







Regular Expression for Binary Numbers Divisible by n: https://www.codewars.com/kata/5993c1d917bc97d05d000068
这道题主要的思路是借助DFA,先写出读取01串对应的DFA,然后化简成正则表达式。以下对这种思路进行详细介绍。Codewars目前Python下最高赞版本就是相同的思路,同时代码简化到极致。
DFA的构造
具体来说,从前到后地1读取01串,以当前读到的部分串对n的余数情况,确定目前DFA所处的状态。以此构建具有n个结点的DFA,对应“对n的余数为0, 1, …, n-1”。
对于n=3的情况,对于从前往后读取01串,写出的DFA是这样的:
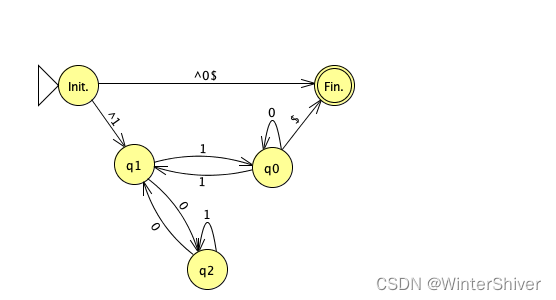
为了简洁性,我们不处理起始符^,但是依然需要处理终止符$,判断串的结束。
在程序中,我们用一个列表存储DFA的全体边信息。对于上述化简的DFA,程序如下:
def build_dfa(n):
""" -1: initial state; -2: final state
"""
dfa = [
{'src': -1, 'tgt': 1, 'path': '1'},
{'src': -1, 'tgt': -2, 'path': '0$'},
{'src': 0, 'tgt': -2, 'path': '$'}]
for i in range(n):
dfa.append({'src': i, 'tgt': (2*i)%n, 'path': '0'})
dfa.append({'src': i, 'tgt': (2*i+1)%n, 'path': '1'})
return dfa
把这个DFA逐渐转化成正则表达式,要做的事情就是依次去掉图中的结点。
每去掉一个结点,需要做两件事:
- 去掉这个结点指向自身的状态转移路径。(去递归)
- 在图中去掉这个结点,把这个结点的入边和出边重新组合到一起。(去结点)
以去掉结点2为例,讲解这两个步骤。
去递归
结点2有一条指向自己的状态转移1. 这对应正则表达式中一个零次或若干次的匹配(即1*),在匹配一个1*之后,原先处于状态2的匹配过程现在仍处于状态2. 所以一次匹配从进入状态2到离开状态2,经历的是一个这样的过程:
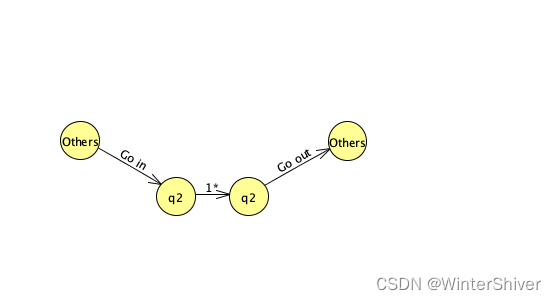
为了去掉这个递归,我们把匹配1*的过程转移到进入状态2的位置。具体来说,我们为结点2的每个入边额外增加一个1*的匹配,这样就把状态内的递归转化成了进入这个状态时需要匹配的一个递归模式,从而去掉了自递归。
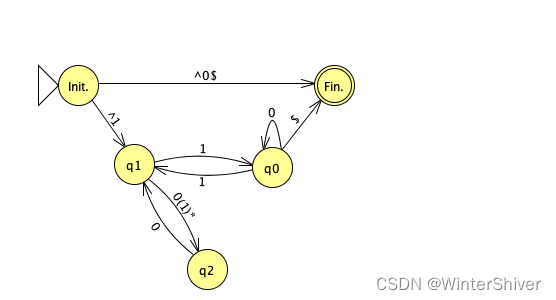
如上图所示,在我们的例子里,结点2的指向自身的边1被消除,而每条外部指向结点2的边额外增加一个1*的匹配。
实现去递归的代码如下所示,dfa_without_recur是排除了所有自指边的DFA,通过修改其中所有指向node的边获得最终的DFA。另外,注意到图中可能还存在结点有多条自指边的情况,针对这种情况额外加入了用|合并多个模式的功能。
def remove_recur(dfa, node):
""" remove self-pointing circle of node, move the pattern to src path
"""
dfa_without_recur = [
edge for edge in dfa
if not (edge['src'] == node and edge['tgt'] == node)]
recur_paths = [
edge['path'] for edge in dfa
if edge['src'] == node and edge['tgt'] == node]
if len(recur_paths) == 1:
pattern = f'(({recur_paths[0]})*)'
elif len(recur_paths) > 1:
pattern = f"(({''.join([f'(({p})*)' for p in recur_paths])})*)"
else:
pattern = ''
ret_dfa = []
for edge in dfa_without_recur:
if edge['tgt'] == node:
edge['path'] = edge['path'] + pattern
ret_dfa.append(edge)
return ret_dfa
去结点
在一个结点的自递归被消除之后,这个结点自身也能被消除。
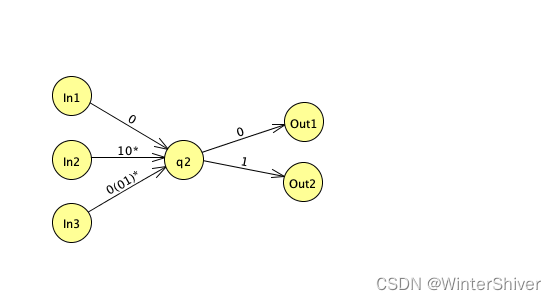
如图所示,q2结点有很多入边和出边。去掉这个结点之后,这些边会以全连接的方式配对,进入q2的模式和离开q2的模式合并,成为从进入状态到离开状态的新模式。
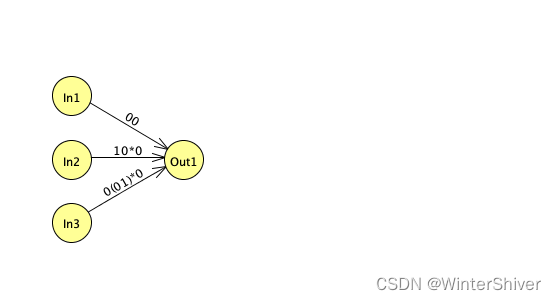
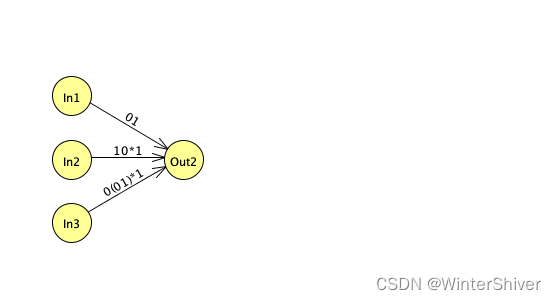
具体到我们的例子,指向q2的结点只有q1,从q2指出的结点也只有q1,所以去掉q2之后,q1->q2和q2->q1的边变成q1指向自己的边:
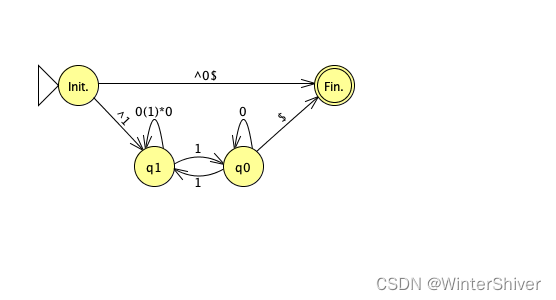
