






----------------24年的端午假期结束啦,回来继续投入书的世界里---------------
一、表、栈、队列
1、抽象数据类型(abstract data type,ADT)
抽象数据类型,是一些操作的集合,用来描述数据的取值范围、结构和功能。我们知道实数、整数和布尔量这些数据类型有与它们相关的操作,而表、集合、图以及与它们相关的操作就可以看做是抽象数据类型。
2、表 ADT
形如A1、A2、…Ai-1、Ai、Ai+1、…AN的序列就是表。其称Ai-1前驱Ai,Ai+1后继Ai,而A1的前驱元不定义,AN的后继元也不定义。大小为0的表叫空表。
有了上面的对表数据类型的定义,我们就要在表ADT上实现与之相关的操作的集合。比如,34、12、52、16、12是一个表,那么操作find(52)就返回其位置3,操作insert(X,3)就会使表变成34、12、X、52、16、12,而delete(52)就会把52从表中删除。
2.1 实现:数组
显然,对于上述定义的表数据类型,我们可以用数组全部实现。但使用数组来实现会有很大弊端。想、首先,表的大小在程序中可能会因为需要而大小不定,那么数组该开多大的内存?一般都会比表的最大估计值要再大一些以满足后续运算,这样难免造成浪费。另外,数组在空间上是连续的,插入和删除操作会花费相当的时间,比如在位置0插入一个数据,那么首先程序就要把数组里所有数据都往后挪一个位置,再在位置0空位填入该数据,而如果删除位置0的数据,那么在位置0数据被删除后,后面所有数据还得全部往前移动一个位置,这样才能是数组名为起始地址的连续空间的数组。可见,这种删除和插入的操作所花费时间最坏的情况是O(N)。
基于删除和插入操作的时间如此慢,以及表的大小必须事先定好,所以数组一般不用来实现表这种结构。
2.2 实现:链表
前面讲数组对于插入和删除的线性时间开销,归根结底是数组这种数据类型在内存空间上是连续的这种特点造成的。所以为了避免这种线性开销,表可以不连续存储,否则还会要全部或部分整体移动。
链表就可以解决这种问题,学过FreeRTOS的同学会对链表再熟悉不过了,它由一系列不必再内存上连续的结构体组成。你可能会问?在内存上不连续,那么我要怎么找到其中某个成员,因为不能像使用数组名为基地址,索引为偏移量来方便查找元素了?答案是指针!链表使用指针,将不同区域的结构勾连起来,这些指针如同钩子一般,可挂在链表上,也可以随时取下,就如同有很多钩子的晾衣架一般。链表分为单链表和双链表:
(1)单链表: 链表由一个个节点Node组成,每个节点是一个结构体,这个结构体除了可携带一些私有信息外,必须包含一个结构体指针,用于指向下一个节点。
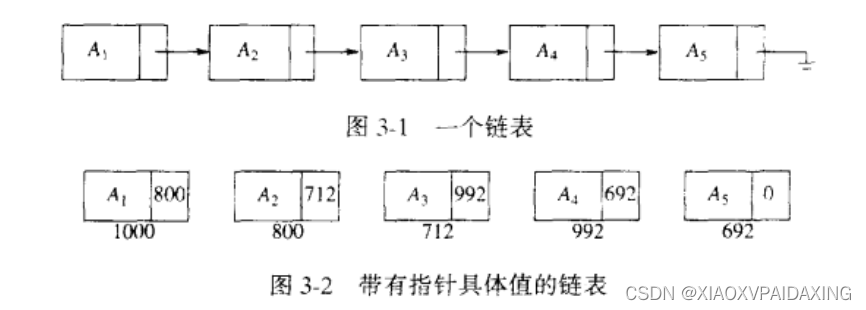
上图是一个单链表,包含很多个节点,它们在内存上都不连续,比如这5个节点的地址分别是1000、800、712、992、692。然后每个结构里都包含一个NEXT指针,该指针指向链表里下一个结构的位置,比如A1里的指针800就指向了A2的地址,所以通过A1的指针我们就可以查到内存上非连续成员的位置,同理A2里的指针712指向了A3,A3的指针992指向了A4的地址,A4的指针692指向了A5的地址,而链表最后一个成员A5的指针指向NULL(0)。如此一来,就可以实现非连续结构了。
这时候,我们再来看插入操作:
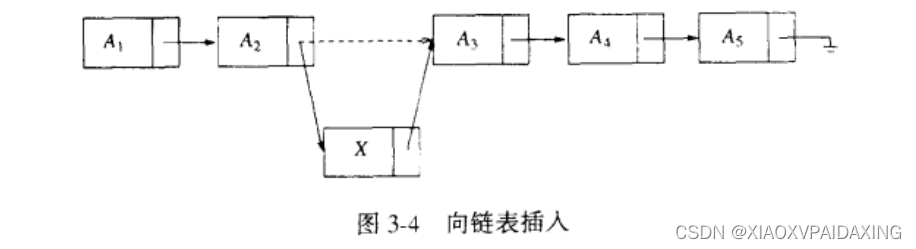
如上图,要在A2和A3之间插入一个结构,只需把指针部分的值改一下即可,先调整A2指向X,再将X执行A3就完成了插入,可见对比与数组需要移来移去就简单了很多。(注意,这些箭头和虚线只是表示逻辑上的先后顺序,也就是在链表中的先后关系,而在内存上就不一定了,内存上完全没有规定,全看编译器怎么开内存了,这A1、A2、X、A3、A4、A5可能分散在内存各个角落里,它们之间的先后关系只是通过指针联系起来。)
我们再来看看删除操作:

如上图,删除操作就更加简单了,只需修改一次指针,比如要把A3从这个链表关系中删除,只需要把A2修改为指向A4就完成了。这样一来从A1开始检索的话,按照指针指引关系,就是A1到A2,再到A4、最后到A5,可见A3就不会再作为链表成员被依次检索到了,也及时从这段关系中剔除掉了。
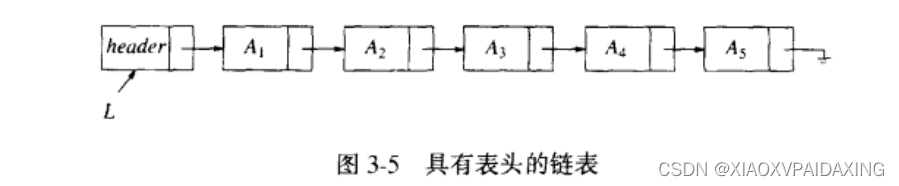
最后,程序实现上述想法之前,一般可以选择如上图所示的结构,就是添加表头(header),添加表头能够解决许多内在小问题。
struct Node;
typedef struct Node* PtrToNode;
typedef PtrToNode List; //结构体指针List
typedef PtrToNode Position;//结构体指针Position
//节点结构体
struct Node
{
int Element;//单个数据
Position Next;//结构体指针变量,必须有,用于指向下一个节点Node
};
接下来就要实现单链表的一些操作函数:
//创建一个函数,查看链表是否为空
int IsEmpty(List L)
{
return L->Next == NULL;//返回true或者false,根据表头有无后继可以知道链表是空的还是非空
}
//创建一个函数,查看当前位置是否是链表的末尾
int IsLast(Position P, List L)
{
return P->Next == NULL;//返回true或false,根据当前位置有无后继元可判断是否为最后一个
}
然后可以实现查找、删除、插入函数:
//创建一个函数,返回元素X所在结构的前驱元
Position FindPrevious(int x, List L)
{
Position P;
P = L;
while (P->Next != NULL && P->Next->Element != x)
