







目录
一、概述
前面一篇文章我们总结了如何在linux中搭建zookeeper集群,并且可以看到三台服务器分别启动后,zookeeper内部会自动选举出一个leader领导者,其他两台服务器都是作为follower跟随者角色存在,那么,zookeeper内部具体是如何选举产生这个leader的呢?本篇我们文章我们就将一一分析。
二、zab协议
zab协议的全称是 Zookeeper Atomic Broadcast,即Zookeeper原子广播。Zookeeper是通过 zab协议来保证分布式事务的最终一致性。
Zookeeper 使用一个单一主进程来接收并处理客户端的所有事务请求,即写请求。当服务器数据的状态发生变更后,集群采用 ZAB 原子广播协议,以事务提案 Proposal 的形式广播到所有的副本进程上。ZAB 协议能够保证一个全局的变更序列,即可以为每一个事务分配一个全局的递增编号 xid。
当Zookeeper 客户端连接到 Zookeeper 集群的一个节点后,若客户端提交的是读请求, 那么当前节点就直接根据自己保存的数据对其进行响应;
如果是写请求且当前节点不是 Leader,那么节点就会将该写请求转发给 Leader,Leader 会以提案的方式广播此次写操作,只要有超过半数节点同意该写操作,则该写操作请求就会被提交。然后 Leader 会再次广播给所有订阅者,即 Learner,通知它们同步数据。
基于zab协议,zookeeper集群中的角色主要有以下三类:
- (1)、Leader:zk 集群写请求的唯一处理者,并负责进行投票的发起和决议,更新系统状态。 Leader 是很民主的,并不是说其在接收到写请求后马上就修改其中保存的数据,而是首先根据写请求提出一个提议,在大多数 zkServer 均同意时才会做出修改。
- (2)、Follower:接收客户端请求,处理读请求,并向客户端返回结果;将写请求转给Leader,在选 Leader过程中参与投票。
- (3)、Observer:可以理解为无leader选举投票权与写操作投票权的 Flollower,主要是为了协助Follower 处理更多的读请求。如果 Zookeeper 集群的读请求负载很高时,势必要增加处理读请求的服务器数量。若增加的这些服务器都是以 Follower 的身份出现,则会大大降低写操作的效率。因为 Leader 发出的所有写操作提议,均需要通过半数以上同意。过多的 Follower 会增加 Leader 与Follower 的通信压力,降低写操作效率。同样,过多的 Follower 会延长 Leader 的选举时长,降低整个集群的可用性。此时,可选择增加 Observer 服务器,既提高了处理读操作的吞吐量,也不会延长leader选举的时间。
zab广播模式工作原理,类似于两阶段提交协议的方式解决数据一致性:
- 1. leader从客户端收到一个写请求;
- 2. leader生成一个新的事务并为这个事务生成一个唯一的ZXID;
- 3. leader将这个事务提议(propose)发送给所有的follower节点;
- 4. follower节点将收到的事务请求加入到历史队列(history queue)中,并发送ack给leader;
- 5. 当leader收到大多数follower(半数以上节点)的ack消息,leader会发送commit请求;
- 6. 当follower收到commit请求时,从历史队列中将事务请求进行commit提交;
三、Zookeeper的leader选举
在分析zookeeper的leader选举流程之前,我们先了解一下zookeeper中几种服务器状态:
- looking:寻找leader状态,当服务器处于该状态时,它会认为当前集群中没有leader,因此需要进入leader选举状态;
- leading: 领导者状态,表明当前服务器角色是leader;
- following: 跟随者状态,表明当前服务器角色是follower;
- observing:观察者状态,表明当前服务器角色是observer;
zookeeper触发选举的情况有两种:
- (1)、服务器启动时期的leader选举
在集群中的服务器初始化启动阶段,当有一台服务器server1启动时,其单独无法进行和完成leader选举,当第二台服务器server2启动时,此时两台机器可以相互通信,每台机器都试图找到leader,于是进入leader选举过程。选举过程如下:
- 1、第一轮投票,每个服务器发起一个投票,因为都是第一次启动,server1和server2都会将票投给自身,认为自己是leader,投票信息中包含服务器的myid和zxid(事务ID),使用(myid, zxid)表示,所以第一轮投票情况:server1: (1,0) server2:(2,0)。然后各自将这个投票发给集群中其他机器。
