







Value-Based
Q-Learning
为了方便阐述Q-Learning算法的具体流程,以下以一个经典的强化学习例子说明算法流程。
如下图结构代表了一幢建筑里房间结构,每个节点表示不同房间,节点间的箭头表示各房间之间的紧挨关系。
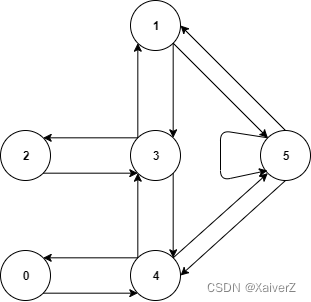
现在我们要做的就是将智能体置于任意一个起始房间内,让其自动经过若干房间最终到达5号房间。为了衡量智能体每由一个房间(状态)转换(行动)到另一个房间(状态)时环境对其的反馈(奖励),我们将每条边表上相应的权重以表示该次转换的奖励,如下图。
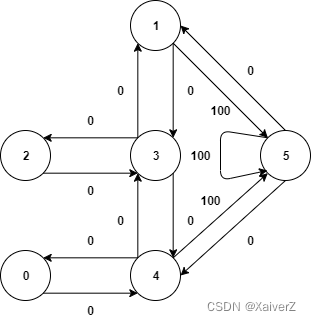
其中,目标节点5有一个指向自身的箭头,其奖励值为100,其他直接指向目标节点5的边的奖励值也为100。Q-Learning的目标是达到奖励值最大的状态,因此,当智能体达到目标节点后就将永远停留在那。
根据上图中节点间的权重,建立R表,即reward值矩阵,行表示状态state,列表示动作action。R表记录了每个状态执行不同的行为所得到的reward值,是人为设置且固定不变的。R表的第n行第m列表示在状态n下执行行为m所得到的即时奖励值。R表是Q-Learning算法中维护的核心数据结构之一。
R = [ − 1 − 1 − 1 − 1 0 − 1 − 1 − 1 − 1 0 − 1 100 − 1 − 1 − 1 0 − 1 − 1 − 1 0 0 − 1 0 − 1 0 − 1 − 1 0 − 1 100 − 1 0 − 1 − 1 0 100 ] R = \begin{bmatrix} -1 & -1 & -1 & -1 & 0 & -1 \\ -1 & -1 & -1 & 0 & -1 & 100 \\ -1 & -1 & -1 & 0 & -1 & -1 \\ -1 & 0 & 0 & -1 & 0 & -1 \\ 0 & -1 & -1 & 0 & -1 & 100 \\ -1 & 0 & -1 & -1 & 0 & 100 \\ \end{bmatrix} R= −1−1−1−10−1−1−1−10−10−1−1−10−1−1−100−10−10−1−10−10−1100−1−1100100
类似的,我们也需要建立一个矩阵Q,用来表示智能体已经从经验中学到的知识。矩阵Q与矩阵R是同阶的,其行表示状态,列表示行为。Q表也是Q-Learning算法中维护的核心数据结构之一。由于一开始时智能体对外界环境是一无所知的,因此Q矩阵应初始化为零矩阵。
Q = [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ] Q = \begin{bmatrix} 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ \end{bmatrix} Q= 000000000000000000000000000000000000
Q-Learning算法的核心公式就是Q矩阵的更新规则(贝尔曼最优性方程):

Δ Q ( s , a ) = R ( s , a ) + γ ⋅ max a ~ { Q ( s ~ , a ~ ) } − Q ( s , a ) \bm{ \Delta{Q(s,a)} = R(s,a) + γ·\max\limits_{\tilde{a}}\{Q(\tilde{s},\tilde{a})\} - Q(s,a) } ΔQ(s,a)=R(s,a)+γ⋅a~max{Q(s~,a~)}−Q(s,a)
Q ( s , a ) = Q ( s , a ) + α ⋅ Δ Q ( s , a ) \bm{ Q(s,a) = Q(s,a) + α·\Delta{Q(s,a)} } Q(s,a)=Q(s,a)+α⋅ΔQ(s,a)
Q ( s , a ) = R ( s , a ) + γ ⋅ max a ~ { Q ( s ~ , a ~ ) } , When α = 1 \bm{ Q(s,a) = R(s,a) + γ·\max\limits_{\tilde{a}}\{Q(\tilde{s},\tilde{a})\} ,\text{When α = 1} } Q(s,a)=R(s,a)+γ⋅a~max{Q(s~,a~)},When α = 1
