






论文介绍 FreeControl: 无需额外训练实现文本到图像的空间操控!
论文介绍 FreeControl: Training-Free Spatial Control of Any Text-to-Image Diffusion Model with Any Condition
关注微信公众号: DeepGoAI
项目地址:https://genforce.github.io/freecontrol/
论文地址:https://arxiv.org/abs/2312.07536
本文介绍一种新颖的图像编辑算法FreeControl,允许用户在不需要额外训练的情况下,对预训练的文本到图像(T2I)扩散模型进行空间控制。它通过分析和合成两个阶段工作,首先从目标概念生成种子图像,并对它们的扩散特征进行主成分分析(PCA)以获得线性子空间作为语义基础。然后,在合成阶段,使用结构引导和外观引导来确保生成的图像在结构上与指导图像一致,同时在外观上与同一种子未进行结构控制生成的图像相似。

上图展示了 FreeControl 方法如何实现对(Stable Diffusion)稳定扩散模型的无训练条件控制。此图分为两个部分(a)和(b),演示了 FreeControl 如何在给定任何模态的输入条件图像下,实现对预训练文本到图像扩散模型的零样本控制。 (a)部分:说明了 FreeControl 如何允许用户在没有任何额外训练的情况下,对预训练的文本到图像扩散模型进行空间控制。这一点突出了 FreeControl 在处理输入条件和文本描述之间存在冲突时,如何在空间和图像-文本对齐之间实现良好平衡的能力。它支持一些难以构造训练对的条件类型(例如,借用行中的 2D 点云和网格投影)。 (b)部分:与 ControlNet 相比,FreeControl 在处理引导图像和文本描述之间存在冲突的情况下,实现了空间和图像-文本对齐之间的良好平衡。此外,它支持多种条件类型,例如 2D 投影的点云和网格,在这些情况下,构建训练对是困难的。
问题、挑战和贡献
该论文尝试解决的主要问题和挑战是如何在不需要额外训练的情况下,为预训练的文本到图像(T2I)扩散模型提供精细的空间控制。现有的方法,如ControlNet,虽然能够提供空间控制,但需要为每种空间条件、模型架构和模型文件训练额外的模块,这既耗时又费力,且难以适应不断演变的模型架构和个性化的模型。此外,这些方法面临高训练成本、可扩展性差和由训练方案导致的限制,如控制信号难以从图像中推断、模型倾向于优先考虑空间条件而非文本描述等问题。
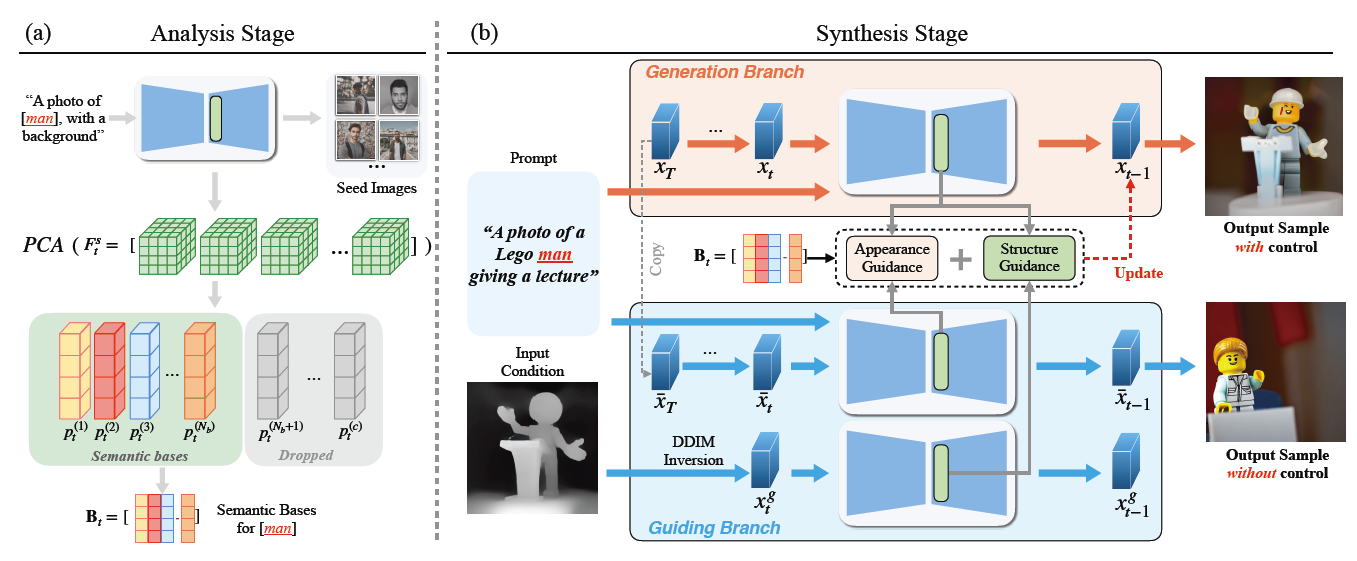
上图提供了 FreeControl 方法的概述,展示了如何在无需额外训练的情况下,对任何预训练的文本到图像(T2I)扩散模型进行控制。该图分为两个主要部分:分析阶段(a)和合成阶段(b),展示了从目标概念(例如,“man”)生成种子图像到最终生成具有控制结构和外观的图像的整个过程。 (a) 分析阶段:在此阶段,FreeControl 使用预训练的扩散模型为目标概念生成种子图像,并对这些图像的扩散特征执行主成分分析(PCA)。通过这种分析,获得了作为语义基础的线性子空间。这一步骤的关键是构建一个时间依赖的基础
B
t
B_t
Bt,代表语义结构。 (b) 合成阶段:在此阶段,FreeControl 利用结构引导和外观引导来生成最终图像。结构引导使用在分析阶段得到的语义基础,确保生成图像在结构上与输入条件图像对齐。同时,外观引导促进从相同种子但未经结构控制生成的兄弟图像(
I
ˉ
\bar{I}
Iˉ)到最终图像(
I
I
I)的外观转移,使得
I
I
I 在内容和风格上与
I
ˉ
\bar{I}
Iˉ 相似,但结构上遵循输入条件图像(
I
g
I_g
Ig)。
方法概述
