







CS224W: Machine Learning with Graphs
Stanford / Winter 2021
16-advanced
Limitations of Graph Neural Networks
Limitations of Graph Neural Networks
-
A “Perfect” GNN Model
-
前述对表达力最强的GNN定义是build an injective function between neighborhood structure and node embeddings
-
因此,若两个节点的邻域结构相同,则它们的embedding一定相同
-
若两个节点邻域结构不同,则它们的embedding一定不相同
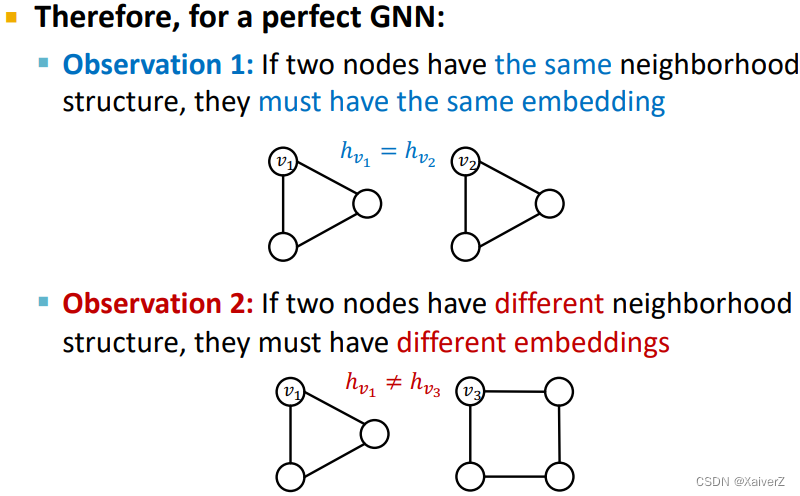
-
-
但第一种情况是不完美的,在很多情况下,我们希望区分出邻域结构相同但位置不同的节点(Position-aware tasks),这是前述perfect GNN所不能的
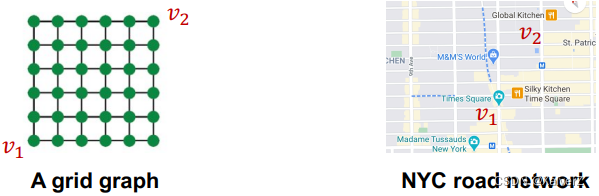
-
第二种情况则通常很难被满足,前述讨论GNN的表达力上界是WL Test
-
Position-aware Graph Neural Networks
Paper : Position-aware Graph Neural Networks
Position-aware Graph Neural Networks
-
There are two types of tasks on graphs
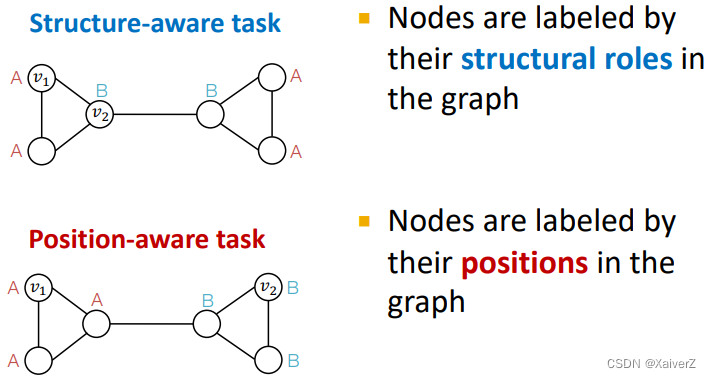
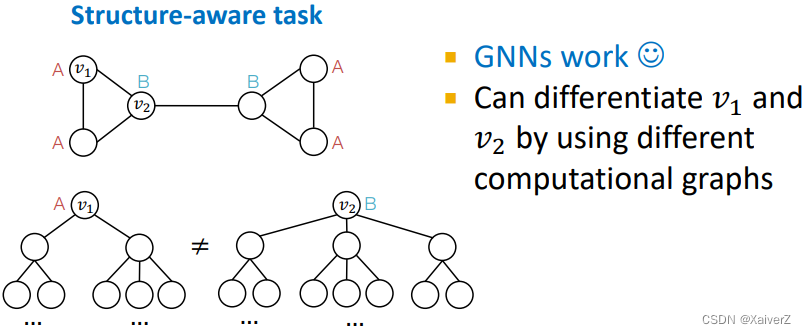
- GNNs often work well for structure-aware tasks
- GNNs will always fail for position-aware tasks
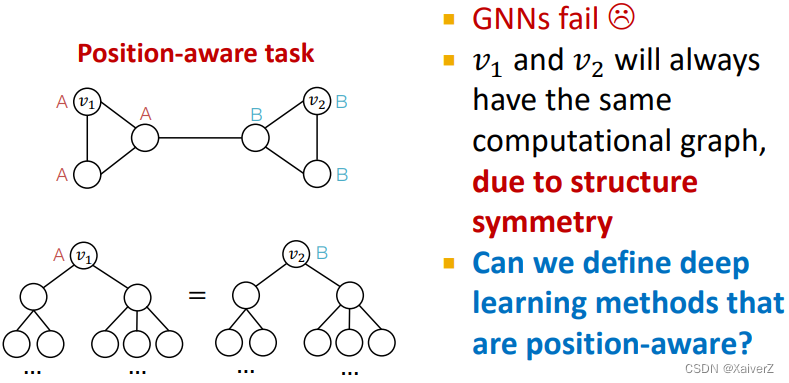
-
Power of “Anchor”
-
Randomly pick a node s 1 s_1 s1 as an anchor node
-
