






论文介绍 EXE-GAN: 基于范例引导的高质量生成式人脸修复框架
关注微信公众号: DeepGoAI
源码地址: https://github.com/LonglongaaaGo/EXE-GAN
论文地址: https://arxiv.org/abs/2202.06358
本文介绍了一种创新性的图像修复框架 EXE-GAN,专为生成式人脸修复设计,允许用户通过范例引导,在无需额外训练的情况下完成高质量的面部修复任务。EXE-GAN 的核心创新在于结合了输入图像的全局风格、随机生成的风格,以及范例图像的风格,同时通过交叉注意力引导确保修复结果在视觉上真实自然。与现有方法相比,EXE-GAN 能在多种任务和条件下表现出卓越的修复效果。

图 1. 展示了人脸修复的示例。前两行:从带遮罩的输入图像(左上角子图)开始,我们的方法逐步编辑眼睛风格(左侧)、嘴巴风格(中间偏左)、发型(中间)和整体面部风格(右侧),这些均由范例图像引导生成。发型可以通过插入简单的草图进行编辑(中间)。真实照片和艺术风格的人脸照片均可用于指导局部修复区域的(混合)面部特征,而不影响图像其他未编辑区域的视觉内容。最后一行:对于佩戴眼镜和口罩遮挡的人像,我们通过范例图像实现了引导式人脸图像恢复。
问题、挑战与贡献
EXE-GAN 针对当前人脸修复任务中的实际挑战提出了创新解决方案。这些挑战包括:
-
挑战 1:复杂的修复场景
面部修复任务中,常常涉及被遮挡的区域(如眼镜、口罩等)或需要对特定区域(如发型、表情等)进行编辑,而传统方法难以同时保证结构一致性和视觉自然性。 -
挑战 2:对范例特征的精准引导
如何在保留输入图像整体风格的前提下,有效地将范例的局部风格特征引入修复图像,是一个关键难题。简单的特征混合可能导致过多信息泄露或引入不相关的细节。 -
挑战 3:自然的边界过渡
修复区域与未编辑区域之间的边界常出现割裂感,如何在修复过程中保证平滑过渡,同时避免边界的人工痕迹,是另一个亟待解决的问题。
EXE-GAN 的贡献:
- 精准的多风格融合
EXE-GAN 引入多风格生成器,结合输入图像、随机风格和范例风格,通过动态风格调制生成修复区域,实现了风格一致性和局部特征引导的有效融合。
- 自监督属性相似性度量
提出了一个自监督的属性相似性度量方法,确保修复区域与范例图像特征一致,同时最大程度避免信息过载或风格冲突。
- 自然的空间过渡机制
采用空间变异梯度反向传播(SVGL)技术,通过调整修复区域和背景区域的梯度权重,实现了修复边界的平滑过渡和视觉一致性。
EXE-GAN 在 CelebA-HQ 和 FFHQ 数据集上的实验结果表明,其在复杂修复任务中表现出了卓越的性能,并能够以高效方式处理多样化的场景和输入条件。
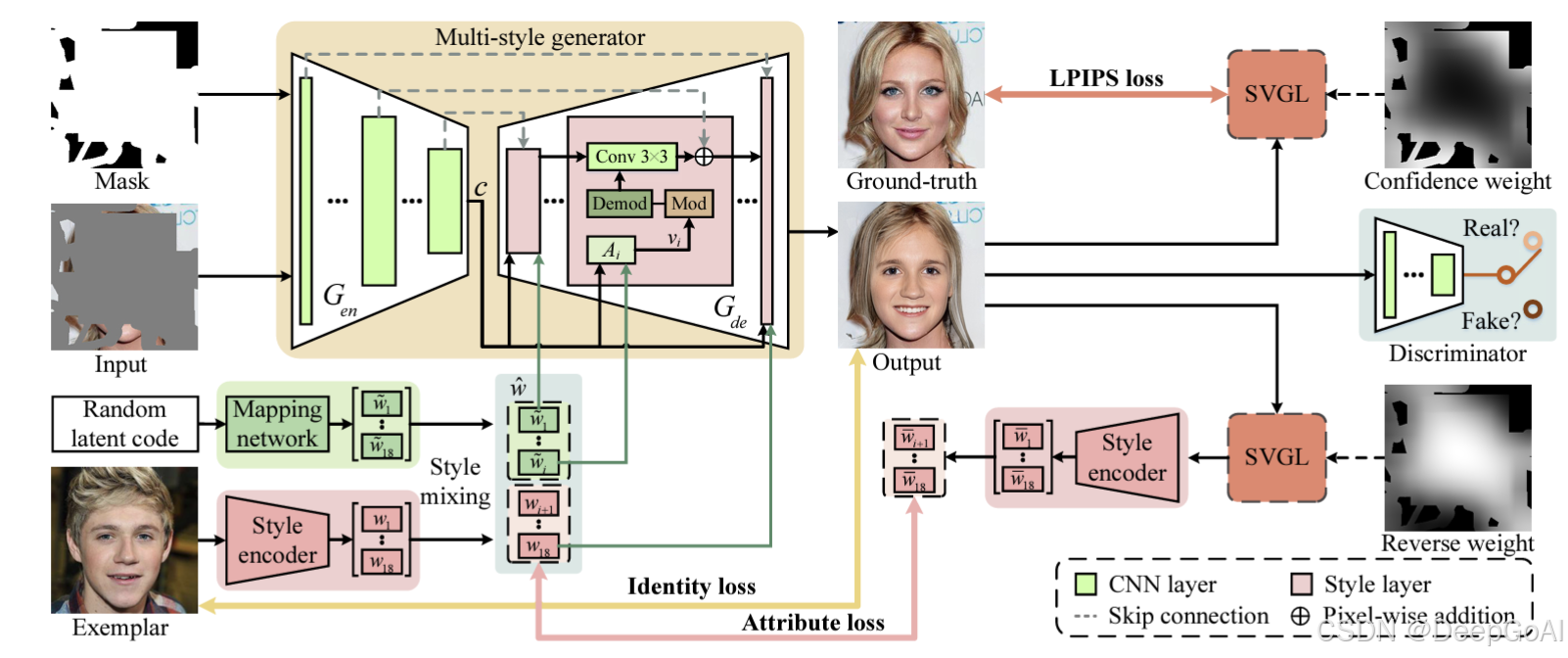
方法概述
EXE-GAN 的方法包括两个关键阶段:特征分析和生成阶段。
-
特征分析阶段
EXE-GAN 通过映射网络和风格编码器提取输入图像和范例图像的风格特征,同时生成一个多风格表示。该阶段的主要任务是:
- 映射网络:生成随机风格代码,增强模型的生成能力。
- 风格编码器:提取范例图像的解耦风格特征,用于局部区域修复。
-
生成阶段
EXE-GAN 的生成阶段通过创新的多风格生成器和自监督属性相似性度量,确保修复图像既保留输入图像的结构,又能从范例中引入细节风格。其核心技术包括:
- 多风格调制:通过混合输入图像的全局风格、随机风格以及范例的特定风格,生成图像中的局部修复区域能够继承范例的特性。