FreeControl 分为两个阶段:分析阶段和合成阶段。
- 分析阶段:通过对种子图像的扩散特征进行主成分分析(PCA),形成时间依赖的基 B t B_t Bt,作为语义结构表示。
- 合成阶段:结构引导帮助在引导图像 I g I_g Ig的指导下构建输出图像 I I I的结构模板,而外观引导从相同种子生成的兄弟图像 I ˉ \bar{I} Iˉ中借用外观细节。
语义结构表示
在实现文本到图像(T2I)扩散的零样本空间控制时,关键在于需要一种对图像模态不变的语义图像结构的统一表示。根据最近的研究,自监督的 Vision Transformers 和 T2I 扩散模型中的自注意力特征(即键和查询)被认为是图像结构的强大描述符。因此,作者假设操纵这些自注意力特征是实现可控 T2I 扩散的关键。
-
直接注入方法的局限性: 在 Plug-and-Play(PnP)方法中,尝试直接将引导图像( I g I_g Ig)的自注意力权重(或等效的特征)注入到图像 I I I 的扩散过程中。这种方法容易引入外观泄漏,即不仅传递了 I g I_g Ig 的结构,还传递了外观细节的痕迹,特别是当 I g I_g Ig 和 I I I 属于不同模态时(例如,深度图与自然图像),这在可控生成中是一个问题。
-
图像结构与外观的分离:
为了分离图像的结构和外观,作者借鉴了 Transformer 特征可视化的方法,对一组语义相似图像的自注意力特征执行主成分分析(PCA)。作者的关键观察是,主要的 PCs 形成了一个语义基础;它与不同图像模态中的对象姿态、形状和场景构成表现出强烈的相关性。作者利用这个基础作为语义结构表示,并在分析阶段获得这些基础。 -
语义基础的获取:
首先收集一组 N s N_s Ns 张图像 { I s } \{I_s\} {Is},这些图像与文本提示 c c c 共享目标概念,使用经文本提示 c ~ \tilde{c} c~ 修改后的 ϵ θ \epsilon_\theta ϵθ 生成, c ~ \tilde{c} c~ 将概念标记插入到故意保持通用的模板中(例如,“一张带背景的[]照片。”)。这使得 { I s } \{I_s\} {Is} 覆盖了多样的对象形状、姿态、外观以及图像构成和风格,对于语义基础的表达性至关重要。
通过对 { I s } \{I_s\} {Is} 执行 DDIM 逆向,以获得大小为 N s × C × H × W N_s \times C \times H \times W Ns×C×H×W 的时间依赖扩散特征 { F t s } \{F_{t}^s\} {Fts},产生 N s × H × W N_s \times H \times W Ns×H×W 个不同的特征向量,对其执行 PCA 以获得时间依赖的语义基础 B t B_t Bt 作为前 N b N_b Nb 个主成分:
B t = [ p t ( 1 ) , p t ( 2 ) , … , p t ( N b ) ] ∼ P C A ( { F t s } ) B_t = [p^{(1)}_t, p^{(2)}_t, \ldots, p^{(N_b)}_t] \sim PCA(\{F_{t}^s\}) Bt=[pt(1),pt(2),…,pt(Nb)]∼PCA({Fts})直观地讲, B t B_t Bt 跨越了不同图像模态的语义空间 S t S_t St,允许在合成阶段将图像结构从 I g I_g Ig 传播到 I I I。
一旦计算出来, B t B_t Bt 可以被相同的文本提示重复使用,或由具有相关概念的提示共享。因此,基础构建的成本可以在合成阶段的多次运行中分摊。
生成阶段
合成阶段通过引导将生成的图像 I I I与引导图像 I g I_g Ig进行条件化。首先,作者用语义基础 B t B_t Bt表达 I g I_g Ig的语义结构。(ps: 原文的公式不知为何都在表达的时候,将大写字母成了小写,如M写成m,注意区分)