Represent v 1 v_1 v1 and v 2 v_2 v2 via their relative distances w.r.t. the anchor s 1 s_1 s1, which are different
-
An anchor node serves as a coordinate axis
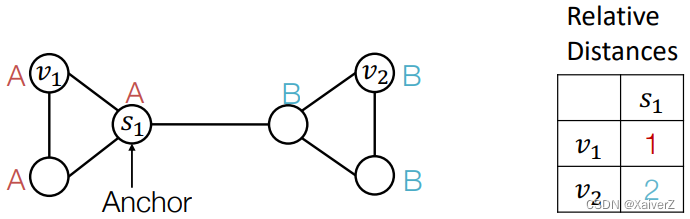
-
Pick more nodes s 1 , s 2 s_1,s_2 s1,s2 as anchor nodes
-
More anchors can better characterize node position in different regions of the graph
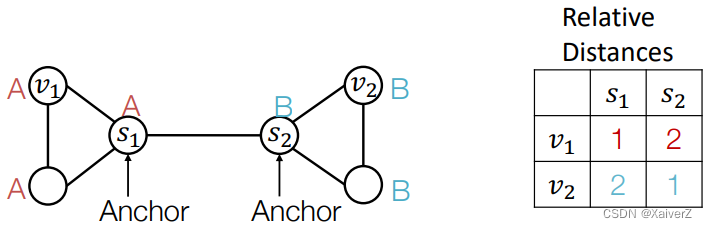
-
Generalize anchor from a single node to a set of nodes
- We define distance to an anchor-set as the minimum distance to all the nodes in the ancho-set
-
Large anchor-sets can sometimes provide more precise position estimate
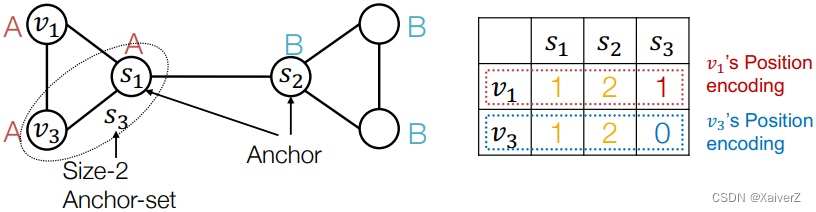
-
-
How to Use Position Information
- Use it as an augmented node feature
-
Issue
-
since each dimension of position encoding is tied to a random anchor, dimensions of positional encoding can be randomly permuted, without changing its meaning
-
Imagine you permute the input dimensions of a normal NN, the output will surely change
-