- 2、server1接收到serve2发送过来的投票信息:(2,0); server2接收到server1发送过来的投票信息: (1,0)。
- 3、zookeeper统计第一轮投票信息,针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK,PK的规则如下:
- 优先比较zxid(事务ID),zxid比较大的服务器优先作为leader服务器;
- 如果zxid相同,那么会进行比较myid(服务器ID),myid较大的服务器优先作为leader服务器;
对于Server1而言,它自己的投票信息是(1, 0),接收Server2的投票信息为(2, 0),首先比较两者的zxid,因为都是第一次启动,所以zxid相同,都为0。然后再对比myid,此时server2的myid比server1的大,于是server1服务器会更新自己的投票为(2, 0),然后重新投票。
对于Server2而言,因为myid比server1大,所以无需修改自己的投票信息,只是再次向集群中的所有机器发出上一次的投票信息。
- 4、zookeeper统计投票,每次投票后,服务器都会统计投票信息,判断是否已经有过半数的服务器接受相同的投票信息,对于server1、server2而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,超过了半数,所以已经选出了leader: server2。
- 5、服务器改变自己的状态,一旦确定了leader,每个服务器就会更新自己的服务器状态,如果是follower跟随者角色,那么就变更为following,如果是leader领导者,就变更为leading。
- 6、server3服务器启动,因为前面已经确定server2作为leader角色,所以尽管server3的myid比server2还大,server3依然还是follower跟随者角色。
下面我们演示一下服务器启动时的leader选举过程:
依次启动192.168.179.128、192.168.179.129、192.168.179.133三台服务器的zookeeper:
[root@zookeeper data]# cd /usr/local/zookeeper-3.4.14/bin/
[root@zookeeper bin]# ll
total 60
-rwxr-xr-x. 1 2002 2002 232 Mar 7 2019 README.txt
-rwxr-xr-x. 1 2002 2002 1937 Mar 7 2019 zkCleanup.sh
-rwxr-xr-x. 1 2002 2002 1056 Mar 7 2019 zkCli.cmd
-rwxr-xr-x. 1 2002 2002 1534 Mar 7 2019 zkCli.sh
-rwxr-xr-x. 1 2002 2002 1759 Mar 7 2019 zkEnv.cmd
-rwxr-xr-x. 1 2002 2002 2919 Mar 7 2019 zkEnv.sh
-rwxr-xr-x. 1 2002 2002 1089 Mar 7 2019 zkServer.cmd
-rwxr-xr-x. 1 2002 2002 6773 Mar 7 2019 zkServer.sh
-rwxr-xr-x. 1 2002 2002 996 Mar 7 2019 zkTxnLogToolkit.cmd
-rwxr-xr-x. 1 2002 2002 1385 Mar 7 2019 zkTxnLogToolkit.sh
-rw-r--r--. 1 root root 12994 Dec 25 17:08 zookeeper.out
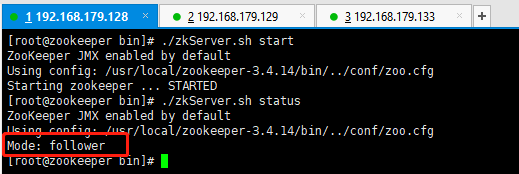
[root@zookeeper bin]# ./zkServer.sh start192.168.179.128:
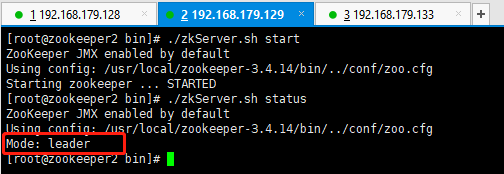
192.168.179.129:
192.168.179.133:
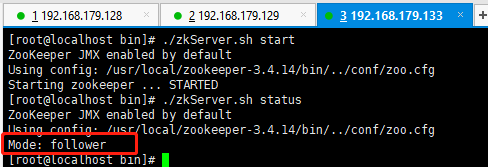
如上我们可以看到,129这台服务器目前是leader角色,其他两台服务器128、133都是follower角色,同时也验证了上面我们说的服务器启动过程的leader选举流程。
注意:关闭或者禁用防火墙,否则可能遇到如下图错误。
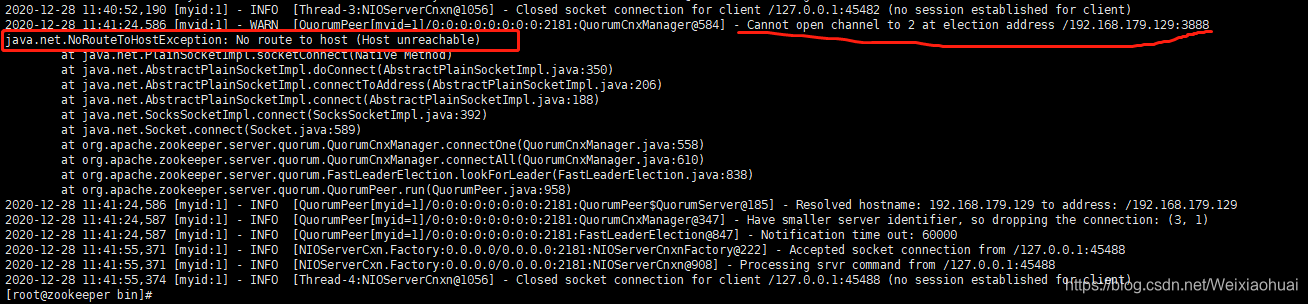
可以通过下面的方式停止或者禁用掉防火墙:
systemctl stop firewalld.service