其中,s,a表示当前的状态与行为, s ~ \tilde{s} s~, a ~ \tilde{a} a~表示s的下一个状态与行为,学习参数 γ γ γ为满足 0 ≤ γ < 1 0≤γ<1 0≤γ<1的常数, α α α为学习率。
该公式表示了每当智能体基于某状态作出某行为后,Q矩阵将根据上述公式进行更新。其中 R ( s , a ) R(s,a) R(s,a)表示智能体获得的即时奖励,而 γ ⋅ max a ~ { Q ( s ~ , a ~ ) } γ·\max\limits_{\tilde{a}}\{Q(\tilde{s},\tilde{a})\} γ⋅a~max{Q(s~,a~)}表示智能体该步行为对下一步行为的影响大小。所以该公式不仅考虑了当下的即时奖励,还一定程度上考虑到了现在的决策对未来的影响。
例如,在训练过程中,假定 γ = 0.8 , α = 1 γ= 0.8,α=1 γ=0.8,α=1,初始化状态为节点1,初始化矩阵Q为零矩阵。我们在初始状态1下,随机选择一个相邻节点进行转换,这里我们选择节点5。根据上述公式,有:
Q ( 1 , 5 ) = R ( 1 , 5 ) + 0.8 ⋅ max { Q ( 5 , 1 ) , Q ( 5 , 4 ) , Q ( 5 , 5 ) } = 100 Q(1,5)=R(1,5)+ 0.8·\max\{Q(5,1),Q(5,4),Q(5,5)\} = 100 Q(1,5)=R(1,5)+0.8⋅max{Q(5,1),Q(5,4),Q(5,5)}=100
所以Q矩阵将更新为:
Q = [ 0 0 0 0 0 0 0 0 0 0 0 100 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ] Q = \begin{bmatrix} 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 100 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ \end{bmatrix} Q= 00000000000000000000000000000001000000
由于节点5为目标状态,故一次episode就完成了。Q-Learning算法就是这样不断进行训练,直到Q矩阵收敛到一个稳定的状态。
-
完整的Q-Learning算法如下:
1. 给定参数γ和reward矩阵R
2. 初始化Q矩阵为零矩阵
3. For each episode:- 随机选择一个初始状态s
- 若未达到目标状态,则执行以下几步
1. 在当前状态s的所有可能行为中选取一个行为a
2. 利用选定的行为a,得到下一个状态 s ~ \tilde{s} s~
3. 按照Q矩阵更新规则公式计算 Q ( s , a ) Q(s,a) Q(s,a)
4. 令 s = s ~ s = \tilde{s} s=s~
-
利用训练好的Q矩阵进行实际游戏过程算法如下:
1. 随机选择一个初始状态s
2. 确定a,使其满足 Q ( s , a ) = max a ~ { Q ( s , a ~ ) } Q(s,a) = \max\limits_{\tilde{a}}\{Q(s,\tilde{a})\} Q(s,a)=a~max{Q(s,a~)}
3. 令当前状态 s = s ~ s = \tilde{s} s=s~
4. 重复执行第2步与第3步直到s成为目标状态
Question-1:为什么Q-Learning在根据当前State选择Action时,有一定的概率ε随机选择动作?(ε-Greedy搜索策略)
序列学习算法基本都会涉及到一个基本选择:
-
利用:根据当前信息做出最佳决策
-
探索:做出其他决策来收集更多信息
合理平衡好探索和利用的关系,对智能体的学习能力有重大影响。过多的探索会阻碍智能体最大限度地获得短期奖励,因为选择继续探索可能获得较低地环境奖励。另一方面,由于选择的利用动作可能不是最优的,因此靠不完全知识来利用环境会阻碍长期奖励的最大化
Question-2:为什么训练收敛的Q表最后一行(状态)对应的Q值均为0?