The rigorous solution: requires a special NN that can maintain the permutation invariant property of position encoding
- Permuting the input feature dimension will only result in the permutation of the output dimension, the value in each dimension won’t change
-
Identity-aware Graph Neural Networks
Paper : Identity-aware Graph Neural Networks
Identity-aware Graph Neural Networks
-
GNNs exhibit three levels of failure cases in structure-aware tasks
-
Node level
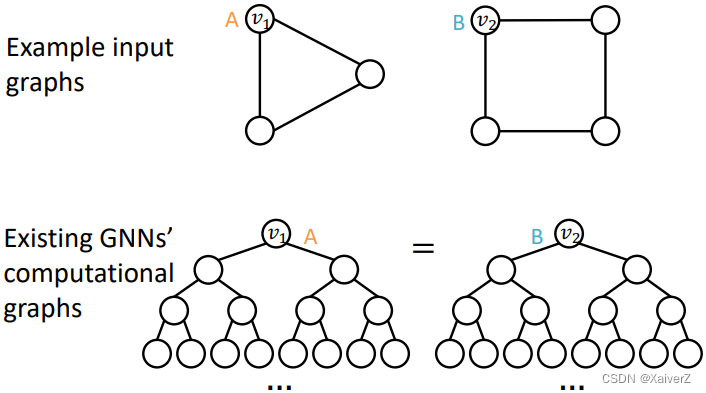
-
Edge level
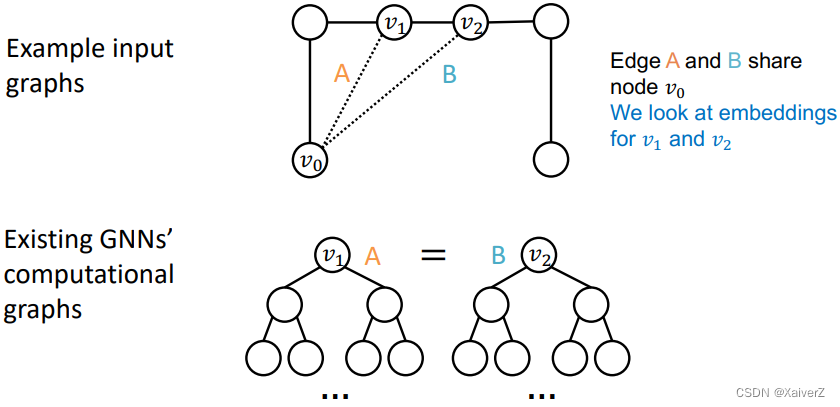
-
Graph level
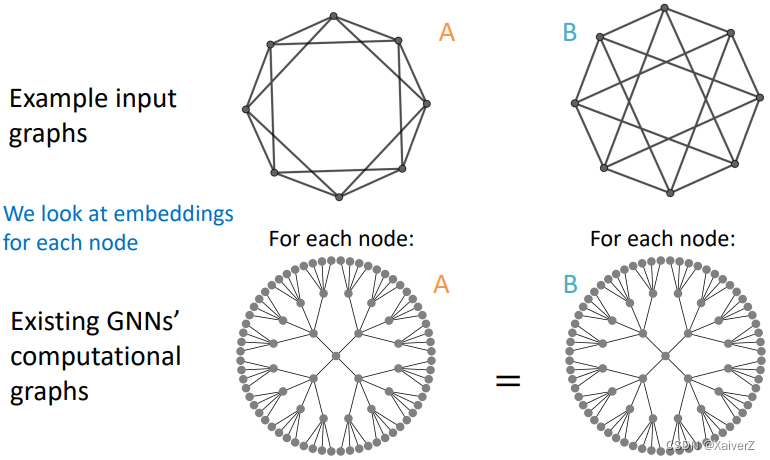
-
-
Idea: Inductive Node Coloring
We can assign a color to the node we want to embed
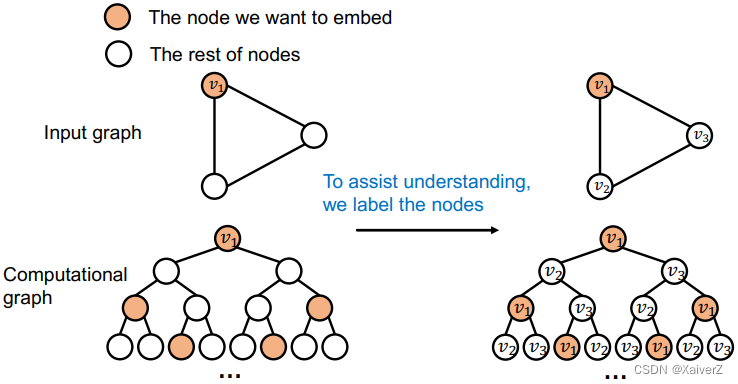
- This coloring is inductive. It is invariant to node ordering/identities
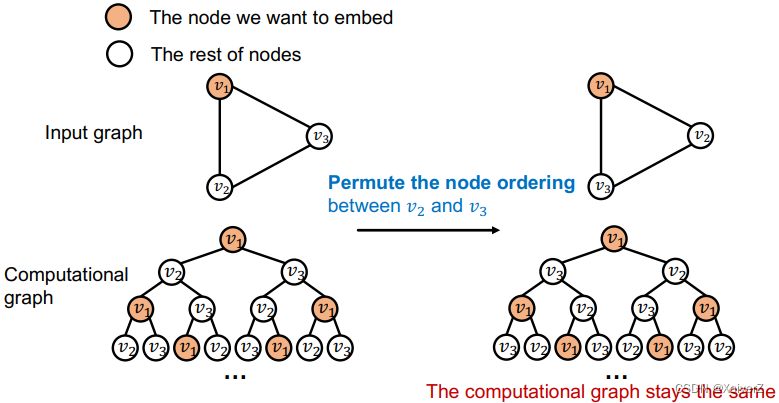
- Inductive node coloring can help node classification
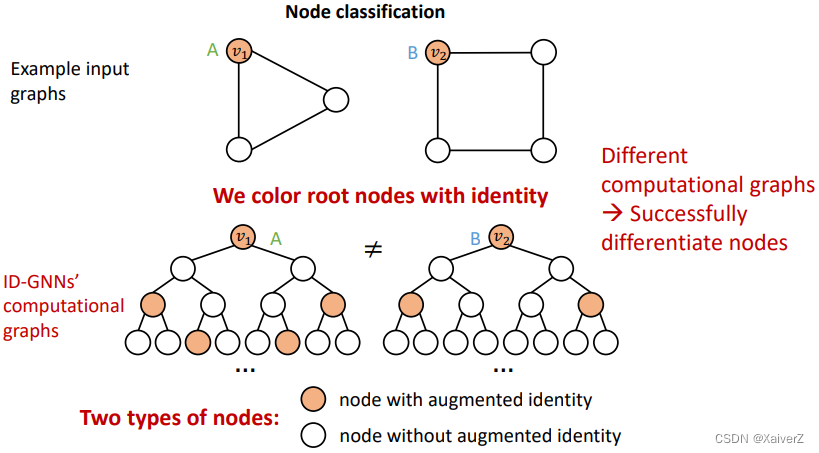
- Inductive node coloring can help graph classification
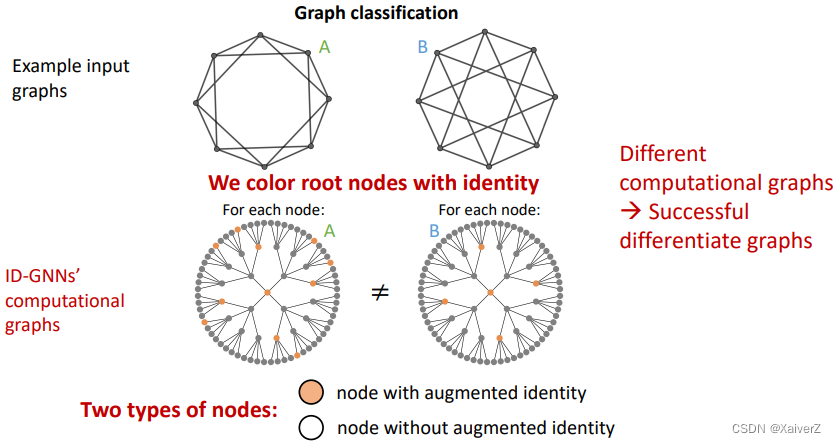