- 属性相似性度量:在生成过程中,通过一个新颖的自监督属性相似性度量,保证修复图像与范例图像的风格特性一致,同时避免引入不相关的细节。
- 空间变异梯度反向传播(SVGL):通过在训练过程中调整梯度传播,使得修复区域与背景区域过渡自然,不产生明显的边界痕迹。
核心方法
提出的EXE-GAN 框架通过随机样式与示例样式的混合,并结合输入图像的全局样式,对多样式生成器进行调制,以实现面部修复。训练过程中,综合使用对抗损失(Adversarial Loss)、身份损失(Identity Loss)、LPIPS 感知损失和属性损失(Attribute Loss)作为总体优化目标。同时,引入空间变异梯度层(Spatial Variant Gradient Layers, SVGL),以确保修复区域边界的自然过渡。
1. 核心模块
-
映射网络 (Mapping Network)
一个全连接神经网络 f f f 将随机潜在编码 z z z 映射到扩展的样式潜在空间 W + W^+ W+:
w ~ = f ( z ; θ f ) \tilde{w} = f(z; \theta_f) w~=f(z;θf) -
样式编码器 (Style Encoder)
将输入图像和示例图像的视觉特征提取为样式向量:
w exemplar = E ( I exemplar ; θ ^ e ) , w output = E ( I output ; θ ^ e ) w_{\text{exemplar}} = E(I_{\text{exemplar}}; \hat{\theta}_e), \quad w_{\text{output}} = E(I_{\text{output}}; \hat{\theta}_e) wexemplar=E(Iexemplar;θ^e),woutput=E(Ioutput;θ^e) -
多样式生成器 (Multi-Style Generator)
综合全局样式、随机样式和示例样式生成修复图像:
I output = G ( I input , M , w ^ ; θ g ) I_{\text{output}} = G(I_{\text{input}}, M, \hat{w}; \theta_g) Ioutput=G(Iinput,M,w^;θg) -
判别器 (Discriminator)
判别修复图像是否真实,并提供对抗损失。
2. 多样式调制
通过样式混合结合随机样式和示例样式,确保生成图像既保持全局视觉一致性,又嵌入示例的局部特征:
w
^
i
=
{
w
i
,
if
ϕ
i
=
1
w
~
i
,
otherwise
\hat{w}_i = \begin{cases} w_i, & \text{if } \phi_i = 1 \\ \tilde{w}_i, & \text{otherwise} \end{cases}
w^i={wi,w~i,if ϕi=1otherwise
其中
ϕ
i
\phi_i
ϕi 是二进制向量,控制层级样式的选择。
3. 空间变异梯度反向传播 (SVGL)
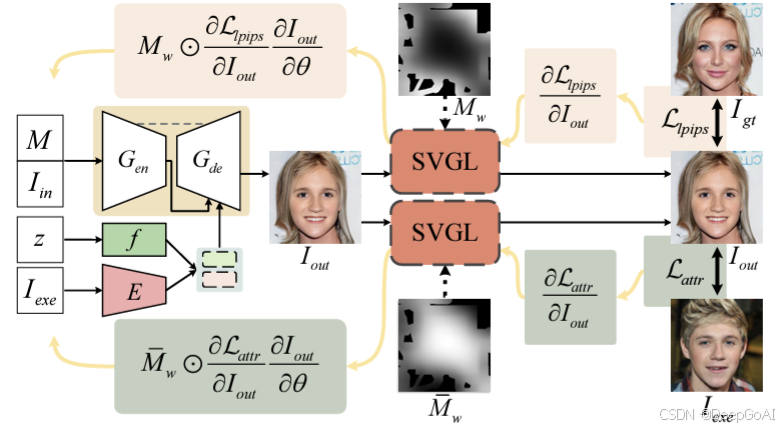
SVGL 在 LPIPS 和属性损失中的作用示意:在前向传播过程中,空间变异梯度层(SVGL)不会对 I out I_{\text{out}} Iout 的信息进行任何修改。在反向传播过程中,梯度会根据空间变异权重 M w M_w Mw 和 M w M_w Mw 进行重新加权,从而实现更精确的优化。
引入空间权重掩码
M
w
M_w
Mw 调整修复区域内外的梯度,保证修复区域与输入图像的自然过渡:
P
(
x
