







torch.version
- 0.1.11
- 0.2.0_3我在使用
- 0.3
- 0.4.0
- 0.4.0版本去掉了
Variable,将Variable和Tensor融合起来 - 都变成了Tensor,可以视Variable为requires_grad=True的Tensor。其动态原理还是不变
- 0.4.0版本去掉了
- 1.0.1
- 大更新
- 1.2.0 支持Transformer
- 1.3.1
- 1.9.1 Pytorch目前最新版本
动态计算图
dynamic computation graph(DCG)
PyTorch autograd looks a lot like TensorFlow: in both frameworks we define a computational graph, and use automatic differentiation to compute gradients. The biggest difference between the two is that TensorFlow’s computational graphs are static and PyTorch uses dynamic computational graphs.
符号主义的计算首先定义各种变量,然后建立一个“计算图”,计算图规定了各个变量之间的计算关系。建立好的计算图需要编译以确定其内部细节,然而,此时的计算图还是一个“空壳子”,里面没有任何实际的数据,只有当你把需要运算的输入放进去后,才能在整个模型中形成数据流,从而形成输出值。
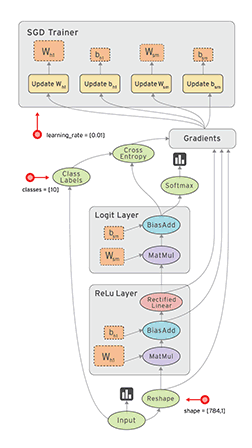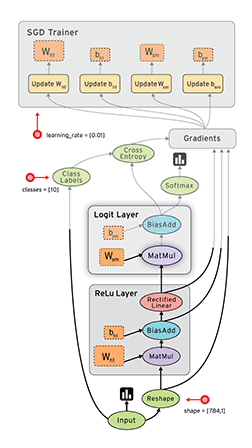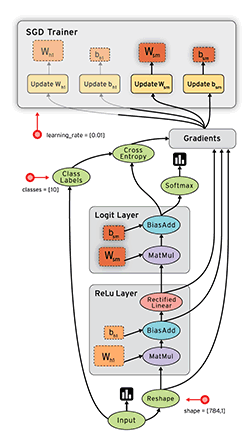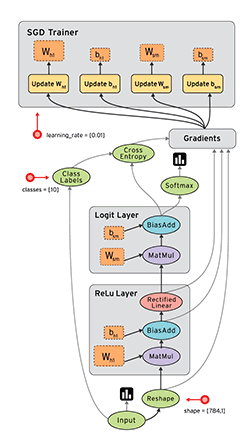
torch训练模型
编写一个深度网络需要关注的地方是:
- 网络的参数应该由什么对象保存
- 如何构建网络
- 如何计算梯度和更新参数
一个典型的神经网络的训练过程是这样的:
- 定义一个有着可学习的参数(或者权重)的神经网络
- 对着一个输入的数据集进行迭代:
- 用神经网络对输入进行处理
- 计算代价值 (对输出值的修正到底有多少)
- 将梯度传播回神经网络的参数中
- 更新网络中的权重
- 通常使用简单的更新规则: weight = weight + learning_rate * gradient
- 定义model
- model.train()
- model.train() tells your model that you are training the model. So effectively layers like dropout, batchnorm etc. which behave different on the train and test procedures know what is going on and hence can behave accordingly.
- More details:
- It sets the mode to train (see source code). You can call either model.eval() or model.train(mode=False) to tell that you are testing.
- It is somewhat intuitive to expect train function to train model but it does not do that. It just sets the mode.
- optimizer = torch.optim.SGD(net.parameters(), lr=0.5)
- 这一句代码中optimizer获取到了所有parameters的引用,每个parameter都包含梯度(gradient),optimizer可以把梯度应用上去更新parameter。
- for 循环中 epoch batch数据
- loss = loss_func(prediction, y)
- optimizer.zero_grad() 清除梯度数据,准备接受下一次的梯度数据
- loss.backward()
- 而梯度由这两句产生,第一句对prediction和y之间进行比对(熵或者其他loss function),产生最初的梯度,然后经由第二句反向传播到整个网络的所有链路和节点。节点与节点之间有联系,因此可以反向链式传播梯度。
- optimizer.step()
- 这一句是apply所有的梯度以更新parameter的值,这里不需要传入梯度,因为梯度的引用已经在其构造函数中传入的parameters中包含。
torch.nn.Module
* __init__(self, 构造参数1, 构造参数2, 构造参数3)
* 初始化网络参数
* bulid(self)
* 初始化网络模块
* init_weight(self)
* 初始化网络参数
* forward(self)
* 组织网络结构
*
torch.nn.ModuleList()
pass
pytorch 参数与数据维度
- 构建一个rnn网络最重要的两个参数
- input_size – The number of expected features in the input x
- hidden_size – The number of features in the hidden state h
- https://zhuanlan.zhihu.com/p/39191116
- RNN的output的维度和隐藏层状态的维度一致??
>>> rnn = nn.RNN(10, 20, 2)input_size, hidden_size, num_layers
>>> input = torch.randn(5, 3, 10) seq_len, batch, input_size
>>> h0 = torch.randn(2, 3, 20) num_layers * num_directions, batch, hidden_size
>>> output, hn = rnn(input, h0)
torch.nn.Embedding
如何加载预训练的embedding?
- https://blog.csdn.net/nlpuser/article/details/83627709
pytorch中nn.embedding的机制是什么?
pytorch中nn.embedding的机制源码中看不太懂,是使用了word2vec(如果是的话是skip-gram 还是cbow),还是随机赋值呢? - https://www.zhihu.com/question/278127788
- https://cloud.tencent.com/developer/article/1071455
原理
- 输出embedding层权重,embeds.weight,且使用t-sne进行可视化
- 调用 torch.nn.Embedding(m, n) 就可以了,m 表示单词的总数目voca_size,n 表示词嵌入的维度,其实词嵌入就相当于是一个大矩阵,矩阵的每一行表示一个单词。
- Pytorch官网的解释是:一个保存了固定字典和大小的简单查找表。这个模块常用来保存词嵌入和用下标检索它们。模块的输入是一个下标的列表,输出是对应的词嵌入。
- torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2, scale_grad_by_freq=False, sparse=False)
- 个人理解:这是一个矩阵类,里面初始化了一个随机矩阵,矩阵的长是字典的大小,宽是用来表示字典中每个元素的属性向量,向量的维度根据你想要表示的元素的复杂度而定。类实例化之后可以根据字典中元素的下标来查找元素对应的向量。输入下标0,输出就是embeds矩阵中第0行。而对于一个词,我们自己去想它的属性不是很困难吗,所以这个时候就可以交给神经网络了,我们只需要定义我们想要的维度,比如100,然后通过神经网络去学习它的每一个属性的大小,而我们并不用关心到底这个属性代表着什么,我们只需要知道词向量的夹角越小,表示他们之间的语义更加接近














 1995
1995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