-
引导图像的逆变换:
作者对 I g I_g Ig执行DDIM逆变换,以获取尺寸为 C × H × W C \times H \times W C×H×W的扩散特征 F t g F_{t}^g Ftg,并将其投影到 B t B_t Bt上,得到其语义坐标 S t g S_{t}^g Stg,尺寸为 N b × H × W N_b \times H \times W Nb×H×W。为了局部控制前景结构,作者进一步从概念标记的交叉注意力图中派生出掩码 M M M(尺寸 H × W H \times W H×W),全局控制时 M M M设置为1(尺寸 H × W H \times W H×W)。接下来介绍如何使用结构引导来生成具有控制结构的 I I I。
-
结构引导:
在每个去噪步骤 t t t,作者通过将扩散特征 F t F_t Ft从 ϵ θ \epsilon_\theta ϵθ投影到 B t B_t Bt上,获得语义坐标 S t S_t St。结构引导的能量函数 g s g_s gs可以表达为:
g s ( S t ; S t g , M ) = ∑ i , j m i j ∥ [ s t ] i j − [ s t g ] i j ∥ 2 2 ∑ i , j m i j + w ⋅ ∑ i , j ( 1 − m i j ) ∥ max ( [ s t ] i j − τ t , 0 ) ∥ 2 2 ∑ i , j ( 1 − m i j ) g_s(S_t; S_{t}^g, M) = \frac{\sum_{i,j} m_{ij} \left\| [s_t]_{ij} - [s_{t}^{g}]_{ij} \right\|^2_2}{\sum_{i,j} m_{ij}} + w \cdot \frac{\sum_{i,j} (1 - m_{ij}) \left\| \max([s_t]_{ij} - \tau_t, 0) \right\|^2_2}{\sum_{i,j} (1 - m_{ij})} gs(St;Stg,M)=∑i,jmij∑i,jmij∥[st]ij−[stg]ij∥22+w⋅∑i,j(1−mij)∑i,j(1−mij)∥max([st]ij−τt,0)∥22其中, i i i和 j j j是 S t S_t St、 S t g S_{t}^g Stg和 M M M的空间索引, w w w是平衡权重。阈值 τ t \tau_t τt定义为:
τ t = max i j s.t. m i j = 0 [ s g t ] i j \tau_t = \max_{ij \text{ s.t. } m_{ij} = 0} [s_{gt}]_{ij} τt=ij s.t. mij=0max[sgt]ij
直观来说, [ s t ] i j > τ t [s_t]_{ij} > \tau_t [st]ij>τt表明前景结构的存在。直观上,前向项引导 I I I的结构与 I g I_g Ig在前景中对齐,而当 M ≠ 1 M \neq 1 M=1时,后向项通过抑制背景中的假结构来帮助雕刻出前景。
-
外观引导:
受DSG启发,作者将图像外观表示为 { v t ( k ) } k = 1 N a ≤ N b \{v_t^{(k)}\}_{k=1}^{N_a \leq N_b} {vt(k)}k=1Na≤Nb,即扩散特征 F t F_t Ft的加权空间均值:
v t ( k ) = ∑ i , j σ ( [ s t ( k ) ] i j ) [ f t ] i j ∑ i , j σ ( [ s t ( k ) ] i j ) v_t^{(k)} = \frac{\sum_{i,j} \sigma([s_t^{(k)}]_{ij}) [f_t]_{ij}}{\sum_{i,j} \sigma([s_t^{(k)}]_{ij})} vt(k)=∑i,jσ([st(k)]ij)∑i,jσ([st(k)]ij)[ft]ij