,
M
w
)
=
x
,
∂
P
(
x
,
M
w
)
∂
x
=
M
w
⊙
I
P(x, M_w) = x, \quad \frac{\partial P(x, M_w)}{\partial x} = M_w \odot I
P(x,Mw)=x,∂x∂P(x,Mw)=Mw⊙I
其中
M
w
M_w
Mw 是通过高斯平滑计算得到的权重掩码。
4. 目标函数
-
对抗损失:
L adv = E [ log ( 1 − D ( I output ) ) ] + E [ log ( D ( I ground truth ) ) ] \mathcal{L}_{\text{adv}} = \mathbb{E}[\log(1 - D(I_{\text{output}}))] + \mathbb{E}[\log(D(I_{\text{ground truth}}))] Ladv=E[log(1−D(Ioutput))]+E[log(D(Iground truth))] -
身份损失:
L id = 1 − cos ( R ( I output ) , R ( I exemplar ) ) \mathcal{L}_{\text{id}} = 1 - \cos(R(I_{\text{output}}), R(I_{\text{exemplar}})) Lid=1−cos(R(Ioutput),R(Iexemplar))
其中 R ( ⋅ ) R(\cdot) R(⋅) 是 ArcFace 的特征提取。 -
LPIPS 感知损失:
L lpips = ∥ F ( I output ) − F ( I ground truth ) ∥ 2 2 \mathcal{L}_{\text{lpips}} = \|F(I_{\text{output}}) - F(I_{\text{ground truth}})\|_2^2 Llpips=∥F(Ioutput)−F(Iground truth)∥22 -
属性损失:
L attr = 1 ∥ ϕ ∥ 0 ∑ i ∈ T ϕ i ⋅ ∥ w i − w ^ i ∥ 2 2 \mathcal{L}_{\text{attr}} = \frac{1}{\|\phi\|_0} \sum_{i \in T} \phi_i \cdot \|w_i - \hat{w}_i\|_2^2 Lattr=∥ϕ∥01i∈T∑ϕi⋅∥wi−w^i∥22 -
最终目标函数
最终生成目标整合多种损失:
L = L adv + λ id L id + λ lpips L lpips + λ attr L attr \mathcal{L} = \mathcal{L}_{\text{adv}} + \lambda_{\text{id}} \mathcal{L}_{\text{id}} + \lambda_{\text{lpips}} \mathcal{L}_{\text{lpips}} + \lambda_{\text{attr}} \mathcal{L}_{\text{attr}} L=Ladv+λidLid+λlpipsLlpips+λattrLattr
5. 修复图像的合成
修复图像是未遮挡区域与修复区域的融合:
I
output
=
I
input
⊙
(
1
−
M
)
+
I
pred
⊙
M
I_{\text{output}} = I_{\text{input}} \odot (1 - M) + I_{\text{pred}} \odot M
Ioutput=Iinput⊙(1−M)+Ipred⊙M
6. 更多实验效果

