







`LogisticRegression` 模型是 `scikit-learn` 库中的一种实现逻辑回归的工具,广泛用于二分类和多分类任务。以下是关于 `LogisticRegression` 模型的详细概述,包括其基本原理、使用方法、相关参数、模型评估及应用案例。
1. 模型基本原理
逻辑回归通过将输入特征的线性组合输入到 Sigmoid 函数中来输出某个类别的概率。其数学表达式为:
Sigmoid 函数定义:
最终,通过将 Sigmoid 函数的输出与阈值比较来决定类别。
2. 使用方法
2.1 安装 `scikit-learn`
如果你尚未安装 `scikit-learn`,可以使用以下命令安装:
pip install scikit-learn
2.2 示例代码
示例1:
以下是使用 `LogisticRegression` 的基本示例:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 生成示例数据集
from sklearn.datasets import make_classification
# 创建二分类数据集
X, y = make_classification(n_samples=1000, n_features=20, n_informative=2, n_redundant=2, random_state=42)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建逻辑回归模型实例
model = LogisticRegression()
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
class_report = classification_report(y_test, y_pred)
# 输出结果
print(f"准确率: {accuracy:.2f}")
print("混淆矩阵:\n", conf_matrix)
print("分类报告:\n", class_report)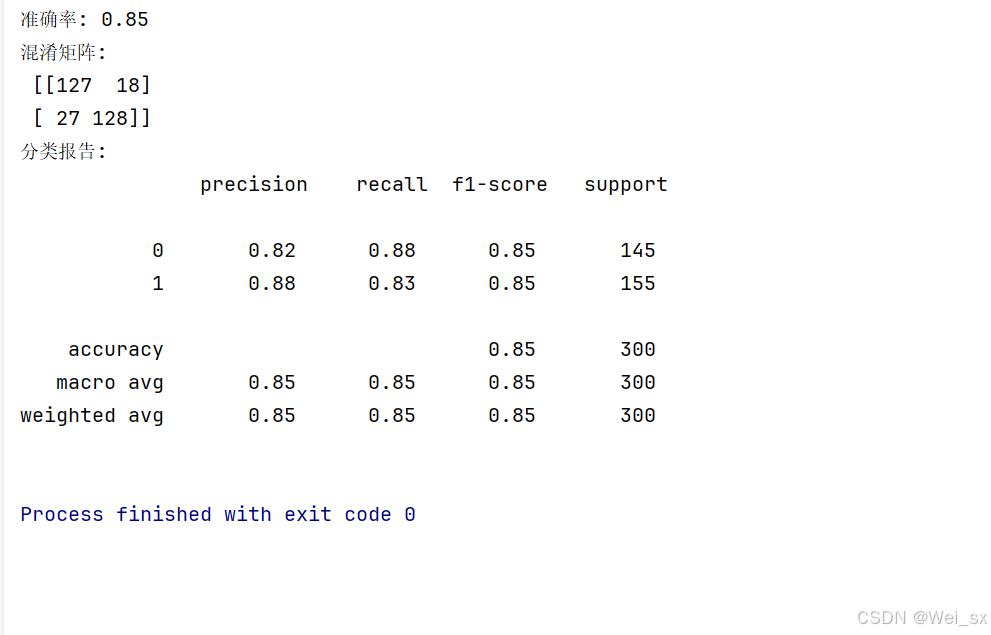
示例2:
癌症分类预测-良/恶性乳腺癌肿瘤预测
# 导入模块
mport pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# 1.获取数据
names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv('./data/breast+cancer+wisconsin+original/breast-cancer-wisconsin.data',names=names)
# 2.基本数据处理
# 2.1 缺失值处理
# 将问号处替换成NAN
data = data.replace(to_replace='?',value=np.nan)
# 删除name对应的航数据
data = data.dropna()
