






一、Dropout是什么:
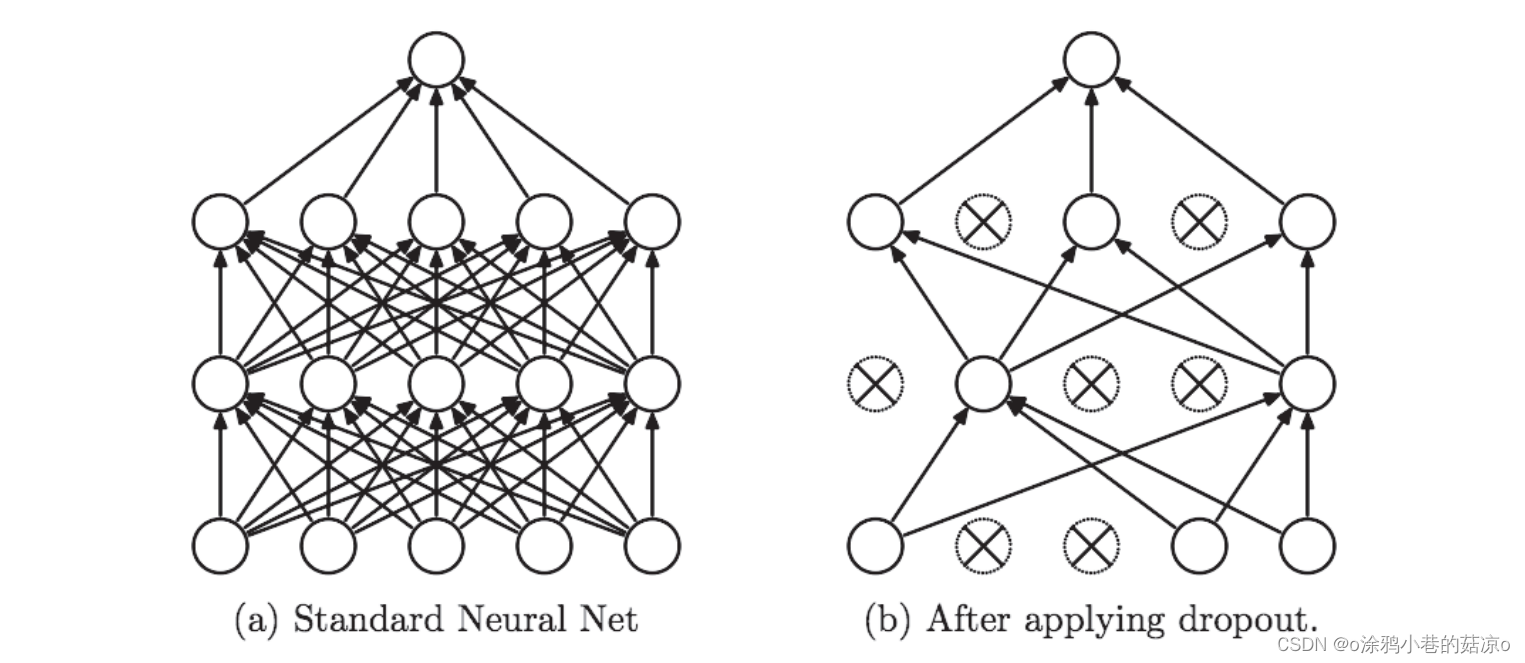
二、Dropout的工作原理和特点:
-
随机关闭神经元:在每个神经元被关闭的概率是相同的,这个概率是一个超参数。
-
前向传播时的关闭:在前向传播过程中,被关闭的神经元的输出值被设为零。这意味着每个神经元都可能在每个繁殖中被关闭,而不是始终激活。
-
逆向传播时的开启:在逆向传播过程中,被关闭的神经元不会接收到大量更新,它们的权重不会被调整。这意味着只有那些真正动员的神经元参与了权重更新。
-
集成学习效果:Dropout可以被调用是一种可以集成学习(Ensemble Learning)的方法,因为每次训练迭代都相当于训练了一个不同的子网络。通过平均或投票来集成多个子网络的预测,降低模型的仰角,提高泛化性能。
-
正则化效果:Dropout作为一种正则化技术,通常能够改善模型的泛化能力,减少过度,特别是在训练数据稀疏或较小的情况下。
-
关闭时的:在测试或推理训练时,Dropout通常是关闭的,所有神经元都保持开启状态。但是,为了保持测试的一致性,通常会在每个神经元的输出上乘以时关闭的概率的倒数,以平衡输出值的期望。
总之,Dropout是一种强大的正则化技术,用于改善神经网络的泛化性能,并减少过度的风险。它已经被广泛用于深度学习中的各种任务,包括分类、语音识别、自然语言处理等。
三、简化的 Dropout 类的代码示例:
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio # 指定丢弃的比例
self.mask = None # 用于存储丢弃的掩码
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio # 生成与输入形状相同的随机掩码
return x * self.mask # 在前向传播中应用掩码,以实现丢弃部分神经元
else:
return x * (1.0 - self.dropout_ratio) # 在测试或推理时,按比例缩放输出
def backward(self, dout):
return dout * self.mask # 反向传播时,根据之前生成的掩码进行相应的乘法操作
这个Dropout类有以下主要方法:
-
__init__: 类的初始化方法,指定用于丢弃的比例dropout_ratio,默认为0.5。 -
forward:正向传播方法,接受输入x和一个训练布尔值train_flg,用于判断是否为一个模式。如果在训练模式下,它会生成一个与输入x形状相同的随机掩码self.mask,输入x与掩码相乘,以实现丢弃一部分神经元。在测试或推理模式下,它会按比例缩放输出,以保持输出的期望值不变。 -
backward:逆向传播方法,接受最小dout,根据之前生成的预留码self.mask,对最小进行相应的乘法操作,以实现逆向传播。
四、 使用MNIST数据集进行验证,以确认Dropout的效果
代码如下:
import os
import sys
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.multi_layer_net_extend import MultiLayerNetExtend
# from common.trainer import Trainer
from common.optimizer import *
class Trainer:
def __init__(self, network, x_train, t_train, x_test, t_test,
epochs=20, mini_batch_size=100,
optimizer='SGD', optimizer_param={'lr': 0.01},