P = P->Next;
return P;//要么P是最后一个(当next时null时),要么是找到了其后继元含有x的P
}
//查找:Find函数,查找元素x在链表L的哪个结构(位置)中
Position Find(int x, List L)
{
Position P;
P = L->Next;
while (P != NULL && P->Element != x)
P = P->Next;
return P;//要么P是最后一个,要么是找到了含有x的P
}
//删除:Delete函数,删除链表L中的某个元素x
//删除第一次出现的x,如果无那就什么也不做
void Delete(int x, List L)
{
Position P, TmpCell;
P = FindPrevious(x, L);
if (!IsLast(P, L))//若不是最后一个,那么就是找到了含有x的结构体的前驱元P
{
TmpCell = P->Next;//因为P->Next是要被删除的那个,所以先保存指针到暂时变量中
P->Next = TmpCell->Next;//修改指针,使要被删除的那个结构体的前驱和后驱直接连起来,
free(TmpCell);//然后就可以删除该结构体了
}
}
//插入操作:Insert函数,将x保存为表元之一插入到链表的位置P中
void Insert(int x, List L, Position P)
{
Position tmpCell;
tmpCell = malloc(sizeof(struct Node));//动态分配
if (tmpCell == NULL)
printf("out of space!!!");
tmpCell->Element = x;
tmpCell->Next = P->Next;
P->Next = tmpCell;//就是插入到原本链表的位置P和位置P->Next之间。
}
//删除整个表
void DeleteList(List L)
{
Position P, tmp;
P = L->Next;//获取第一个表元
while(P != NULL)
{
tmp = P->Next;//注意先保存P的下一个指向,再删除P,否则在删除P之后,就没法通过P获取到next了
free(P);
P = tmp;
}
}
(2)双链表: 在单链表的基础上,在结构体内再增加一个指针变量,用于指向前一个节点。另外,尾部节点next指针不指向null,而是第一个节点,同样首节点的previous指针指向最后一个节点,如下图所示:
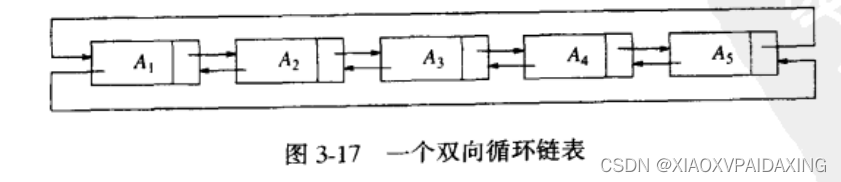
编程实现上类似,可以参考FreeRTOS的源码。
3、栈 ADT
栈就是限制插入和删除只能在栈顶位置进行的一个表,所以栈顶位置也叫表的末端。基本操作有进栈和出栈,对应的就是表的插入和删除。栈,有时也称作后进先出表(LIFO):如下图所示
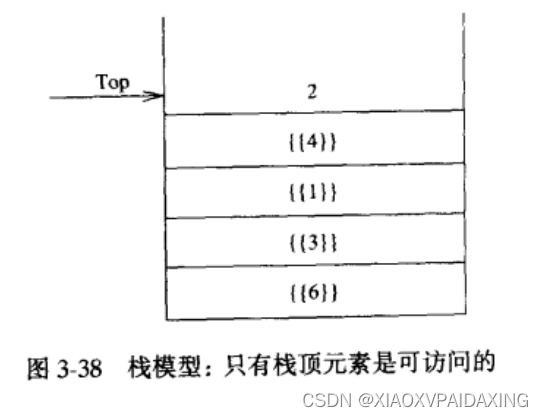
因为栈其实就是一个表,所以任何实现表的方法都能实现栈。
3.1、链表实现:
单链表:在表顶端插入元素来实现push,在表顶端删除元素来实现pop。链表头header的next就是链表顶端成员,其他成员依次往后next。所有实现方法都只能在顶端进行。
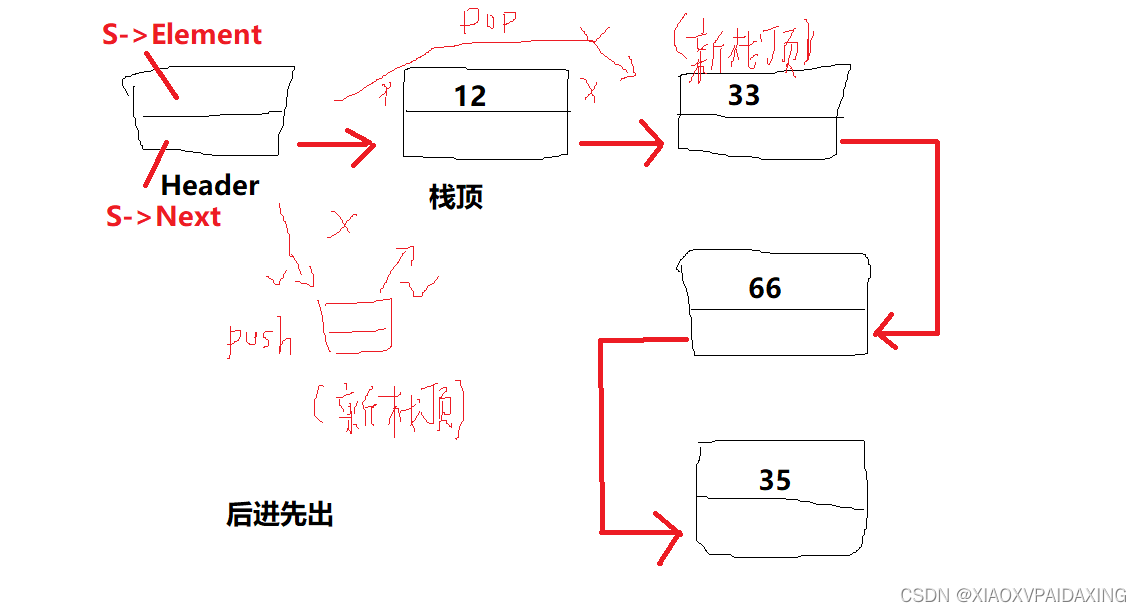
struct Node;
typedef struct Node* PtrToNode;
typedef PtrToNode Stack; //结构体指针Stack
struct Node
{
int Element;//单个数据
PtrToNode Next;//结构体指针变量
};
操作方法如下:
//创建一个函数,判断栈是否为空
int IsEmpty(Stack S)
{
return S->Next == NULL;//返回true或false
}
//创建一个函数,实现一个空栈
void MakeEmpty(Stack S)
{
if (S == NULL)
printf("Must use CreateStack() first");
else
while (!IsEmpty(S))
Pop(S);
}
Stack CreateSatck(void)
{
Stack S;
S = malloc(sizeof(struct Node));
if (S == NULL)
printf("out of space!!!");
S->Next = NULL;
MakeEmpty(S);
return S;
}
//push进栈
void Push(int x ,Stack S)
{
PtrToNode tmpCell;
tmpCell = malloc(sizeof(struct Node));
if (tmpCell == NULL)
printf("out of sapce!!!");
else
{
tmpCell->Element = x;
tmpCell->Next = S->Next;
S->Next = tmpCell;//其实就是表的插入,只不过只能在栈顶Stack上插入,这样tmpCell就是栈顶第一个成员了
}
}
//pop出栈
void Pop(Stack S)
{
PtrToNode FirstCell;
if (IsEmpty(S))
printf("Empty stack");
else
{
FirstCell = S->Next;//获得第一个要被弹出的
S->Next = S->Next->Next;//更新修正指针
free(FirstCell);//其实就是表的删除,只不过只能在栈顶上删除
}
}
//创建一个函数,返回当前栈顶成员的值
int Top(Stack S)