systemctl disable firewalld.service- (2)、服务器运行时期的Leader选举
在zookeeper运行期间,leader与非leader服务器各司其职,即便当有非leader服务器宕机或新加入一台机器,此时也不会影响leader,但是一旦leader服务器挂了,那么整个集群将暂停对外服务,进入新一轮leader选举,其过程和启动时期的Leader选举过程基本一致。
假设正在运行的有server1、server2、server3三台服务器,当前leader是server2,若某一时刻leader挂了,此时便开始Leader选举。选举过程如下:
- 1、当leader节点出现宕机时,此时集群中的其他节点第一时间变更服务器状态,余下的服务器都会将自己的服务器状态变更为looking,然后开始进入leader的选举过程。
- 2、余下的服务器都会发起一个投票,在运行期间,因为涉及到读写操作,所以每台服务器的zxid(事务ID)可能不同,此时假设server1的zxid为150,server3的zxid为150,那么在第一轮投票中,server1以及server3都会将票投给自己先,即server1的投票信息为:(1,150),server3的投票信息为:(3,150)。
- 3、server1将自己的投票信息(1,150)发给server3,同时server3将自己的投票信息(3,150)发给server2。
- 4、接收来自各个服务器发送过来的投票信息。
- 5、zookeeper统计第一轮投票信息,针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK,PK的规则如下:
- 优先比较zxid(事务ID),zxid比较大的服务器优先作为leader服务器;
- 如果zxid相同,那么会进行比较myid(服务器ID),myid较大的服务器优先作为leader服务器;
因为server1与server3的zxid相同,所以会比较myid,显然server3的myid大,所以server1会将自己的投票信息变更为(3,150),然后重新投票。
所以将会选举出server3作为新的leader。
- 6、zookeeper统计投票,每次投票后,服务器都会统计投票信息,判断是否已经有过半数的服务器接受相同的投票信息,对于server1、server3而言,都统计出集群中已经有两台机器接受了(3,150)的投票信息,超过了半数,所以已经选出了leader: server3。
- 7、服务器改变自己的状态,一旦确定了leader,每个服务器就会更新自己的服务器状态,如果是follower跟随者角色,那么就变更为following,如果是leader领导者,就变更为leading。
下面我们模拟leader节点发生宕机,演示zookeeper服务器运行时期的leader选举过程:
因为前面我们的192.168.179.129是leader角色,下面我们模拟129发生宕机现象,触发服务器运行时期的Leader选举。
[root@zookeeper2 bin]# ./zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.14/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED然后我们查看192.168.179.128、192.168.179.133这两台服务器的当前角色:
192.168.179.128:
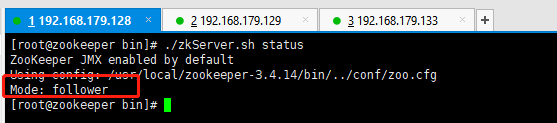
192.168.179.133:
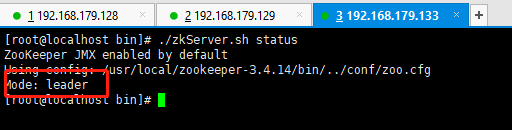
如上我们可以看到,当原先leader节点发生宕机时,zookeeper内部会重新进行选举,因为133的myid比128的大(前提是zxid相同的情况下),所以192.168.179.133优先作为leader角色。
假设某个时刻,之前宕机的192.168.179.129机器又正常了,那么它会是leader还是follower角色呢?
下面我们来验证一下:
重新启动129的zookeeper服务:
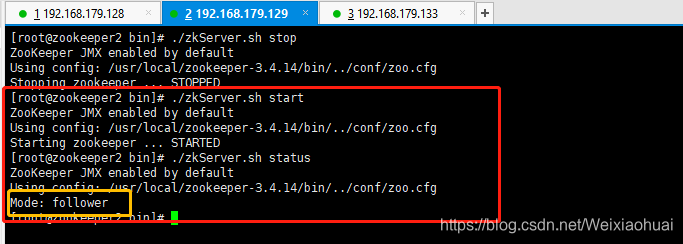
如上可见,重新启动之后,129变为了follower角色,133还是leader角色。
四、总结
本篇文章我们主要总结了Zookeeper集群中leader的选举机制,并通过详细的案例说明了leader的选举过程,建议小伙伴们自己动手搭建一个zookeeper集群,这样有利于更好的理解它的选举流程。

















 160
160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