evaluate_sample_num_per_epoch=None, verbose=True):
self.network = network
self.verbose = verbose
self.x_train = x_train
self.t_train = t_train
self.x_test = x_test
self.t_test = t_test
self.epochs = epochs
self.batch_size = mini_batch_size
self.evaluate_sample_num_per_epoch = evaluate_sample_num_per_epoch
# optimzer
optimizer_class_dict = {'sgd': SGD, 'momentum': Momentum, 'nesterov': Nesterov,
'adagrad': AdaGrad, 'rmsprpo': RMSprop, 'adam': Adam}
self.optimizer = optimizer_class_dict[optimizer.lower()](**optimizer_param)
self.train_size = x_train.shape[0]
self.iter_per_epoch = max(self.train_size / mini_batch_size, 1)
self.max_iter = int(epochs * self.iter_per_epoch)
self.current_iter = 0
self.current_epoch = 0
self.train_loss_list = []
self.train_acc_list = []
self.test_acc_list = []
def train_step(self):
batch_mask = np.random.choice(self.train_size, self.batch_size)
x_batch = self.x_train[batch_mask]
t_batch = self.t_train[batch_mask]
grads = self.network.gradient(x_batch, t_batch)
self.optimizer.update(self.network.params, grads)
loss = self.network.loss(x_batch, t_batch)
self.train_loss_list.append(loss)
if self.verbose: print("train loss:" + str(loss))
if self.current_iter % self.iter_per_epoch == 0:
self.current_epoch += 1
x_train_sample, t_train_sample = self.x_train, self.t_train
x_test_sample, t_test_sample = self.x_test, self.t_test
if not self.evaluate_sample_num_per_epoch is None:
t = self.evaluate_sample_num_per_epoch
x_train_sample, t_train_sample = self.x_train[:t], self.t_train[:t]
x_test_sample, t_test_sample = self.x_test[:t], self.t_test[:t]
train_acc = self.network.accuracy(x_train_sample, t_train_sample)
