者调用 malloc 和 free
- 对于输出参数:由被调方法调用 malloc ,由调用者调用 free
- 对于输入/输出参数:由调用者调用 malloc ,被调方法使用参数后进行修改,修改时应先调用 free 再调用 malloc ,被调方法返回后,调用者使用参数并在用完后调用 free 。
对于输出参数:
- 调用者负责在将指针传递给被调方法前将指针设置为 NULL
- 如果操作失败,被调方法负责清理内存并将指针设置为 NULL 后再返回给调用者
对于输入/输出参数,如果被调方法操作失败:
- 被调方法负责还原指针初始值或清理内存,并将指针设置为 NULL 后再返回给调用者
- 调用者负责检查传回的指针是否可用
2.3 始终按下表方式传递方法参数
| 类型 | 输入参数 | 输出参数 | 输入/输出参数 |
|---|---|---|---|
CATBoolean | const CATBoolean iMyBoolean | CATBoolean *oMyBoolean | CATBoolean *ioMyBoolean |
char | const char iMyChar | char *oMyChar | char *ioMyChar |
CATString | const CATString iMyString | CATString *oMyString | CATString *ioMyString |
wchar_t | const wchar_t iMyWChar | wchar_t *oMyWChar | wchar_t *ioMyWChar |
CATUnicodeString | const CATUnicodeString &iMyUString | CATUnicodeString &oMyUString | CATUnicodeString &ioMyUString |
short | const short iMyShort | short *oMyShort | short *ioMyShort |
int | const int iMyInt | int *oMyInt | int *ioMyInt |
CATLong32 | const CATLong32 iMyLong32 | CATLong32 *oMyLong32 | CATLong32 *ioMyLong32 |
float | const float iMyFloat | float *oMyFloat | float *ioMyFloat |
double | const double iMyDouble | double *oMyDouble | double *ioMyDouble |
unsigned char | const unsigned char iMyUChar | unsigned char *oMyUChar | unsigned char *ioMyUChar |
unsigned short | const unsigned short iMyUShort | unsigned short *oMyUShort | unsigned short *oMyUShort |
unsigned int | const unsigned int iMyUInt | unsigned int *oMyUInt | unsigned int *ioMyUInt |
CATULong32 | const CATULong32 iMyULong32 | CATULong32 *oMyULong32 | CATULong32 *ioMyULong32 |
char * | const char *iMyChar | char **oMyChar | char **ioMyChar |
CATString * | const CATString *iMyString | CATString **oMyString | CATString **ioMyString |
wchar_t * | const wchar_t *iMyWChar | wchar_t **oMyWChar | wchar_t **ioMyWChar |
CATUnicodeString * | const CATUnicodeString *iMyUString | CATUnicodeString *&oMyUString | CATUnicodeString *&ioMyUString |
enum <name> {<value>} | const <name> iMyEnum | <name> *oMyEnum | <name> *ioMyEnum |
<scalar type> [size] | const <scalar type> *iMyArray | <scalar type> **oMyArray | <scalar type> **ioMyArray |
struct | const CATStruct *iMyStruct | CATStruct **oMyStruct | CATStruct **ioMyStruct |
interface | const CATIXX *iCmpAsXX | CATIXX **oCmpAsXX | CATIXX **ioCmpAsXX |
关于 CATUnicodeString 的注意事项:单个 CATUnicodeString 的实例应始终使用引用传递,不要使用指针传递,也不要使用值传递,因为值传递可能会执行字符串数据复制。理想情况下, CATUnicodeString 永远不要在堆上分配(编译时大小未知的 CATUnicodeString 数组除外),此类是一种值类型,可以像内置类型一样使用。
2.4 始终将指针初始化为 NULL
始终在创建对象或接口的指针时将其初始化为 NULL ,避免在不知情的状况下使用非 NULL 指针而导致内存泄漏。
...
CATBaseUnknown *pBaseUnknown = NULL; // 指针赋空值
...2.5 始终在使用指针前对其进行检查
始终在使用指针前检查其是否为 NULL ,错误地使用 NULL 指针将导致程序崩溃。最好将 NULL 放在前面。
if (NULL != pBaseUnknown)
{
... // 此处可以安全地使用指针
}
else if (NULL == pBaseUnknown)
{
... // 此处不能使用指针
}2.6 始终将指向已删除对象的指针设置为 NULL
每当使用 delete 删除 new 创建的对象时,或使用 free 释放 malloc 、 calloc 、 realloc 分配的内存时,立即将指针设置为 NULL 以确保指针不再可用。
if (NULL != pObject)
{
delete pObject;
pObject = NULL;
}
if (NULL != pMemBlock)
{
free(pMemBlock);
pMemBlock = NULL;
}2.7 始终将已释放的接口指针设置为 NULL
释放接口指针意味着不再需要它,为确保指针不再可用,应在释放指针后立即将其设置为 NULL 。
...
piIUnknown->Release();
piIUnknown = NULL;
...
