







创建一个代码文件GeneratePeopleAge.scala
1.
cd src/main/scala2.vim GeneratePeopleAge.scala
在“/usr/local/spark/mycode/exercise/peopleage”目录下新建一个 simple.sbt文件,用来 支持sbt打包编译,命令如下:
1.
cd /usr/local/spark/mycode/exercise/peopleage2.vim simple.sbt
在simple.sbt文件中输入如下内容
name := "Simple Project"
version := "1.0"scalaVersion := "2.11.8"libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
编译打包
/usr/local/sbt/sbt package
使用如下命令运行程序
1.
cd /usr/local/spark/mycode/exercise/peopleage2./usr/local/spark/bin/spark-submit \3.> --class "GeneratePeopleAge" \4.> /usr/local/spark/mycode/exercise/peopleage/target/scala-2.11/simple-project_2.11-1.0.jar
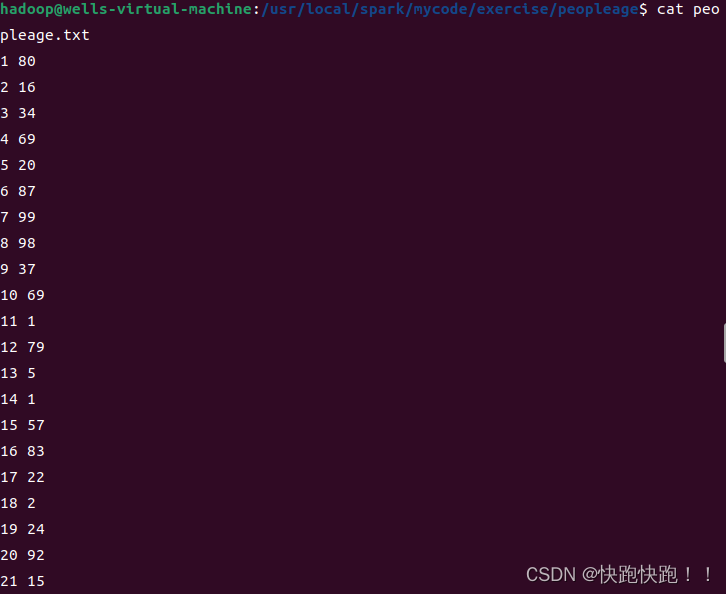
执行结束以后,可以看到,已经生成了数据文件 “/usr/local/spark/mycode/exercise/peopleage/peopleage.txt”。
可以使用如下命令查看文件内容:
1.
cd /usr/local/spark/mycode/exercise/peopleage2.cat peopleage.txt

创建代码文件CountAvgAge.scala,命令如下:
1.
cd /usr/local/spark/mycode/exercise/peopleage2.cd src/main/scala3.vim CountAvgAge.scala
在CountAvgAge.scala代码文件中输入如下代码:
//CountAvgAge.scalaimport org.apache.spark.SparkConfimport org.apache.spark.SparkContextobject CountAvgAge{def main(args:Array[String]){if (args.length<1){println("Usage: CountAvgAge inputdatafile")System.exit(1)}val conf = new SparkConf().setAppName("Count Average Age")val sc = new SparkContext(conf)val lines = sc.textFile(args(0),3)val count = lines.count()val totalAge = lines.map(line=>line.split(" ")(1)).map(t=>t.trim.toInt).collect().reduce((a,b)=>a+b)println("Total Age is: "+totalAge+"; Number of People is:"+count)val avgAge : Double = totalAge.toDouble / count.toDoubleprintln("Average Age is:"+avgAge)}}
/usr/local/sbt/sbt package
运行程序
1.
cd /usr/local/spark/mycode/exercise/peopleage2./usr/local/spark/bin/spark-submit \3.> --class "CountAvgAge" \4.> /usr/local/spark/mycode/exercise/peopleage/target/scala-2.11/simple-project_2.11-1.0.jar \5.> file:///usr/local/spark/mycode/exercise/peopleage/peopleage.txt

1.cd /usr/local/hadoop2../sbin/start-dfs.sh
启动结束后,使用如下命令,查看是否启动成功:
1.jps
如果可以看到DataNode、NameNode和SecondaryNameNode三个进程,就说明启动成功了。
然后,就可以编写Spark程序,向HDFS中写入一个数据文件,命令如下:
1.
cd /usr/local/spark/mycode/exercise/peopleage2.cd src/main/scala3.vim GeneratePeopleAgeHDFS.scala
在GeneratePeopleAgeHDFS.scala代码文件中输入下以下代码:
import org.apache.spark.SparkContextimport org.apache.spark.SparkContext._import org.apache.spark.SparkConfimport scala.util.Randomobject GeneratePeopleAgeHDFS {def main(args: Array[String]) {val outputFile = "hdfs://localhost:9000/user/hadoop/peopleage.txt"//val outputFile1 = "file:///usr/local/spark/mycode/exercise/peoplea ge/peopleage1.txt"val conf = new SparkConf().setAppName("GeneratePeopleAgeHDFS").setMaster("local[2]")val sc = new SparkContext(conf)val rand = new Random()val array = new Array[String](1000)for (i<-1 to 1000){array(i-1)=i+" "+rand.nextInt(100)}val rdd = sc.parallelize(array)rdd.foreach(println)rdd.saveAsTextFile(outputFile)}}
下面,在这个目录下/usr/local/spark/mycode/exercise/peopleage使用sbt编译打包工具对代码文件进行编译打包,命令如下:
/usr/local/sbt/sbt package
打包成功以后,可以使用如下命令运行程序,生成数据文件:
1.
cd /usr/local/spark/mycode/exercise/peopleage2./usr/local/spark/bin/spark-submit \3.> --class "GeneratePeopleAgeHDFS" \4.> /usr/local/spark/mycode/exercise/peopleage/target/scala-2.11/simple-project_2.11-1.0.jar
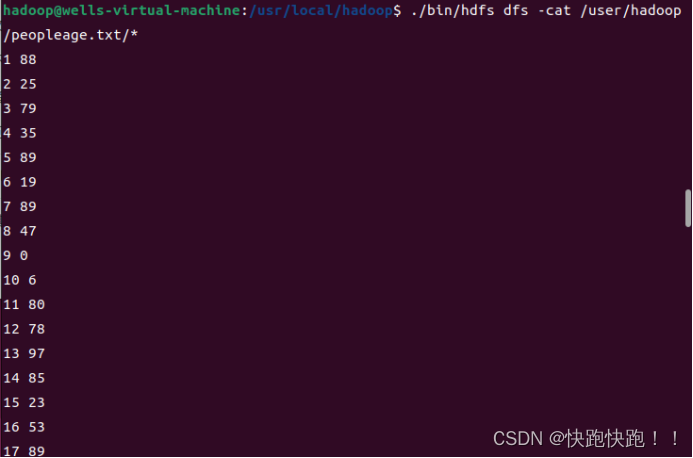
执行结束以后,可以看到,已经生成了数据文件peopleage.txt,这个文件是在HDFS中,可以使用如下命令查看文件内容:
1.
cd /usr/local/hadoop2../bin/hdfs dfs -cat /user/hadoop/peopleage.txt/*

cd /usr/local/spark/mycode/exercise/peopleage
/usr/local/spark/bin/spark-submit \
--class "CountAvgAge" \
/usr/local/spark/mycode/exercise/peopleage/target/scala-2.11/simple-project_2.11-1.0.jar \
/user/hadoop/peopleage.txt

















 1073
1073











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