# 2.2 确定特征值,目标值
x = data.iloc[:,1:-1]
y = data.Class
# 2.3 分割数据
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=2,test_size=0.2)
# 3.特征工程(标准化)
# 创建标准器(实例化一个标准化对象)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 4.机器学习(逻辑回归)
# 实例化一个估计器(模型estimator)
estimator = LogisticRegression()
# 模型训练
estimator.fit(x_train,y_train)
# 5.模型评估
# 预测值
y_predict = estimator.predict(x_test)
print('预测值:\n',y_predict)
# 准确率
ret = estimator.score(x_test,y_test)
print('准确率:',ret)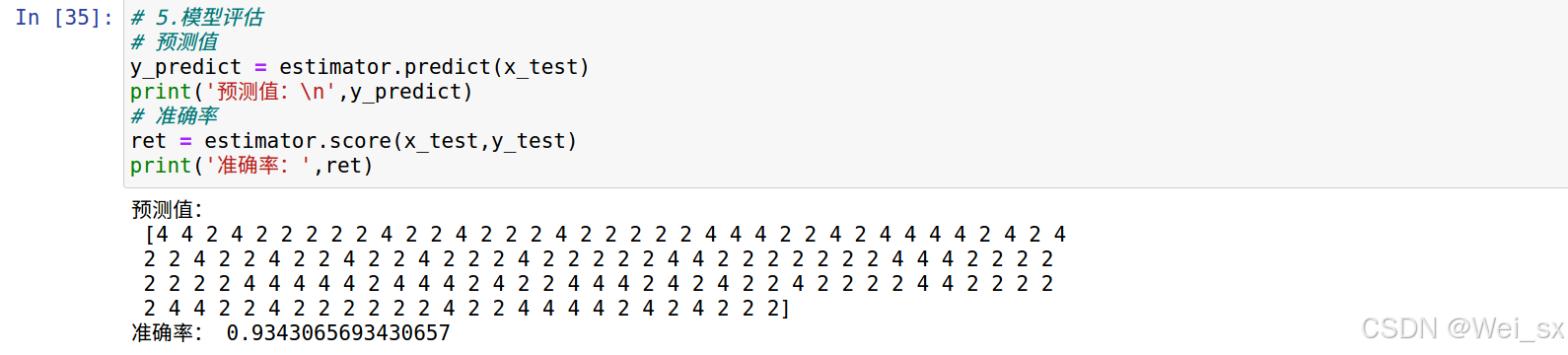
3. 主要参数
`LogisticRegression` 类具有多个重要参数,用于调整模型性能。
`penalty`: 指定正则化类型,选项包括 'none'(无正则化)、'l2'(Ridge 正则化,默认)、'l1'(Lasso 正则化)、'elasticnet'(弹性网,需指定 `solver='saga'`)。
`C`: 正则化强度的倒数。较小的值表示强正则化。
`solver`: 优化算法选择,包括 'liblinear'、'newton-cg'、'lbfgs'、'saga' 和 'sgd'。
`max_iter`: 最大迭代次数。
`multi_class`: 多类别策略,选项包括 'auto'、'ovr'(一对其余)、'multinomial'(需指定 `solver='lbfgs'` 或 `solver='newton-cg'`)。
`fit_intercept`: 是否计算截距,默认值为 True。
4. 模型评估
评估 `LogisticRegression` 模型通常包括以下步骤:
准确率: 衡量模型正确分类的比例。
混淆矩阵: 显示 True Positive、True Negative、False Positive 和 False Negative 的数量,提供更详细的分类性能。
分类报告: 包含精确率、召回率和 F1 分数的详细信息。
5. 应用案例
医学: 用于诊断预测(如癌症检测)。
金融: 信贷评分与欺诈检测。
市场营销: 客户保留预测与客户细分。
6. 总结
`LogisticRegression` 是一种高效且可解释的分类模型,特别适用于二元分类问题,并可通过适当的配置扩展到多类问题。其简单的实现及良好的可解释性使其在许多领域应用广泛。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











