🔗 视频教程 Beautiful English 1> Aa~Zz2> al-pha-betAa>Bb>Pp>Rr>Yy> 1> Aa~Zz 2> al-pha-bet Aa> Bb> Pp> 第1画:上格1/2处起笔; 第2画:横起横收,肚子饱满 Rr> 第1画:上格1/2处起笔; 第2画:起笔水平,收在第1画1/2处; 第3画:斜线落笔,落在红色基线; Yy> Y: 第1画,倾斜一点; 第2画,倾斜更多; 第3画,倾斜线,85° y: 尾巴不要向上弯










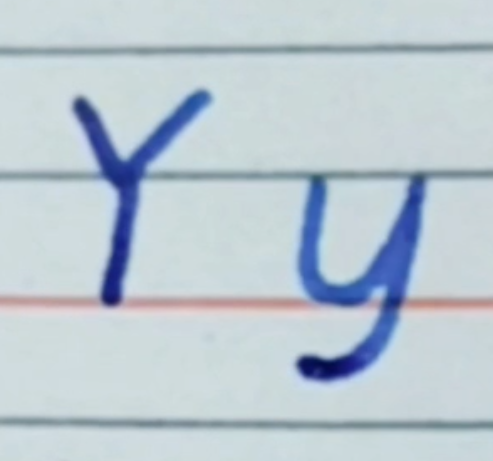

















 3850
3850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