{
if (!IsEmpty(S))
return S->Next->Element;
printf("Empty stack");
return 0;
}
3.2、数组实现:
对于栈操作,其实使用数组是更加流行的做法,只不过要提前声明一个某大小的数组,但因为在一般程序中栈的元素个数都不会太大,所以可以声明一个数组来实现而又不会太浪费空间。(如果不太可行,那就用前面的链表实现吧)
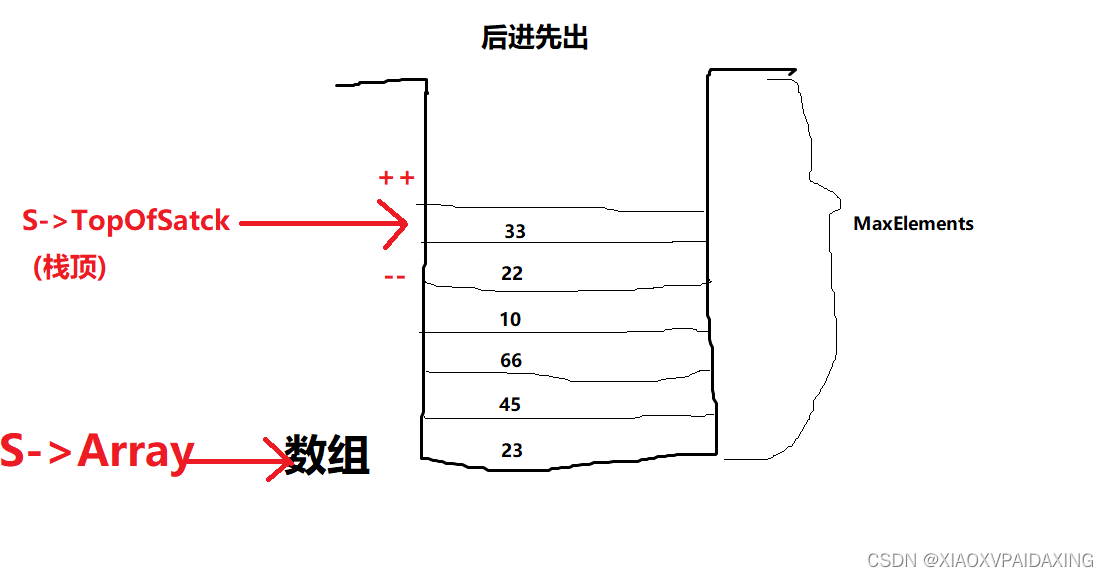
struct StackRecord;
typedef struct StackRecord* Stack;
#define EmptyTOS (-1)
#define MinStackSize (5)
struct StackRecord
{
int Capacity;//表示堆栈数组大小
int TopOfSatck;//数组索引,表示栈顶位置
int* Array;//指针,数据所在的数组
};
实现方法很简单,就是常规的数组操作:
Stack CreateStack(int MaxElements)
{
Stack S;
if (MaxElements < MinStackSize)
printf("stack size is too samll");
S = malloc(sizeof(struct StackRecord));
if (S == NULL)
printf("out of space!!!");
S->Array = malloc(sizeof(int) * MaxElements);
if (S->Array == NULL)
printf("out of space!!!");
S->Capacity = MaxElements;
MakeEmpty(S);
return S;
}
//创建一个函数,释放栈
void DisposeStack(Stack S)
{
if (S != NULL)
{
free(S->Array);
free(S);//注意要先释放数组,再释放该结构体,因为都是动态分配的,而且数组指针在结构体内
}
}
//创建一个函数,判断堆栈是否为空
int IsEmpty(Stack S)
{
return S->TopOfSatck == EmptyTOS;//返回true或者false,空则为-1,否则不是-1
}
//创建一个函数,将栈顶索引置为-1,表示目前栈为空
void MakeEmpty(Stack S)
{
S->TopOfSatck = EmptyTOS;
}
//Push:进栈
void Push(int x, Stack S)
{
if (IsFull(S))
printf("Full stack");
else
S->Array[++S->TopOfSatck] = x;//索引先自增再填入,所以栈顶索引始终指向最近进来的成员
}
//Pop出栈
void Pop(Stack S)
{
if (IsEmpty(S))
printf("Empty stack");
else
S->TopOfSatck--;//弹出只需要模拟索引自减,反正TopOfSatck只要一直指向栈顶即可
}
//Top返回栈顶元素
int Top(Stack S)
{
if (!IsEmpty(S))
return S->Array[S->TopOfSatck];//直接返回栈顶元素
printf("Empty stack");
return 0;
}
4、队列 ADT
如同栈一样,队列(queue)也是一个表。只不过,不同的是,队列这种表要求在队的一端压入,再另一端弹出,类似生活中的排队,遵循先进先出(FIFO)。所以,也很容易知道,队列的基本操作就是,入队,就是在队尾插入一个元素;而出队,就是在删除或返回队首的元素。
因为和栈一样是一个表,所以也是任何表的实现都可以。不管是链表实现还是数组实现,都可以给队列带来快速的运行时间。
关于链表实现可自行编程,这里讨论数组实现(FreeRtos里的队列实现也是类似的,不过RTOS里一般会使用的是动态分配内存来创建):
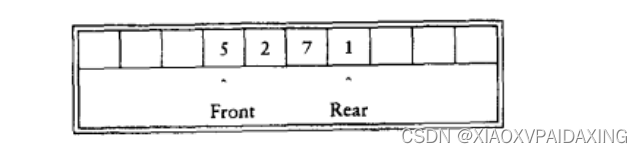
如上图所示,对于一个队列数据结构,使用数组Array[],以及Front和Rear分别表示队首和队尾,Size表示队列元素综述。当要将一个元素X入队时,Rear++,Size++,然后Array[Rear]=X;当要出队的时候,return Array[Front],然后Front++,Size–。不过会有一个问题,就是随着入队和出队的积累,因为不管入队还是出队,两个指向Front和Rear都会右移,所以一定会抵达数组最右端,但这不就溢出了吗?
办法就是,当移动到数组尾部时,我们就让它直接回指向数组首部,也就是所谓的循环数组。
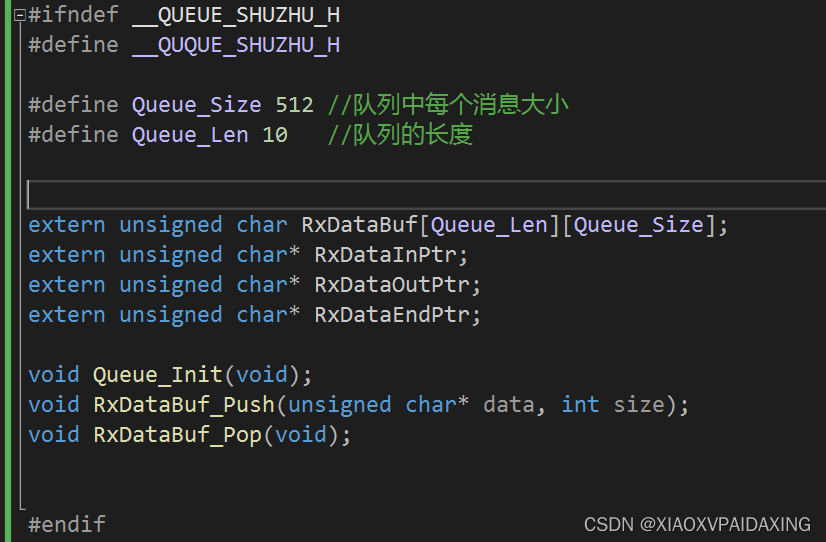
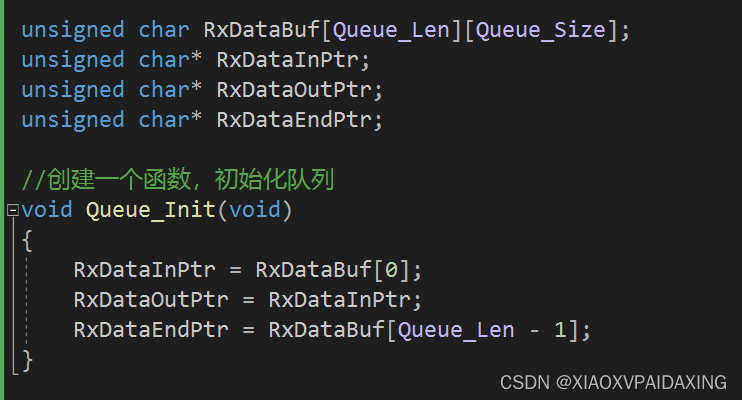
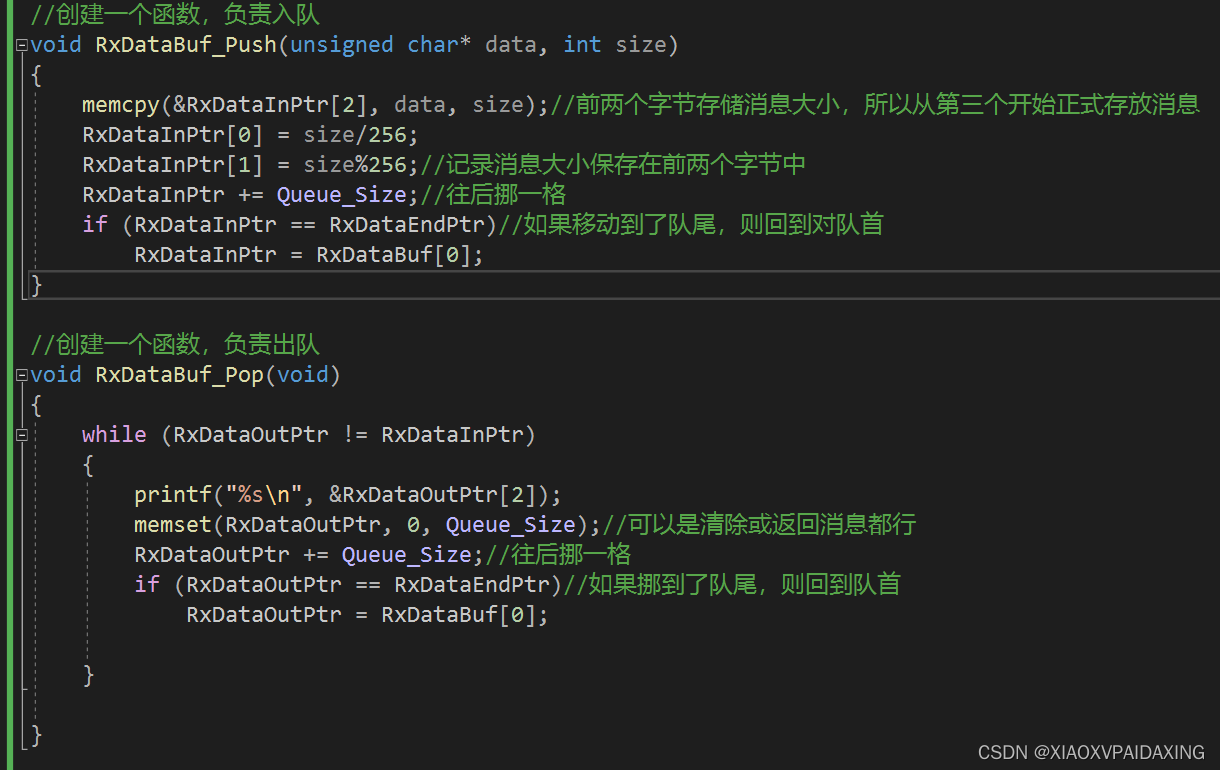
程序实现:鉴于书中给的程序不太齐全,且主要偏向于简单介绍,所以这里不打算用书的实现了。所以换一种实现方式,更实用些,如下所示:
入队操作从inptr指针开始,每来一个消息,就往后挪1个消息单位;而出队则从outptr指针开始,当intptr和outptr相等时就认为没有消息要出队处理,否则就一种往后挪出队,直到再次与inptr相等。两指针如果挪到endptr指针位置,那么就会回到队首。如此一来,就能实现队列定义所说的内容。
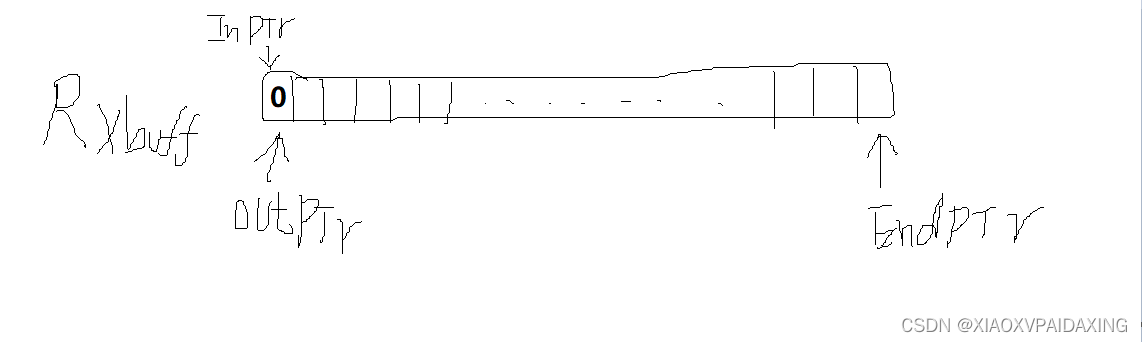
实现上述功能后,就可以在主程序进行测试了,如下图所示,在键盘上敲入字符,先进行入队,然后出队,看看是否能成功运行?