- Inductive node coloring can help link prediction
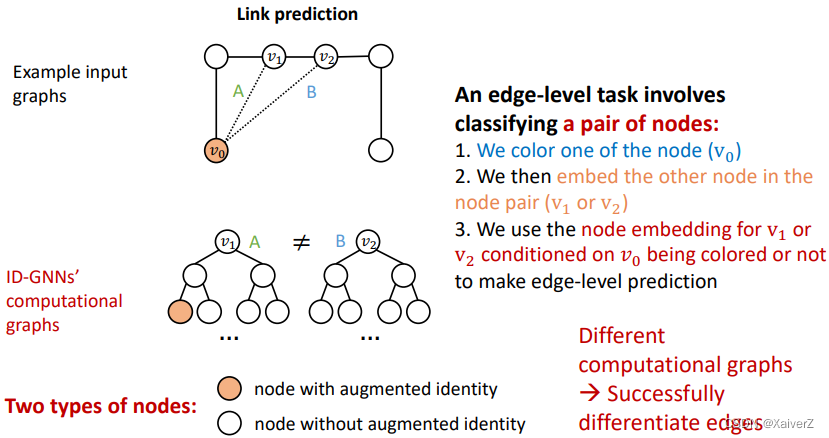
-
How to build GNNs using node coloring
Idea: Heterogenous message passing
- An ID-GNN applies different message/aggregation to nodes with different colorings
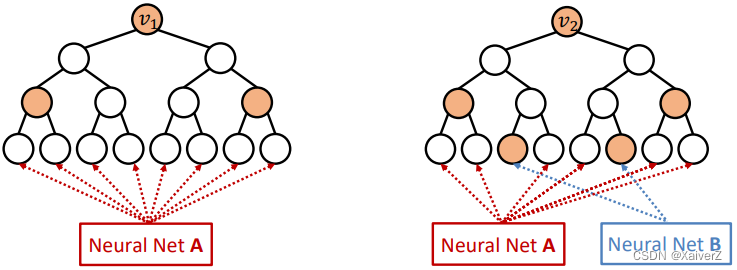
-
GNN vs. ID-GNN
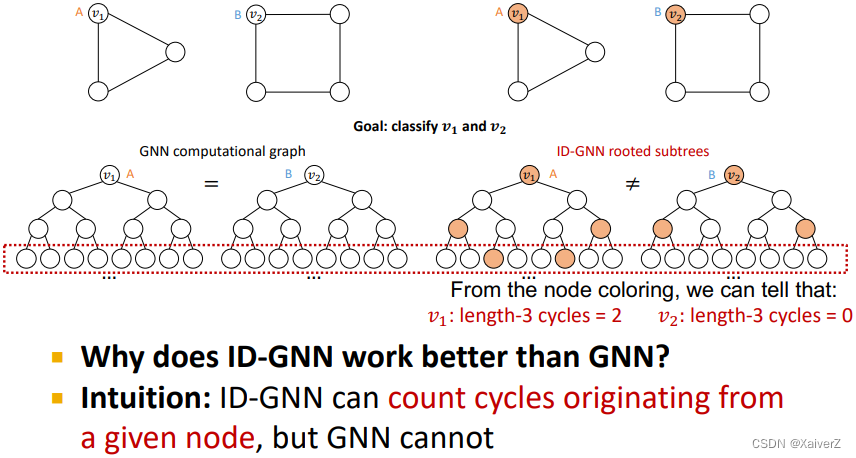
-
Simplifies Version: ID-GNN-Fast
-
Include identity information as an augmented node feature (no need to do heterogenous message passing)
-
Use cycle counts in each layer as an augmented node feature. Also can be used together with any GNN
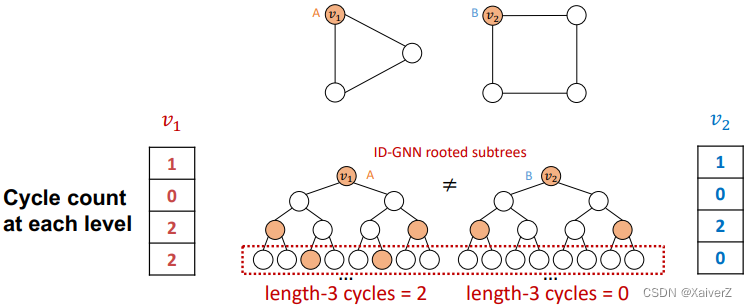
-
-
Summary

Robustness of Graph Neural Networks
Paper : Adversarial Attacks on Neural Networks for Graph Data
Robustness of Graph Neural Networks
-
Attack Possibilities
-
Target node t ∈ V t \in V t∈V: node whose label prediction we want to change
-
Attacker nodes S ⊂ V S \subset V S⊂V: nodes the attacker can modify
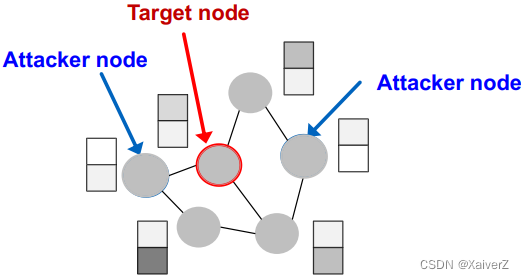
-
-
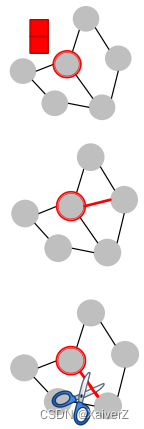