可以看到,EXE-GAN 支持使用多种不同的样例图片来引导图片的编辑,如发型,表情,装饰性的物品,如眼镜等,都可以做相应的迁移效果。

此外,EXE-GAN还支持实现基于多样例图片的融合编辑。每组从左到右依次展示:遮挡图像、一对示例图像,以及样式混合效果。每行中,第一个示例的样式编码从第
i
i
i 层到第
j
j
j 层的值被替换为第二个示例的对应层值,从而实现不同的样式混合效果。

这里进一步微调EXE-GAN,引入素描引导编辑。发型编辑示例:
前三行展示了使用不同示例图像引导的不同草图编辑结果;最后两行展示了使用相同草图但由不同示例图像引导的编辑结果。

这里进一步展示了EXE-GAN强大的人脸重建效果。比如你有照片A,然后你想重建自己的另一个遮挡图片B,这个场景就派上用场!在疫情期间去口罩也是一个不错的应用。
更多引导式面部图像恢复示例: 前四行展示了每组从左到右依次为:遮挡图像、恢复后的面部图像以及示例图像;最后一行展示了由不同示例图像引导生成的多样化恢复结果
总结
本文介绍了一种创新的人脸修复框架——EXE-GAN。该方法利用范例图像作为引导,实现了对人脸遮挡区域(如眼镜、口罩等)的修复,以及对局部面部特征(如发型、表情等)的精准编辑。不同于传统方法,EXE-GAN 不需要额外训练模块,而是直接使用预训练的生成模型,通过独特的多风格融合和自监督技术,保证了修复结果的自然性和视觉质量。
EXE-GAN 可广泛应用于局部面部特征迁移、发型设计、以及复杂遮挡条件下的人脸图像修复任务。
更多细节请参阅论文原文
关注微信公众号: DeepGoAI

















 1850
1850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