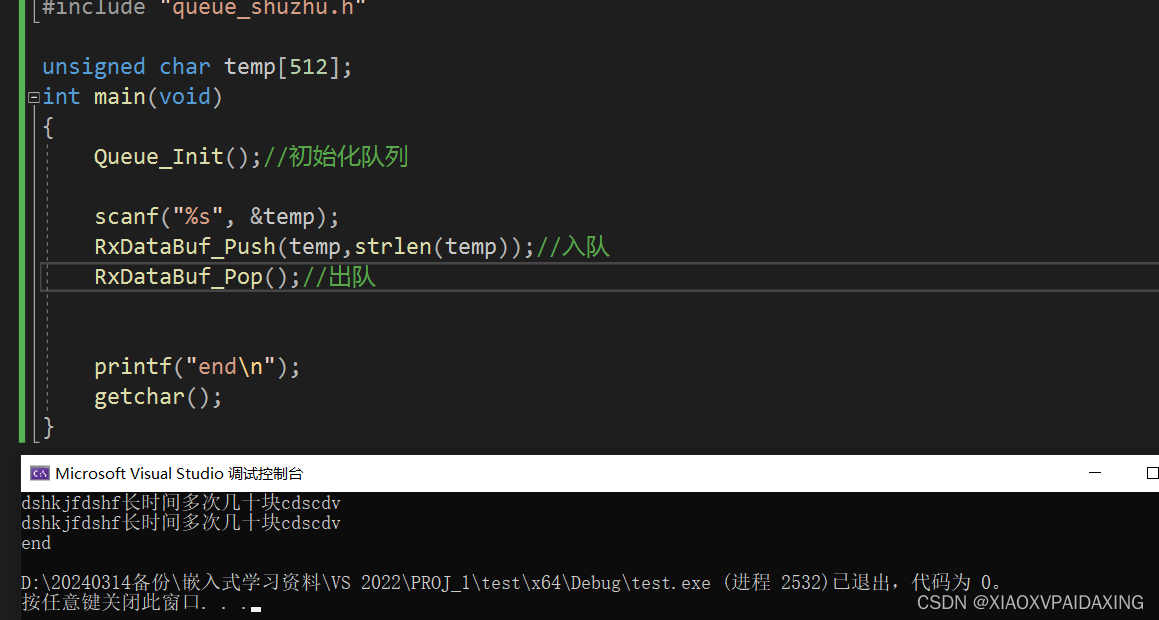
可以看到,能成功进行入队和出队操作,接着再来测试一下,当空间用完了能否回到队首而非溢出:
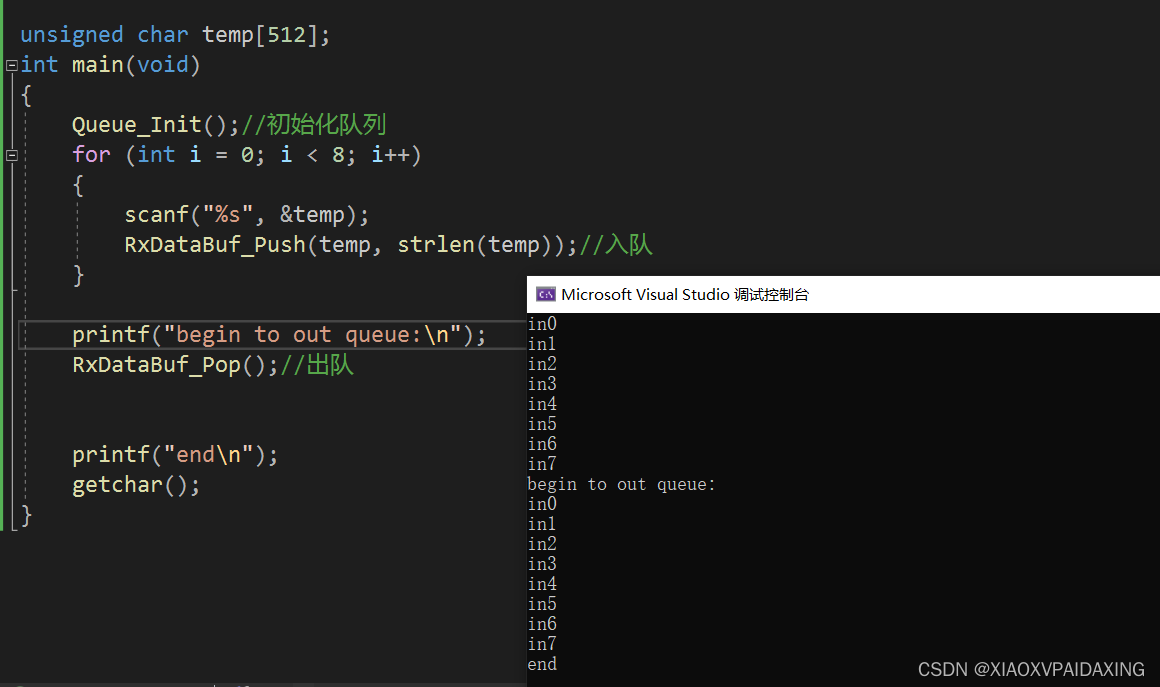
上图是入队8个消息的时候,出队打印了8个消息。注意。因为队列一个10个大格子,编号为0到9号,其中第9号标记为Endptr不会被用,所以如果inptr指向第8个用完后,自增挪到9号,就会等于endptr,那么指针就会立刻回到队首,所以endptr指向的那个格子是不会被用到的。
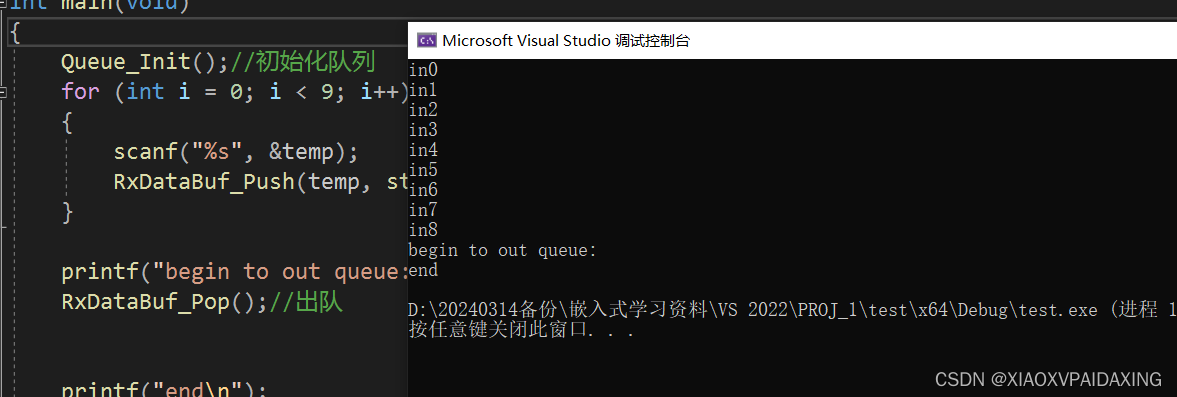
上图所示为入队消息9个的时候,因为inptr指针回到了队首,此时outptr也还没动仍在队首,两者相同,所以就没有出队操作!也就是还没来得及出队,intptr就在此与outptr相等了。