Direct Attack
Attacker node is the target node: S = t S = {t} S=t
-
Modify target node feature
-
Add connections to target
-
Remove connections from target
-
-
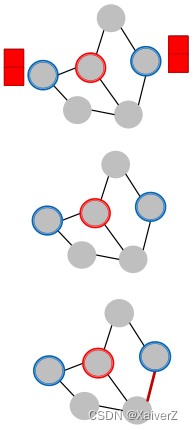
Indirect Attack
The target node is not in the attacker nodes: t ∉ S t \notin S t∈/S
-
Modify attacker node features
-
Add connections to attackers
-
Remove connections from attackers
-
-
Mathematical Formulation
Goal: 以最微小的改动造成最大的影响
-
Assumption
( A ′ , X ′ ) ≈ ( A , X ) \left(\boldsymbol{A}^{\prime}, \boldsymbol{X}^{\prime}\right) \approx(\boldsymbol{A}, \boldsymbol{X}) (A′,X′)≈(A,X)
- Graph manipula;on is unno7ceably small
-
Original Graph
θ ∗ = argmin θ L train ( θ ; A , X ) \boldsymbol{\theta}^{*}=\operatorname{argmin}_{\boldsymbol{\theta}} \mathcal{L}_{\text {train }}(\boldsymbol{\theta} ; \boldsymbol{A}, \boldsymbol{X}) θ∗=argminθLtrain (θ;A,X)
c v ∗ = argmax c f θ ∗ ( A , X ) v , c c_{v}^{*}=\operatorname{argmax}_{c} f_{\theta^{*}}(\boldsymbol{A}, \boldsymbol{X})_{v, c} cv∗=argmaxcfθ∗(A,X)v,c