3、Object Modeler 规则
3.1 永远不要在组件上重复实现相同接口
这样做是为了符合“决定论原则”,否则,对此接口调用 QueryInterface 的结果是不确定的。
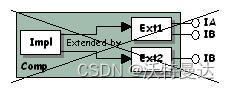
调用 QueryInterface 的结果应始终是确定的。如图 2,这里调用 QueryInterface 获取 IB 的结果是不确定的,调用者无法确定 QueryInterface 返回的是 Ext1 还是 Ext2 的指针,具体取决于运行时上下文(字典声明顺序或共享库、动态链接库加载顺序),QueryInterface 也无法标识返回的是哪个指针。
3.2 永远不要在组件上实现该组件已实现接口的 OM 方式派生接口
这样做是为了符合“决定论原则”,否则,对此基类接口调用 QueryInterface 的结果是不确定的。
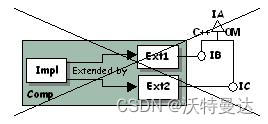
调用 QueryInterface 的结果应始终是确定的。如图 3,当 IA 以 OM 方式派生 IB 和 IC 时,调用 QueryInterface 获取 IA 的结果是不确定的,调用者无法确定 QueryInterface 返回的是 Ext1 还是 Ext2 的指针,具体取决于运行时上下文。
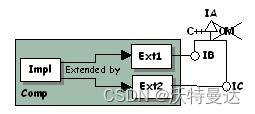
这种情况下,IA 可以以 C++ 方式派生 IB 和 IC (如图 4),这样组件就没有实现 IA,调用 QueryInterface 不会获取到 IA 的指针。具体做法是:
在 IB 和 IC 的源文件中不要写:
CATImplementInterface(IB, IA);改为写:
CATImplementInterface(IB, CATBaseUnknown);最佳做法:使 IA 成为 C++ 的抽象类而非接口,仅保留共享方法签名。即不要再 IA 的头文件中添加 CATDeclareInterface 宏和 IID ,也不要提供源文件。
3.3 合理使用数据扩展和代码扩展
如果扩展类有数据成员,则使用数据扩展,否则应使用代码扩展。
这样做是为了节约内存,代码扩展类专用于没有数据成员的扩展,对所属组件全部实例仅实例化一次,而数据扩展对所属组件的每个实例都要实例化一次。
使用 CATImplementClass 宏来声明代码扩展类,与其他扩展一样,它应当从 CATBaseUnknown 以 OM 方式派生,永远不要以 C++ 方式从数据扩展类派生代码扩展类。 例如:
CATImplementClass(MyExtension, CodeExtension, CATBaseUnknown, MyImplementation);注意:代码扩展不能与链式 TIE 一起使用。
3.4 始终以 OM 方式从 CATBaseUnknown 派生扩展
具体做法是将 CATImplementClass 宏的第三个参数设置为 CATBaseUnknown 或 CATNull 。例如:
CATImplementClass(MyExtension, DataExtension, CATBaseUnknown, MyImplementation);
或
CATImplementClass(MyExtension, DataExtension, CATNull, MyImplementation);以 C++ 方式从另一个类派生扩展会导性能降低。
3.5 永远不要从实现多个接口的扩展中以 C++ 方式派生扩展
如果从一个实现多个接口的扩展类中以 C++ 方式派生新的扩展类会实例化无用的对象,客户端代码可能会调用组件未显式实现的继承方法,这样会生成基类(扩展)的实例,客户端可以获取此基类实例所实现的接口指针。
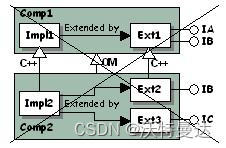
如图 5 ,Ext1 实现了 IA 和 IB ,Ext2 以 C++ 方式从 Ext1 派生并实现了 IB ,Ext3 实现了 IC ,如果从 IC 的指针调用 QueryInterface 获取 IA ,客户端不会如预期那样获取指向 Ext2 的指针,而是会获取到一个指向 Ext1 的新实例的指针(由 QueryInterface 创建),这会导致以下问题:
- Ext1 的新实例是多余的,每次调用QueryInterface 获取 IA 都会创建重复的 Ext1 实例
- 如果再 Ext2 中重写了 IA 的某些方法,这些方法永远不会执行
对此情形有三种解决方案:
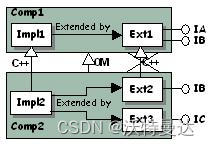
1. 推荐方案:每个派生类都实现单一接口,这样 Ext2 以 C++ 方式从 Ext1 派生(图 6)就没有必要了。
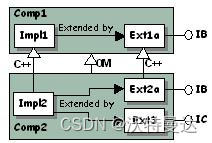