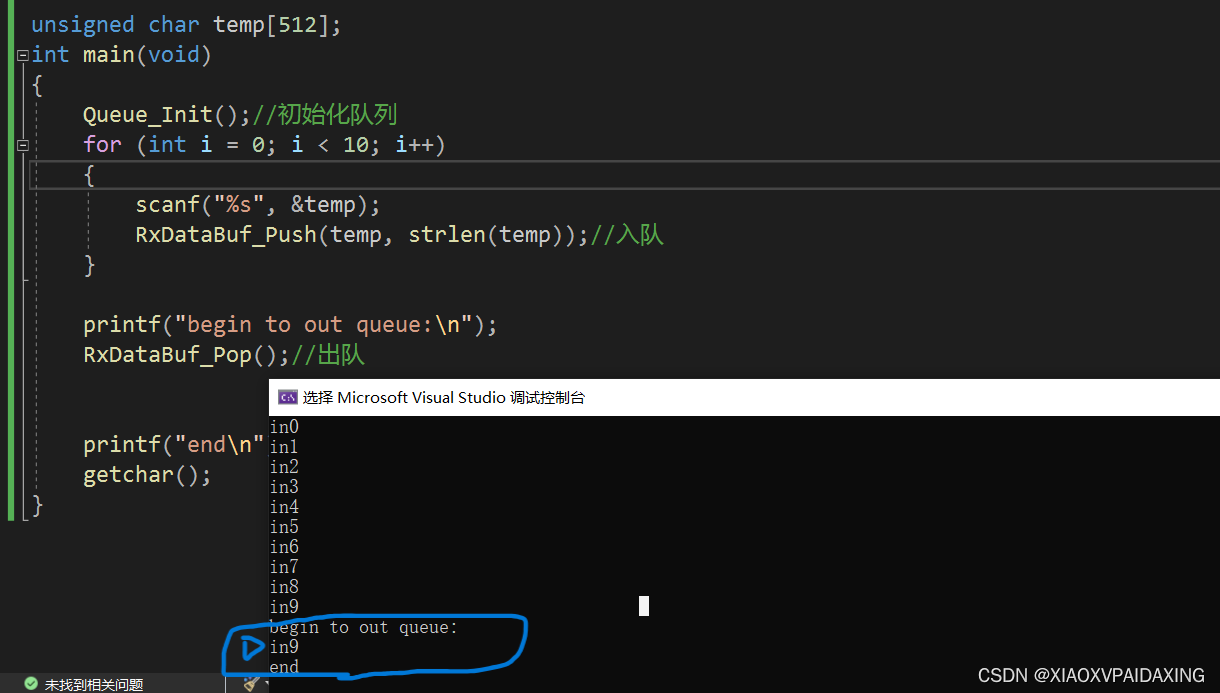
如上图所示,为入队消息为10个的时候,因为此时不仅inptr回到了队首,而且还继续往后挪了1格,存放"in9",所以此时inptr与outptr不等,两者相差1格,所以就会出队“in9”,然后outptr往后挪动1格,然后就两种再次相等,两指针相等后就不会出队了。
上述的数组实现仅供参考,因为这只是一种比较粗糙的队列实现而已,还有很多其他更好更优秀的方法或编程方式去利用数组来实现它。
--------------------思考良久,我觉得做事要有始有终,所以还是也把链表实现也整理下吧--------------------
队列的链表实现:为方便增删查改,使用双向链表
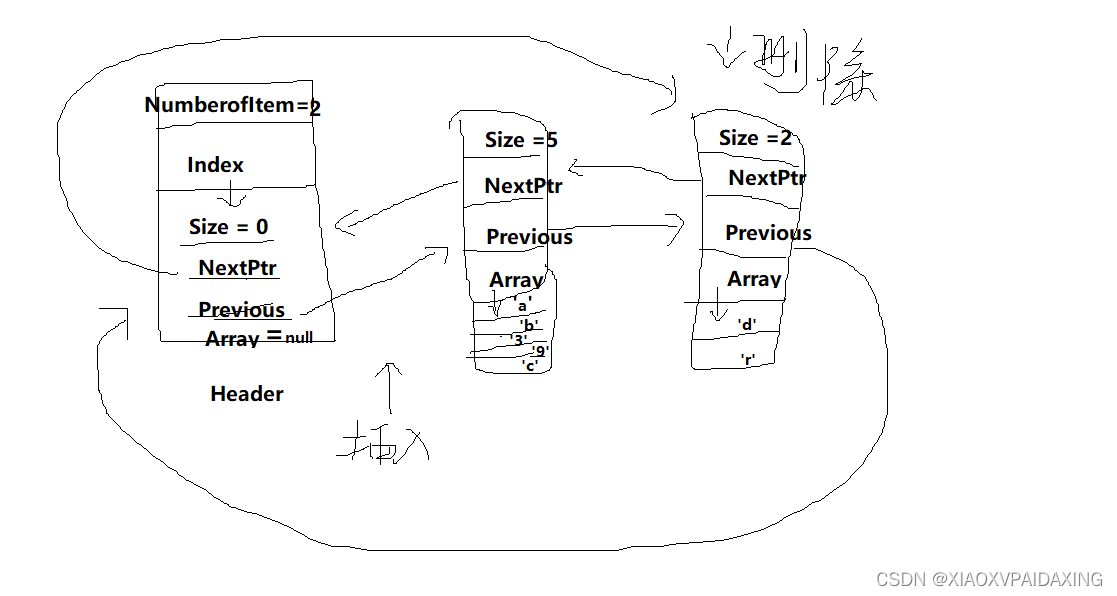
