







PyTorch 基础 : 神经网络包nn和优化器optm
torch.nn是专门为神经网络设计的模块化接口。nn构建于 Autograd之上,可用来定义和运行神经网络。
这里我们主要介绍几个一些常用的类
约定:torch.nn 我们为了方便使用,会为他设置别名为nn,本章除nn以外还有其他的命名约定
# 首先要引入相关的包
import torch
# 引入torch.nn并指定别名
import torch.nn as nn
除了nn别名以外,我们还引用了nn.functional,这个包中包含了神经网络中使用的一些常用函数,这些函数的特点是,不具有可学习的参数(如ReLU,pool,DropOut等),这些函数可以放在构造函数中,也可以不放,但是这里建议不放。
一般情况下我们会将nn.functional 设置为大写的F,这样缩写方便调用
定义一个网络
PyTorch中已经为我们准备好了现成的网络模型,只要继承nn.Module,并实现它的forward方法,PyTorch会根据autograd,自动实现backward函数,在forward函数中可使用任何tensor支持的函数,还可以使用if、for循环、print、log等Python语法,写法和标准的Python写法一致。
class Net(nn.Module):
def __init__(self):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
super(Net, self).__init__()
# 卷积层 '1'表示输入图片为单通道, '6'表示输出通道数,'3'表示卷积核为3*3
self.conv1 = nn.Conv2d(1, 6, 3)
#线性层,输入1350个特征,输出10个特征
self.fc1 = nn.Linear(1350, 10) #这里的1350是如何计算的呢?这就要看后面的forward函数
#正向传播
def forward(self, x):
print(x.size()) # 结果:[1, 1, 32, 32]
# 卷积 -> 激活 -> 池化
x = self.conv1(x) #根据卷积的尺寸计算公式,计算结果是30,具体计算公式后面第二章第四节 卷积神经网络 有详细介绍。
x = F.relu(x)
print(x.size()) # 结果:[1, 6, 30, 30]
x = F.max_pool2d(x, (2, 2)) #我们使用池化层,计算结果是15
x = F.relu(x)
print(x.size()) # 结果:[1, 6, 15, 15]
# reshape,‘-1’表示自适应
#这里做的就是压扁的操作 就是把后面的[1, 6, 15, 15]压扁,变为 [1, 1350]
x = x.view(x.size()[0], -1)
print(x.size()) # 这里就是fc1层的的输入1350
x = self.fc1(x)
return x
net = Net()
print(net)

网络的可学习参数通过net.parameters()返回
for parameters in net.parameters():
print(parameters)

net.named_parameters可同时返回可学习的参数及名称。
for name,parameters in net.named_parameters():
print(name, ':', parameters.size())

forward函数的输入和输出都是Tensor
input = torch.randn(1, 1, 32, 32) # 这里的对应前面forward的输入是32
out = net(input)
print(out.size())

print(input.size())
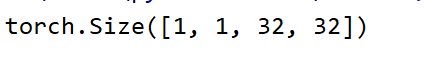
在反向传播前,先要将所有参数的梯度清零
net.zero_grad()
out.backward(torch.ones(1,10)) # 反向传播的实现是PyTorch自动实现的,我们只要调用这个函数即可
注意:torch.nn只支持mini-batches,不支持一次只输入一个样本,即一次必须是一个batch。
也就是说,就算我们输入一个样本,也会对样本进行分批,所以,所有的输入都会增加一个维度,我们对比下刚才的input,nn中定义为3维,但是我们人工创建时多增加了一个维度,变为了4维,最前面的1即为batch-size
损失函数
在nn中PyTorch还预制了常用的损失函数,下面我们用MSELoss用来计算均方误差
y = torch.arange(0, 10).view(1, 10).float()
criterion = nn.MSELoss()
loss = criterion(out, y)
#loss是个scalar,我们可以直接用item获取到他的python类型的数值
print(loss.item())
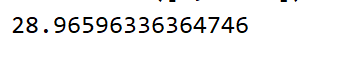
优化器
在反向传播计算完所有参数的梯度后,还需要使用优化方法来更新网络的权重和参数,例如随机梯度下降法(SGD)的更新策略如下:
weight = weight - learning_rate * gradient
在torch.optim中实现大多数的优化方法,例如RMSProp、Adam、SGD等,下面我们使用SGD做个简单的样例
criterion = nn.MSELoss()
loss = criterion(out, y)
# #loss是个scalar,我们可以直接用item获取到他的python类型的数值
# print(loss.item())
# 新建一个优化器,SGD只需要要调整的参数和学习率
optimizer = torch.optim.SGD(net.parameters(), lr = 0.01)
# 先梯度清零(与net.zero_grad()效果一样)
optimizer.zero_grad()
loss.backward()
#更新参数
optimizer.step()

这样,神经网络的数据的一个完整的传播就已经通过PyTorch实现了,下面一章将介绍PyTorch提供的数据加载和处理工具,使用这些工具可以方便的处理所需要的数据。
看完这节,大家可能对神经网络模型里面的一些参数的计算方式还有疑惑,这部分会在第二章 卷积神经网络有详细介绍,并且在第三章 MNIST数据集手写数字识别的实践代码中有详细的注释说明














 1406
1406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