2. 如果确实需要从实现 IB 接口的扩展上派生新的扩展,应选择仅实现 IB 的扩展(图 7)。
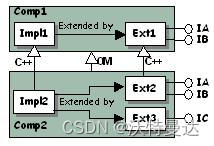
3. 如果以上两种方式都不想用,则应在新的扩展类中实现与基类相同的接口(图 8)。
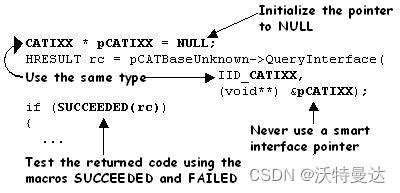
3.6 正确使用 QueryInterface
- 始终传递 NULL 指针到 QueryInterface 。
- 始终传入与要查询的接口类型相同的指针。
- 永远不要传入智能指针。
- 始终使用 SUCCEEDED 和 FAILED 宏检测返回的指针,仅当 SUCCEEDED 宏返回 TRUE 时才能使用指针。
3.7 避免使用智能指针
智能指针引发的问题多于解决的问题。
3.8 正确处理接口指针和智能指针的转换
某些情况下需要在接口指针和智能指针之间进行转换,例如查询到的是接口指针,要使用指针的函数要求传入智能指针时就会遇到这种情况。
- 避免直接将接口指针的返回值赋给智能指针变量以及在智能指针上调用 Release ,例如:
...
{
CATIXX_var spCATIXX = ::ReturnAPointerToCATIXX();
if (NULL_var != spCATIXX)
{
spCATIXX->Release(); // Release 返回的指针
... // 使用智能指针 spCATIXX
}
...
} // spCATIXX is released正确的做法如下:
...
{
CATIXX* pCATIXX = ::ReturnAPointerToCATIXX();
if (NULL != pCATIXX)
{
CATIXX_var spCATIXX = pCATIXX;
pCATIXX->Release(); // Release the returned interface pointer
if (NULL_var != spCATIXX)
{
... // Use spCATIXX
}
} // spCATIXX is released
...
}- 永远不要将接口指针的返回值赋给另一个接口的智能指针变量,例如:
CATIYY_var spCATIYY = ::ReturnAPointerToCATIXX();此例中,CATIXX 接口指针强制转为 CATIYY 智能指针后失去对 CATIXX 接口指针的控制,其引用计数器不会变为 0 ,指向的组件也会一直存在。正确的做法如下:
CATIXX* pCATIXX = ::ReturnAPointerToCATIXX();
CATIYY_var spCATIYY = pCATIXX;
pCATIXX->Release();- 永远不要将智能指针赋值给接口指针,例如:
CATIXX* pCATIXX = SmartPtrToCATIXX;这相当于复制指针,需要显式调用 AddRef 和 Release。可以像下面这样做(返回的智能指针是可变的):
CATIXX* pCATIXX = ::ReturnASmartPtrToCATIXX();3.9 正确填写字典中的接口声明
为符合“决定论原则”,确保调用 QueryInterface 的结果始终是确定的,在字典文件中填写组件实现的接口声明应遵循以下两条原则:
1. 组件中应声明如下内容:
- 组件实现的接口(图 10),这意味着组件或扩展类中应定义接口的 TIE 。
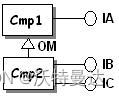
如图 10 所示,组件不应声明其实现了以 OM 方式继承的基类组件所实现(以 OM 方式)的接口,即不要在 Cmp2 上声明 IA ,字典文件应填写如下:
Cmp1 IA LibCmp1
Cmp2 IB LibCmp2
Cmp2 IC LibCmp2- 组件所实现接口以 OM 方式继承的基类接口(图 11)。
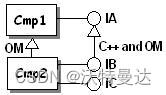
如图 11 所示,当 IB 以 C++ 方式 和 OM 方式派生自 IA 时,如果 Cmp2 没有在字典中声明它实现了 IA ,如果从 IC 的指针调用 QueryInterface 获取 IA ,则会获取到 Cmp1 而非 Cmp2 的指针。为避免这种情况,字典文件应填写如下:
Cmp1 IA LibCmp1
Cmp2 IA LibTIE_IBCmp2
Cmp2 IB LibCmp2
Cmp2 IC LibCmp22. 如果 TIE 宏生成的代码和相应接口的实现代码位于两个不同的共享库或动态链接库中,则应该在字典中声明包含 TIE 宏生成代码的共享库或动态链接库,而不是包含接口实现代码的共享库或动态链接库。


















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