如上图所示,使用双向链表,其中Header为链表头,当做表尾表示,通过Header就可以定位插入(入队的地方)即Header->Previous,以及删除(出队的地方)即Header->NextPtr。所以也就能实现队列定义所说的一端进,一端出。
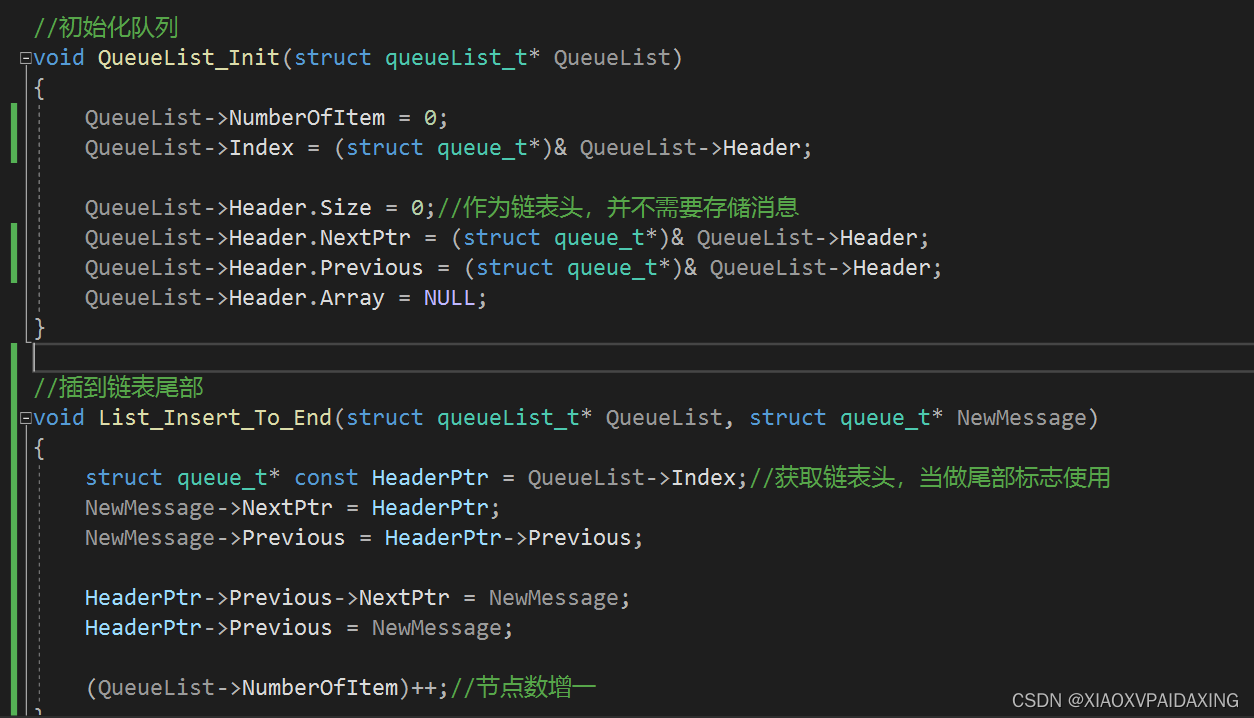
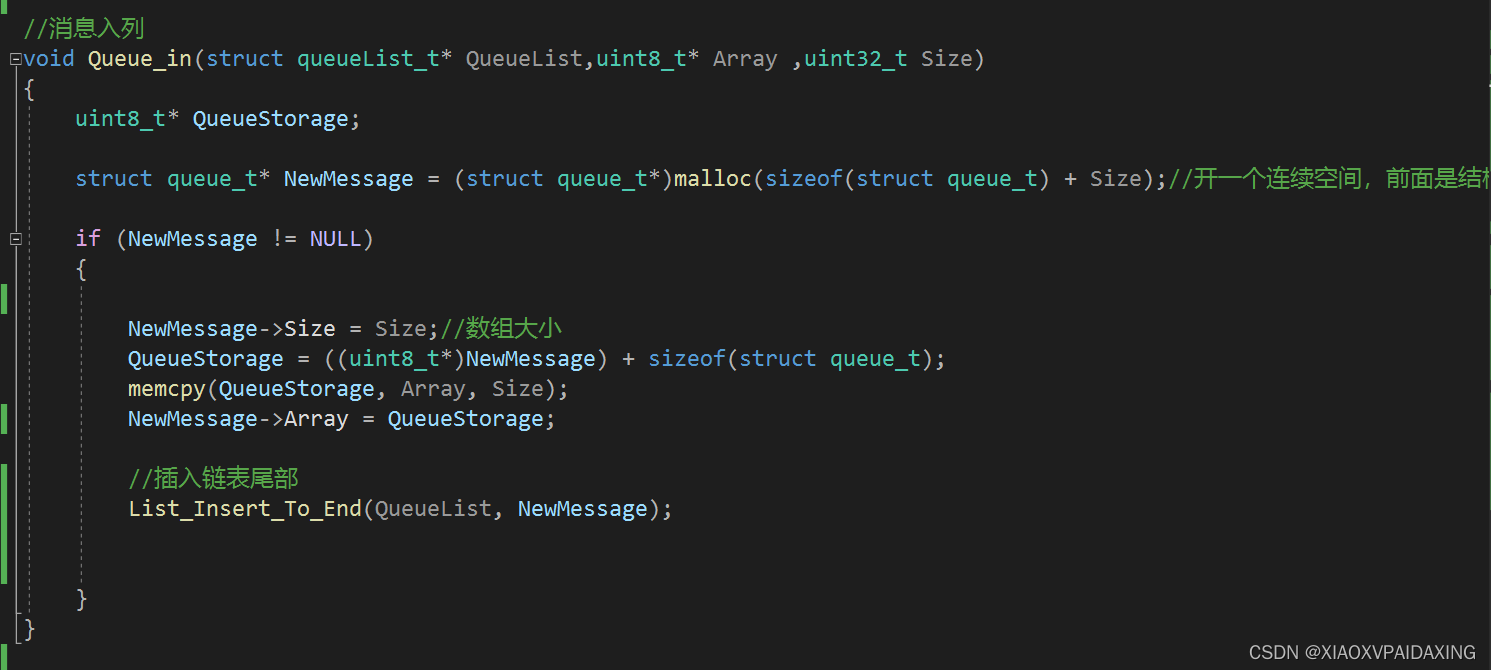
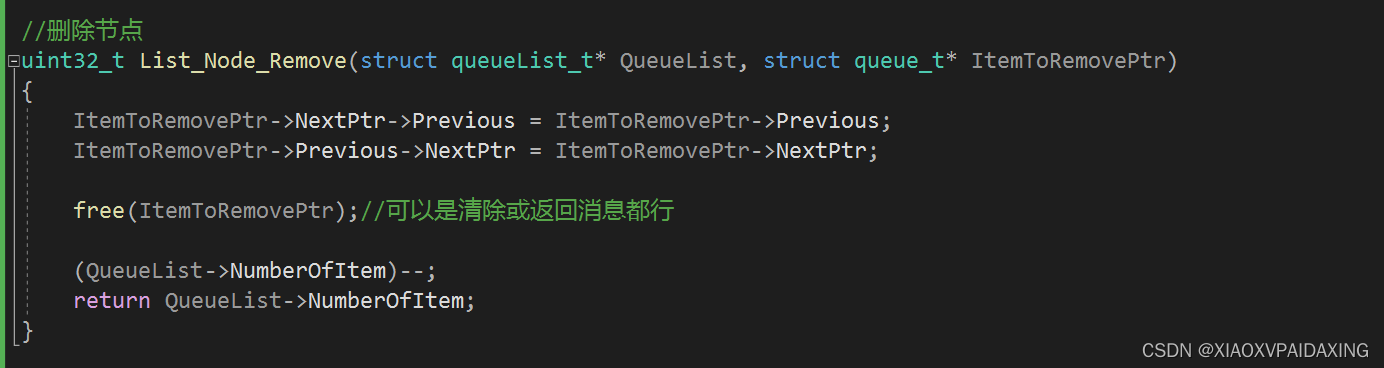
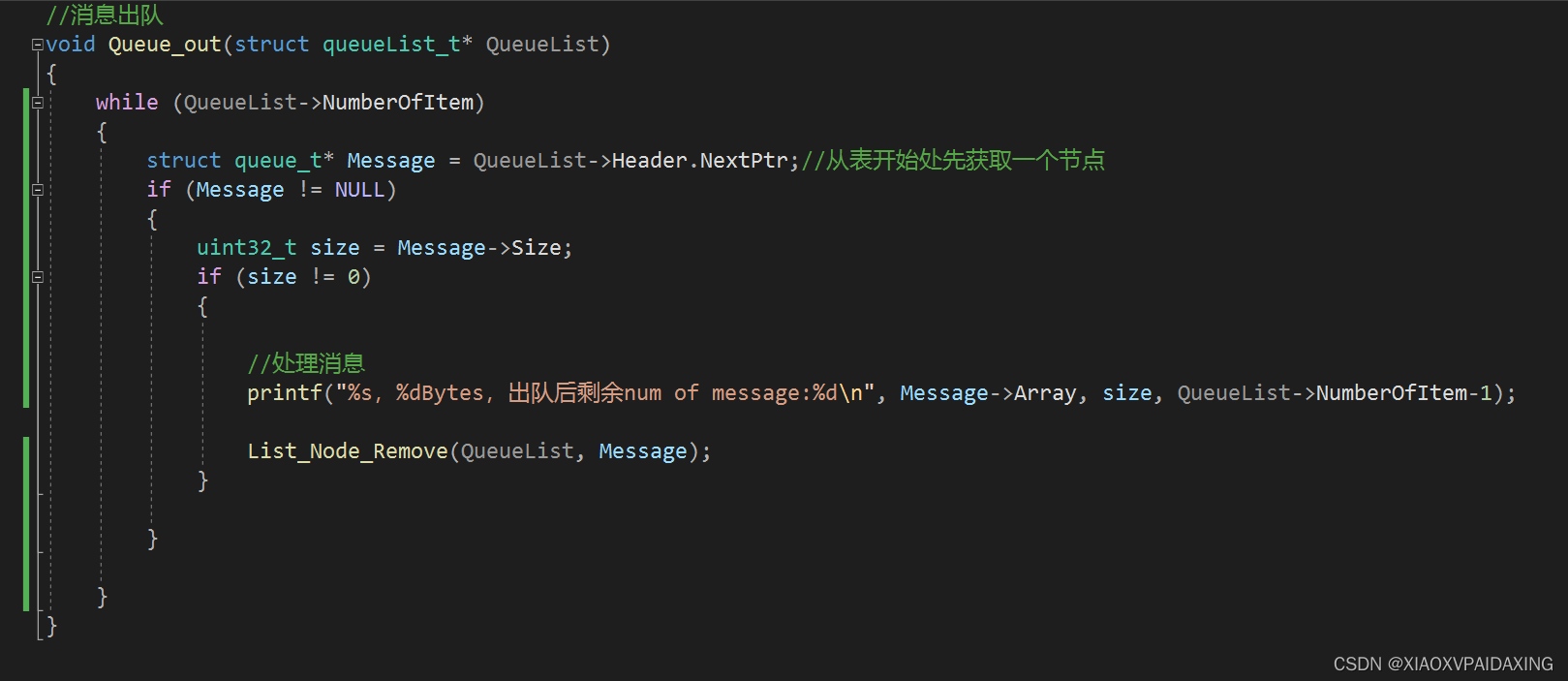
程序写好了,那么接下来看看运行效果:如下图所示
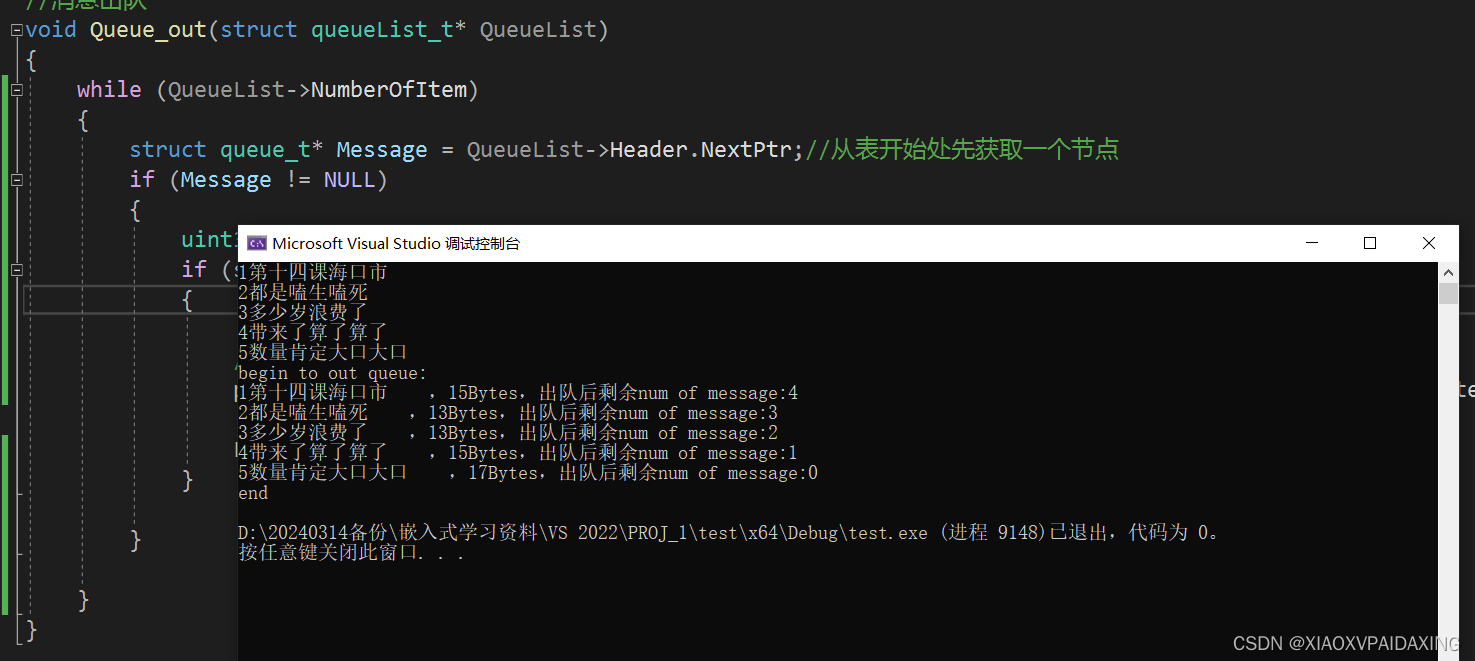
可以看到,先入队的先出队,后入队的后出队,说明该双向链表能够完成队列的基本功能。
通过对比,可以发现,链表实现的队列比起数组实现大的队列有许多优点,因为链表是即用即分配内存,而且是你的消息多大就动态分配多少内存来存储,几乎不怎么浪