test_acc = self.network.accuracy(x_test_sample, t_test_sample)
self.train_acc_list.append(train_acc)
self.test_acc_list.append(test_acc)
if self.verbose: print(
"=== epoch:" + str(self.current_epoch) + ", train acc:" + str(train_acc) + ", test acc:" + str(
test_acc) + " ===")
self.current_iter += 1
def train(self):
for i in range(self.max_iter):
self.train_step()
test_acc = self.network.accuracy(self.x_test, self.t_test)
if self.verbose:
print("=============== Final Test Accuracy ===============")
print("test acc:" + str(test_acc))
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
# 为了再现过拟合,减少学习数据
x_train = x_train[:300]
t_train = t_train[:300]
# 设定是否使用Dropuout,以及比例 ========================
use_dropout = False # 不使用Dropout的情况下为False
dropout_ratio = 0.2
# ====================================================
network = MultiLayerNetExtend(input_size=784, hidden_size_list=[100, 100, 100, 100, 100, 100],
output_size=10, use_dropout=use_dropout, dropout_ration=dropout_ratio)
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=301, mini_batch_size=100,
optimizer='sgd', optimizer_param={'lr': 0.01}, verbose=True)
trainer.train()
train_acc_list, test_acc_list = trainer.train_acc_list, trainer.test_acc_list
# 绘制图形==========
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, marker='o', label='train', markevery=10)
plt.plot(x, test_acc_list, marker='s', label='test', markevery=10)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()得出的效果:
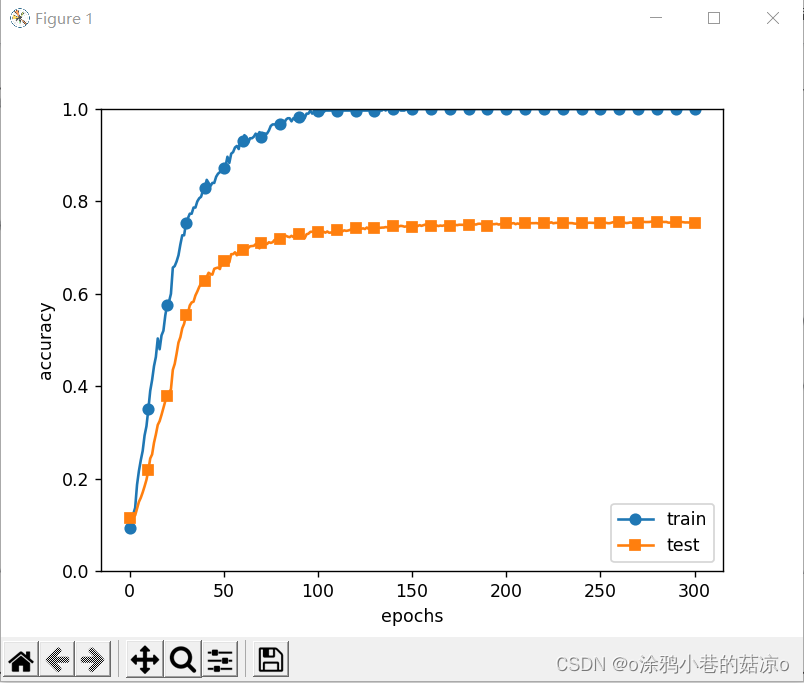

左边没有使用Dropout,右边使用了Dropout
















 31万+
31万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