最后一行的状态表示终态,即Agent在该状态即结束一回合,而Q-Learning只在由状态 s 1 = > s 2 s_1 => s_2 s1=>s2时更新 s 1 s_1 s1对应的Q值,而最后一行为终态,只有当Agent从终态出发更新到任一状态时才会对终态的Q值进行更新,故最后一行Q值一定为0
Question-3:关于参数γ与Reward的组合选择
γ代表了当前状态下采取的动作对未来的影响的大小程度。γ越大表示越考虑未来,更考虑全局,优点是更能达到全局最优,缺点是收敛速度较慢;γ越小表示越考虑当下,更考虑局部更快的达到局部最优,优点是收敛速度较快,缺点是很难达到全局最优
纯经验:越稀疏的Reward搭配越大的γ较好;越密集的Reward搭配越小的γ较好
ε-Greedy搜索策略
- 该策略在每一步都利用概率ε来选择随机动作。(这可能是最常用也是最简单的搜索策略,即用ε调整探索动作。在许多实现中,ε会随着时间不断衰减,但也有不少情况,ε会被设置为常数)
不确定优先搜索策略
Optimism in Face of Uncertainty
-
置信区间上界(Upper Confidence Bound,UCB)
- 可用于替代ε-Greedy
Double Q-Learning
解决Q-Learning中对Q的Overestimate问题
Sarsa
state-action-reward-state-action
- Sarsa与Q-Learning很类似,最关键的区别在于Q的更新算法上。Sarsa的Q更新规则如下:

Δ Q ( s , a ) = R ( s , a ) + γ ⋅ Q ( s ~ , a ~ ) − Q ( s , a ) \bm{ \Delta{Q(s,a)} = R(s,a) + γ·Q(\tilde{s},\tilde{a}) - Q(s,a) } ΔQ(s,a)=R(s,a)+γ⋅Q(s~,a~)−Q(s,a)
Q ( s , a ) = Q ( s , a ) + α ⋅ Δ Q ( s , a ) \bm{ Q(s,a) = Q(s,a) + α·\Delta{Q(s,a)} } Q(s,a)=Q(s,a)+α⋅ΔQ(s,a)
Q ( s , a ) = R ( s , a ) + γ ⋅ Q ( s ~ , a ~ ) , When α = 1 \bm{ Q(s,a) = R(s,a) + γ·Q(\tilde{s},\tilde{a}) ,\text{When α = 1} } Q(s,a)=R(s,a)+γ⋅Q(s~,a~),When α = 1
Comparison Between Sarsa & Q-Learning
-
Q-Learning
-
Q-Learning是先根据下一步的可能最大Reward更新Q值,再做出下一步动作
-
Q-Learning是Off-Policy的更新方式,它的行为策略是ε-greedy,而评估策略是Max贪婪
- Q-Learning根据当前state选出action后(ε-greedy),执行该action得到下一个state,此时即更新Q表,并转向下一轮迭代(下一个state的action在本轮迭代中还未确定(所以更新Q表用的是Max贪婪),即 S , A , S ′ S,A,S^{'} S,A,S′)
-
-
Sarsa
-
Sarsa是先做出下一步动作,再根据做出的动作更新Q值
-
Sarsa是On-Policy的更新方式,它的行为策略和评估策略都是ε-greedy
-
Sarsa根据当前state选出action后(ε-greedy),执行该action得到下一个state,此时再根据下一个state选出下一个action(ε-greedy)。然后再更新Q表,并转向下一轮迭代(下一个state的action在本轮迭代中已经确定,即 S , A , S ′ , A ′ S,A,S^{'},A^{'} S,A,S′,A′)