其中, i i i和 j j j是 S t S_t St和 F t F_t Ft的空间索引, k k k是 [ s t ] i j [s_t]_{ij} [st]ij的通道索引, σ \sigma σ是Sigmoid函数。作者将 S t S_t St用作权重,以便不同的 v t ( k ) v_t^{(k)} vt(k)编码不同语义组件的外观。对于 I I I和 I ˉ \bar{I} Iˉ,作者在每个时间步骤 t t t分别计算 { v t ( k ) } \{v_t^{(k)}\} {vt(k)}和 { v ˉ t ( k ) } \{\bar{v}_t^{(k)}\} {vˉt(k)}。
外观引导的能量函数 g a g_a ga可以表达为:
g a ( { v t ( k ) } ; { v ~ t ( k ) } ) = ∑ k = 1 N a ∥ v t ( k ) − v ~ t ( k ) ∥ 2 N a , g_a\left(\left\{v_t^{(k)}\right\}; \left\{\tilde{v}_t^{(k)}\right\}\right) = \frac{\sum_{k=1}^{N_a} \left\| v_t^{(k)} - \tilde{v}_t^{(k)} \right\|^2}{N_a}, ga({vt(k)};{v~t(k)})=Na∑k=1Na vt(k)−v~t(k) 2,它惩罚外观表示之间的差异,从而促进从 I ˉ \bar{I} Iˉ到 I I I的外观转移。
(DSG: Diffusion self-guidance for controllable image generation) -
引导生成过程:
最后,作者通过结构和外观引导以及无分类器引导,得到修改后的分数估计 ϵ ^ t \hat{\epsilon}_t ϵ^t:ϵ ^ t = ( 1 + s ) ϵ θ ( x t ; t , c ) − s ϵ θ ( x t ; t , ∅ ) + λ s g s + λ a g a \hat{\epsilon}_t = (1+s) \epsilon_\theta(x_t; t, c) - s \epsilon_\theta(x_t; t, \emptyset) + \lambda_s g_s + \lambda_a g_a ϵ^t=(1+s)ϵθ(xt;t,c)−sϵθ(xt;t,∅)+λsgs+λaga
其中, s s s、 λ s \lambda_s λs和 λ a \lambda_a λa是各自引导的强度。
实验结果

上图展示了 FreeControl 在支持多种控制信号和三个主要版本的 Stable Diffusion 模型下,生成的图像如何紧密遵循文本提示,同时展示了与输入图像的强烈空间对齐。这突显了 FreeControl 在各种条件下的适用性和效果。
总结
FreeControl支持多种控制条件、模型架构和自定义模型文件,能够处理大多数现有无训练方法失败的挑战性输入条件,并且与基于训练的方法相比,实现了竞争性的合成质量。通过在多个预训练的T2I模型上的广泛定性和定量实验,FreeControl展示了其优越的性能。
尽管它依赖于DDIM逆转过程来提取指导图像的中间特征和计算合成阶段的额外梯度,这导致了推理时间的增加。希望这项工作能为可控的视觉内容创作提供新的见解和分析。
更多细节请参阅论文原文


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









