






线程锁,信号量这些同步方式使用简单,适用范围广。
但是效率比较低,性能比较差。
所以在一些特定场景,我们还是寻求效率比较高的无锁编程。
认识内存屏障(以linux系统为例):
编译器屏障: barrier()
CPU内存屏障: smp_mb(), smp_rmb(), smp_wmb()

例1:单例类

以我们代码当中的单例模板类为例,通常都是这种双重检查的写法。
但是这里面会有风险:
关键字new内部其实大概有几个关键步骤:
- void* tmp = operator new(sizeof(T)); // operator new
- tmp->T::T();
- pInstance = tmp;
由于编译期指令重排,存在2和3乱序的可能。
这种情况会导致另外的线程访问到没有构造完成的对象。造成不可预知的后果。
加入内存屏障的单例类

内存屏障并不能起到互斥的作用,只能保证单线程内的内存访问顺序。
所以这里还是要加互斥锁。
编译器保证内部静态变量是线程安全的 (c++11)

例2:

foo()和bar()在不同的线程执行
CPU硬件设计为了提高指令的执行速度,增设了两个缓冲区(store buffer, invalidate queue)。这个两个缓冲区可以避免CPU在某些情况下进行不必要的等待,从而提高速度。但是这两个缓冲区的存在也同时带来了新的问题。为了保证在多处理器的环境下cache仍然一致,需要一种协议来防止数据不一致和丢失。目前常用的协议是MESI协议。
所以本质上是多核CPU之间cache数据同步的问题,只是看起来像是CPU指令重排。对于这类问题,硬件设计者也爱莫能助,因为CPU无法知道变量之间的关联关系。所以硬件设计者提供了memory barrier指令,让软件来告诉CPU这类关系。
参考:https://blog.csdn.net/chen19870707/article/details/39896655

一. 使用内存屏障实现的无锁队列
适用场景:一个生产者线程,一个消费者线程
Linux内核的kfifo kfifo.h kfifo.c
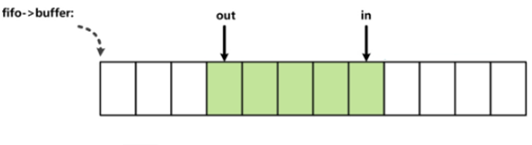
索引in和out被两个线程访问。in和out指明了缓冲区中实际数据的边界,也就是in和out同缓冲区数据存在访问上的顺序关系,由于不适用同步机制,那么保证顺序关系就需要使用到内存屏障了。 索引in和out都分别只被一个线程修改,而被两个线程读取。
二. 使用原子操作实现的无锁队列
适用场景:多个生产者线程,多个消费者线程
认识atomic_compare_exchange_weak

当前值与期望值相等时,修改当前值为设定值,返回true。当前值与期望值不等时,将期望值修改为当前值,返回false。这个函数可能在满足true的情况下仍然返回false,所以只能在循环里使用,否则可以使用它的strong版本。
int current, expected, set;
atomic_compare_exchange_weak(current, expected, set);
(current==expected) ? current = set : expected=current; 相当于这句代码的原子操作
RingBufferLockFree.hpp
#include <windows.h>
#include <iostream>
#include <thread>
#include <atomic>
#include <mutex>
#include <cassert>
#define DEFAULT_SIZE 32
template<class T, int64_t capacity = DEFAULT_SIZE>
class RingBufferLockFree
{
public:
RingBufferLockFree()
: buffer_(new T[capacity])
, flags_(new std::atomic<char>[capacity])
, capacity_(capacity)
, head_(0)
, tail_(0)
{
memset(flags_, 0, sizeof(*flags_) * capacity_);
}
// TODO
// RingBufferLockFree(const RingBufferLockFree&)
// RingBufferLockFree& operator=(const RingBufferLockFree&)
~RingBufferLockFree()
{
delete[] buffer_;
delete[] flags_;
}
/* flag:
0: 空闲
1: 写占用
2:写完成
3:读占用
*/
bool Push(const T& t)
{
int64_t nextHead = (head_ + 1) % capacity_;
if (tail_ == nextHead)
{
//std::cout << "queue is full!" << std::endl;
return false;
}
char expected = 0;
int64_t curHead = head_;
// 阻塞其他的写线程,等待head_更新完成,
// 而不必等待数据真正拷贝完成,读取时才需要等待数据拷贝完成
do
{
nextHead = (head_ + 1) % capacity_;
if (tail_ == nextHead) // 非阻塞
{
//std::cout << "queue is full!" << std::endl;
return false;
}
expected = 0;
curHead = head_;
} while (!std::atomic_compare_exchange_weak(flags_ + curHead, &expected, 1));
if (curHead == head_)
{
nextHead = (head_ + 1) % capacity_;
if (tail_ == nextHead) // head_跟进入函数时有变化,需要重新判断队列是否已满
{
std::atomic_fetch_sub(flags_ + head_, 1);
printf("queue is full!!!! %d, %d\n", head_, flags_[head_].load());
return false;
}
head_ = nextHead;
}
// 写线程竞争,head_已经被别的写线程更新,
// 但是当前写线程监测的curHead被读线程Pop之后flag位置0,
// 导致写入条件判断成功,但是head_已经更新了,如果写入curHead会导致顺序错乱,
// 所以返回错误,由调用者重新Push
/*
时刻1:
thread1 push head 8 block 在atomic_compare_exchange_weak
thread2 push head 8 block 在atomic_compare_exchange_weak
thread3 pop tail 7
thread2抢占了写操作,连续写了两条数据
thread3连续读了两条数据
时刻2:
thread1 push head 8 依然block 在atomic_compare_exchange_weak
thread2 push head 10 连续写了两条数据之后,head更新到10
thread3 pop tail 9 连续读了两条数据之后,tail更新到9 这时node8的flag为0
时刻3:
thread1 push head 8 读取到node8的falg为0,判断当前节点可写,但实际上当前的head_已经写到10了
*/
else
{
std::atomic_fetch_sub(flags_ + curHead, 1);
return false;
}
buffer_[curHead] = t;
std::atomic_fetch_add(flags_ + curHead, 1);
return true;
}
bool Pop(T& t)
{
if (tail_ == head_) return false;
char expected = 2;
int64_t curTail = tail_;
do
{
if (tail_ == head_) return false; // 非阻塞
expected = 2;
curTail = tail_;
} while (!std::atomic_compare_exchange_weak(flags_ + curTail, &expected, 3));
if (curTail == tail_)
{
if (curTail != head_)
{
tail_ = (tail_ + 1) % capacity_;
}
}
else
{
std::atomic_fetch_sub(flags_ + curTail, 1);
return false;
}
t = buffer_[curTail];
std::atomic_fetch_sub(flags_ + curTail, 3);
return true;
}
private:
T* buffer_;
std::atomic<char>* flags_;
int64_t capacity_;
int64_t head_;
int64_t tail_;
};
性能对比
在两个生产者线程,两个消费者线程极致竞争条件下(死循环读写),有锁队列耗时是无锁队列耗时的100倍。
2十万个64位整型数 两个线程push 两个线程pop
无锁队列:43ms 46ms 42ms 48ms
有锁队列:4583ms 3559ms 4781ms 3880ms
2百万个64位整型数 两个线程push 两个线程pop
无锁队列:350~400ms
有锁队列:35285ms 31271ms 33105ms 33966ms
2千万个64位整型数 两个线程push 两个线程pop
无锁队列:4096ms 3743ms 4192ms
有锁队列:419303ms 333117ms















 1310
1310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