-
Sarsa-Lambda
Sarsa(λ)
-
普通的Sarsa算法在每次迭代更新时,只会更新本次 Q ( s , a ) Q(s, a) Q(s,a)的值,以往的state-action并不会更新,即Sarsa(0)
-
但Sarsa(0)的这种更新方式其实只考虑到了“当前”以及“未来”的情况,并未考虑到“过去”的情况,即没考虑到当前的行为决策(获得的Reward)应当对过去经历过的state-action也产生一定的影响(可以理解为“经验教训”:当前的行为决策应当要“反作用”于过去的state-action,也就是要从当前的行为决策中获得“经验教训”并反作用于过去的state-action(即更新过去state-action的Q值),这样就能在下一轮的迭代中得到更加强大的Agent)
-
考虑另一种极端情况:Sarsa(1),(平均)更新到获取Reward前所有经历的步
-
Sarsa(λ)在每一回合的单步更新中都考虑到了当前的行为决策对过去的影响。Sarsa(λ)用一个与Q、R同阶的新表格:E表,来记录在每一轮回合的迭代中走过的state-action路径(不可或缺性),并利用λ参数随时间推移产生指数衰减的效果
-
E表的这种自增1的更新方式可以理解为状态的“不可或缺性”:如果在某一回合中,Agent频繁经过某一状态,那就说明该状态可能是到达终态路径上一个“不可或缺”的状态,所以自增1,以此引起Q表对该处的 Q ( s , a ) Q(s, a) Q(s,a)更新力度加大

Δ Q ( s , a ) = R ( s , a ) + γ ⋅ Q ( s ~ , a ~ ) − Q ( s , a ) \bm{ \Delta{Q(s,a)} = R(s,a) + γ·Q(\tilde{s},\tilde{a}) - Q(s,a) } ΔQ(s,a)=R(s,a)+γ⋅Q(s~,a~)−Q(s,a)
E ( s , a ) = E ( s , a ) + 1 \bm{ E(s, a) = E(s, a) + 1 } E(s,a)=E(s,a)+1
Q = Q + α ⋅ Δ Q ( s , a ) ⋅ E \bm{ Q = Q + α·\Delta{Q(s,a)}·E } Q=Q+α⋅ΔQ(s,a)⋅E
E = γ ⋅ λ ⋅ E E = γ·λ·E E=γ⋅λ⋅E
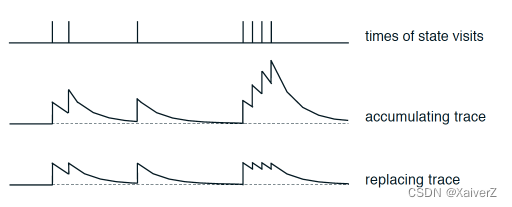
- 上述这种E表的更新方式其实有些缺陷:如果只是在单步更新中单纯的对 E ( s , a ) E(s, a) E(s,a)加1的话,可能会造成过度累加,过去的 E ( s , a ) E(s, a) E(s,a)可能变得比当前状态还大(尽管有λ的指数衰减,但累加过多无效了),因为Agent不一定能在一个回合中径直、不重复的走过路径上的每一个状态到达终态,可能会在某几个状态之间来回徘徊,这就造成了E表累加和过大。下面这种方式是一种改进模式,更合理:
E ( s , : ) = E ( s , : ) ∗ 0 \bm{ E(s, :) = E(s, :) * 0 } E(s,:)=E(s,:)∗0
E ( s , a ) = 1 \bm{ E(s, a) = 1 } E(s,a)=1
-
这种方式相当于给了E表一个上限,不会无限累加(注意E表记录的是一回合中的路径,所以在每一回合初都要清零)
-
下图是两种E表更新方式的对比


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