具体到代码,首先取得不带待删除结点node的DFAdfa_without_node,再取得全部node的出入边,分别用incoming_patterns, outcoming_patterns记录,按上面的图示组成新的边,加入dfa_without_node,形成最后的DFA。另外,注意到图中可能还存在两个结点之间有多条边的情况,针对这种情况额外加入了用|合并多个模式的功能。
def remove_node(dfa, node):
""" the removed node should not be with self-pointing circle
"""
nodes_without_node = []
for edge in dfa:
if edge['src'] != node and edge['src'] not in nodes_without_node:
nodes_without_node.append(edge['src'])
if edge['tgt'] != node and edge['tgt'] not in nodes_without_node:
nodes_without_node.append(edge['tgt'])
dfa_without_node = [
edge for edge in dfa
if edge['src'] != node and edge['tgt'] != node]
incoming_patterns = dict()
for n in nodes_without_node:
incoming_paths = [
edge['path'] for edge in dfa
if edge['src'] == n and edge['tgt'] == node]
if len(incoming_paths) == 1:
incoming_patterns[n] = f'{incoming_paths[0]}'
elif len(incoming_paths) > 1:
incoming_patterns[n] = \
f"({'|'.join([f'({p})' for p in incoming_paths])})"
outcoming_patterns = dict()
for n in nodes_without_node:
outcoming_paths = [
edge['path'] for edge in dfa
if edge['src'] == node and edge['tgt'] == n]
if len(outcoming_paths) == 1:
outcoming_patterns[n] = f'{outcoming_paths[0]}'
elif len(outcoming_paths) > 1:
outcoming_patterns[n] = \
f"({'|'.join([f'({p})' for p in outcoming_paths])})"
for k1 in incoming_patterns.keys():
for k2 in outcoming_patterns.keys():
dfa_without_node.append({
'src': k1,
'tgt': k2,
'path': incoming_patterns[k1] + outcoming_patterns[k2]})
return dfa_without_node
获得正则表达式
用上述方式继续删除结点1和0,获得只有Init.和Fin.的DFA,此时从Init.指向Fin.有若干条边,这些边用|连接一下就组成了最终的正则表达式。
此处的代码是
def calc_for_regexp_main(n):
if n == 1:
return '^(0|1(0|1)*)$'
dfa = build_dfa(n)
deleting_sequence = list(range(n-1, -1, -1))
for node in deleting_sequence:
dfa = remove_recur(dfa, node)
dfa = remove_node(dfa, node)
for edge in dfa:
assert edge['src'] == -1 and edge['tgt'] == -2
return '^('+'|'.join([f"({edge['path'][:-1]})" for edge in dfa])+')$'
效率优化
我的解法只用了*一种匹配方法,同时为了保证正确性引入了太多的括号。整体上的低效,使代码无法直接通过此题目。因此,还需要做一些额外的效率优化。
注意到并不一定需要以下标从大到小的顺序删除结点,可以把这个顺序指定成随机的,这样有助于最后生成的正则表达式更短,因为按顺序删除,生成的正则表达式长度似乎是指数级的。
由于我在组合最终正则表达式时采用去掉$再重新加回来的设计,必须最后一个删除0。为了方便,设置倒数第二个删除1。
deleting_sequence = list(range(n-1, 1, -1))
random.shuffle(deleting_sequence)
deleting_sequence += [1, 0]
随机的生成顺序导致每次不同的生成结果。为了生成尽量短的正则表达式,我们取10次生成中最短的结果。以此法生成的n=1-18的正则表达式,在n较大(>12)时,长度从最大2M降低到0.1M。
最高赞解法没有考虑很多情况,比如排除以0开头的串。另外各种语法进行了缩减,实现了代码的。














 3463
3463











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