-
Manipulated Graph
θ ∗ ′ = argmin θ L train ( θ ; A ′ , X ′ ) \boldsymbol{\theta}^{* \prime}=\operatorname{argmin}_{\boldsymbol{\theta}} \mathcal{L}_{\text {train }}\left(\boldsymbol{\theta} ; \boldsymbol{A}^{\prime}, \boldsymbol{X}^{\prime}\right) θ∗′=argminθLtrain (θ;A′,X′)
c v ∗ ′ = argmax c f θ ∗ ′ ( A ′ , X ′ ) v , c c_{v}^{* \prime}=\operatorname{argmax}_{c} f_{\boldsymbol{\theta}^{* \prime}}\left(\boldsymbol{A}^{\prime}, \boldsymbol{X}^{\prime}\right)_{v, c} cv∗′=argmaxcfθ∗′(A′,X′)v,c
-
We want the prediction to change after the graph is manipulated
C v ∗ ′ ≠ C v ∗ C_{v}^{* \prime} \neq C_{v}^{*} Cv∗′=Cv∗
-
Change of predicBon on target node v v v
Δ ( v ; A ′ , X ′ ) = log f θ ∗ ′ ( A ′ , X ′ ) v , c v ∗ ′ − log f θ ∗ ′ ( A ′ , X ′ ) v , c v ∗ \begin{aligned} &\boldsymbol{\Delta}\left(v ; \boldsymbol{A}^{\prime}, \boldsymbol{X}^{\prime}\right)= \\ &\quad \log f_{\boldsymbol{\theta}^{* \prime}}\left(\boldsymbol{A}^{\prime}, \boldsymbol{X}^{\prime}\right)_{v, c_{v}^{* \prime}}-\log f_{\boldsymbol{\theta}^{* \prime}}\left(\boldsymbol{A}^{\prime}, \boldsymbol{X}^{\prime}\right)_{v, c_{v}^{*}} \end{aligned} Δ(v;A′,X′)=logfθ∗′(A′,X′)v,cv∗′−logfθ∗′(A′,X′)v,cv∗
-
Final Optimization Objective
argmax A ′ , X ′ Δ ( v ′ ; A ′ , X ′ ) s u b j e c t t o ( A ′ , X ′ ) ≈ ( A , X ) \operatorname{argmax}_{\boldsymbol{A}^{\prime}, \boldsymbol{X}^{\prime}} \boldsymbol{\Delta}\left(\boldsymbol{v}^{\prime} ; \boldsymbol{A}^{\prime}, \boldsymbol{X}^{\prime}\right) subject to \left(\boldsymbol{A}^{\prime}, \boldsymbol{X}^{\prime}\right) \approx(\boldsymbol{A}, \boldsymbol{X}) argmaxA′,X′Δ(v′;A′,X′)subjectto(A′,X′)≈(A,X)
-
Challenges in opBmizing the objective
-
Adjacency matrix A ′ A' A′, is a discrete object: gradient-based optimization cannot be used
-
For every modified graph A ′ A' A′ and X ′ X' X′, GCN needs to be retrained (this is computaRonally expensive)
-
-
-
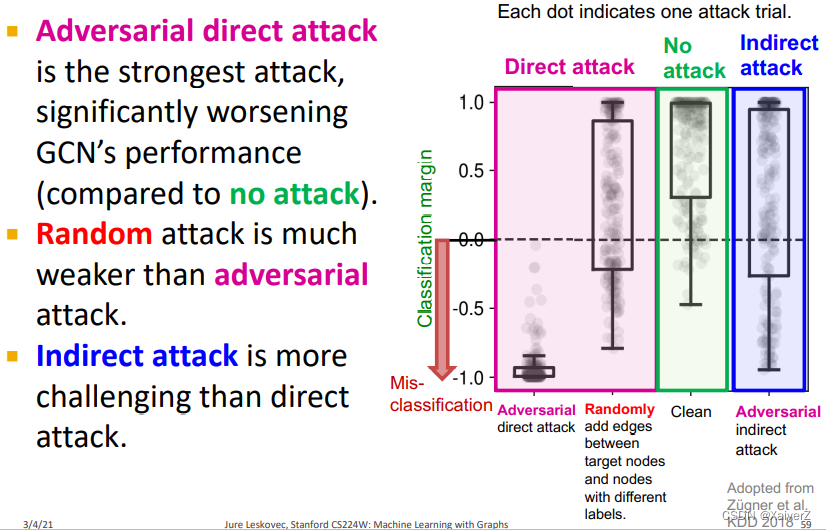
Performance















 2184
2184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