费空间(而数组方式需要定好单个消息的最大占用空间以便进行数组空间的分配,但是,有时候我们发送的消息很短占用空间小,有时候又很长占用空间大,那么数组方式定好每个消息体的空间就很死板而且浪费)。另外就是链表是不需要连续的存储空间的,各个节点可以是内存任何区域,哪怕是各自一块一块断断续续都行,通过链表来联系起来,这样就会避免了因内存碎片化而导致无法分配足够大一块内存的风险(显然数组方式不管是事先开一块大连续内存来用,还是用的时候再动态分配一块大内存,都要求是一块连续的大内存,这一点就不如链表方式的灵活)。
到这里,关于表、栈、队列就介绍完毕了,如果又好的想法也会继续修改更新!
------------------------------------补充:队列的单向链表C实现-----------------------------------------------------
队列的链表实现:单向链表如下所示:
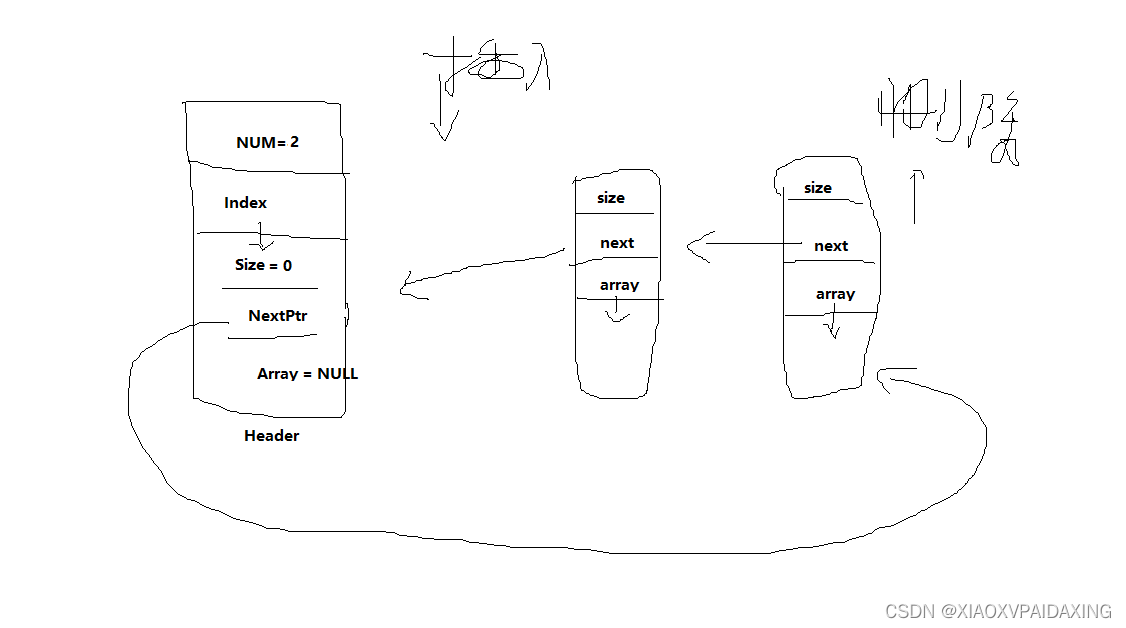
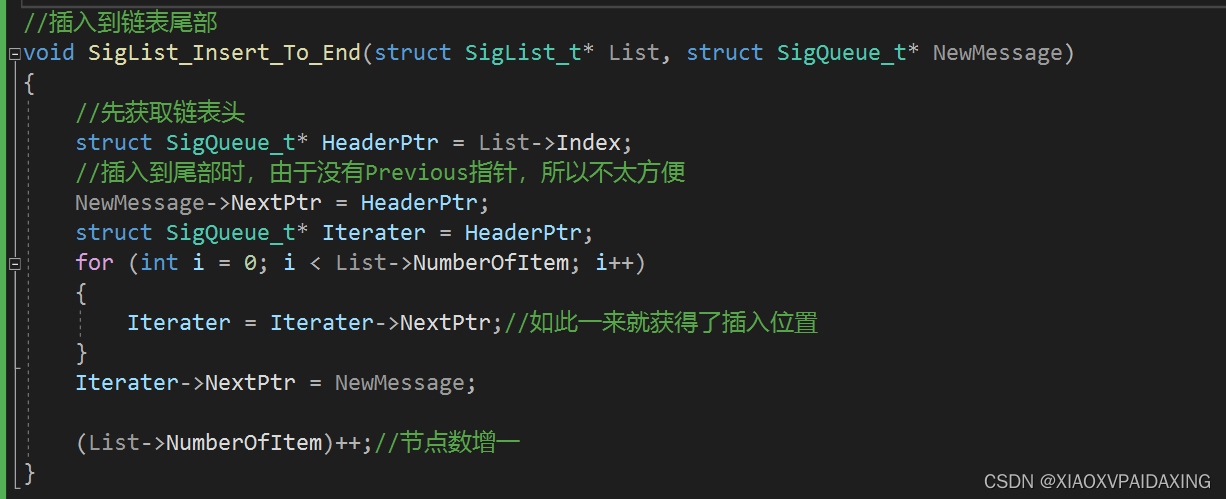
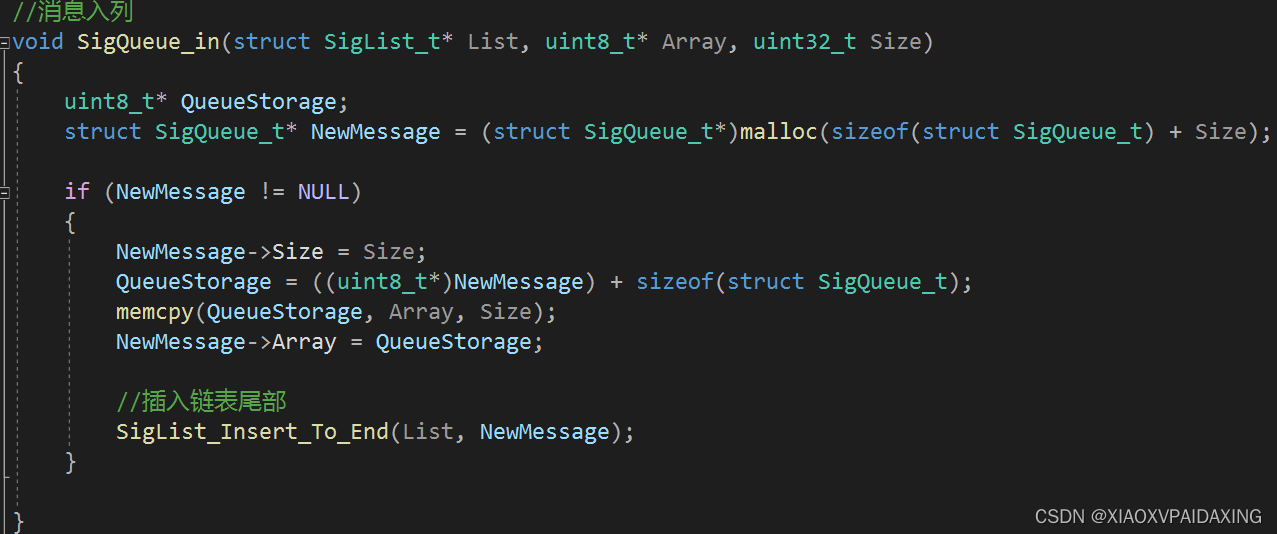
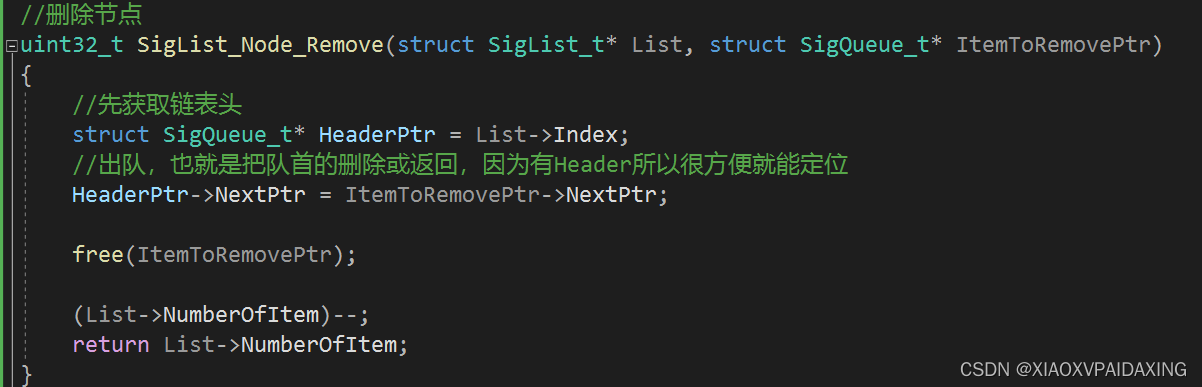
如上图所示,入队的话(就是插入队尾,找到Header的前一个节点就能定位和执行插入操作了),对于出队的话(就是删除或返回队首消息,直接从Header->NextPtr就可定位了),所以实现起来还是挺简单的,就是入队操作会行为花点时间,尤其是消息数很多的时候。
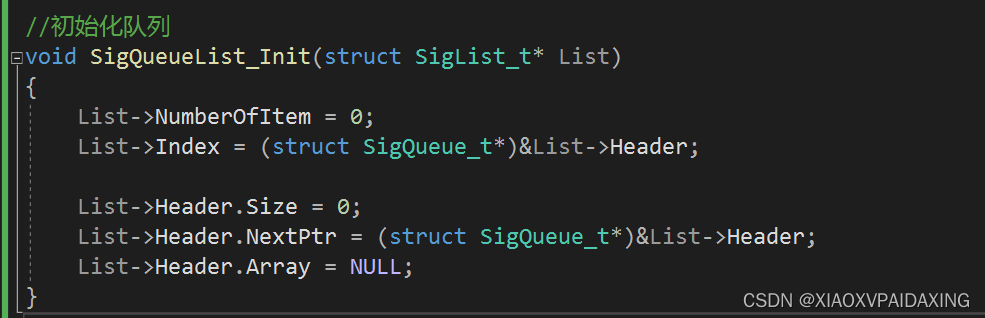
C编程如下:
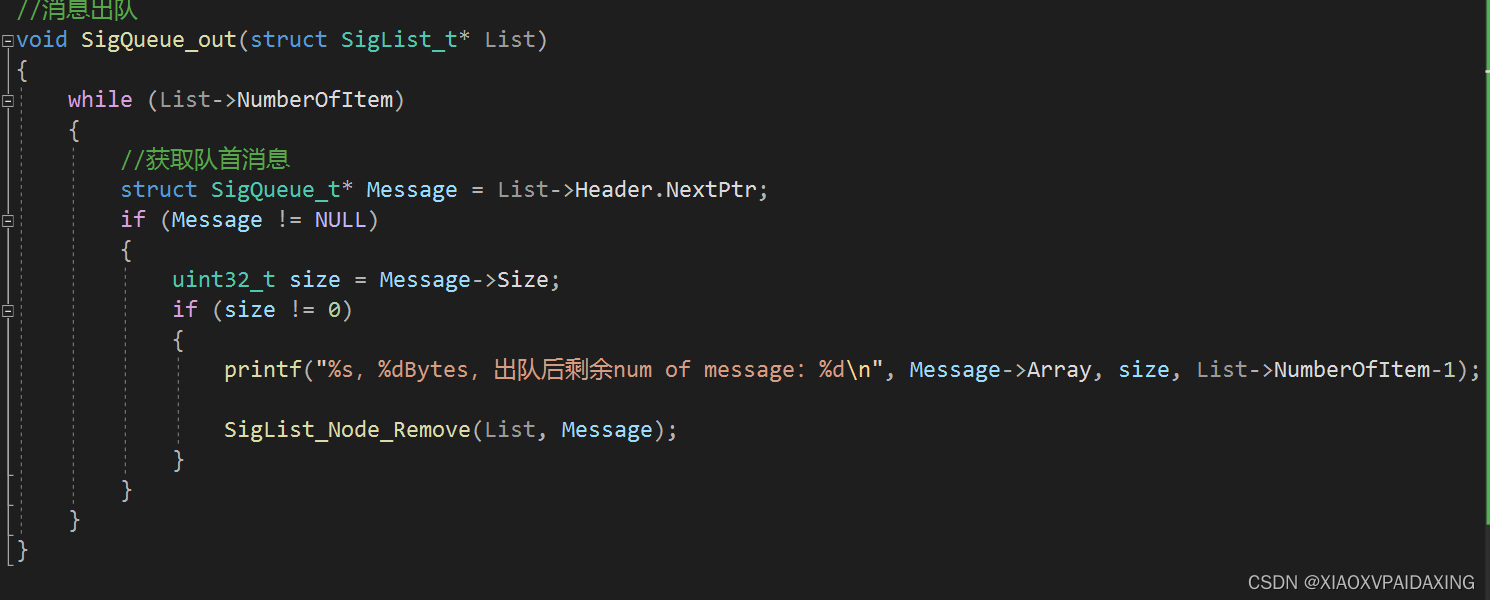
最后在main函数中编写测试程序,来看看程序运行效果:如下图所示
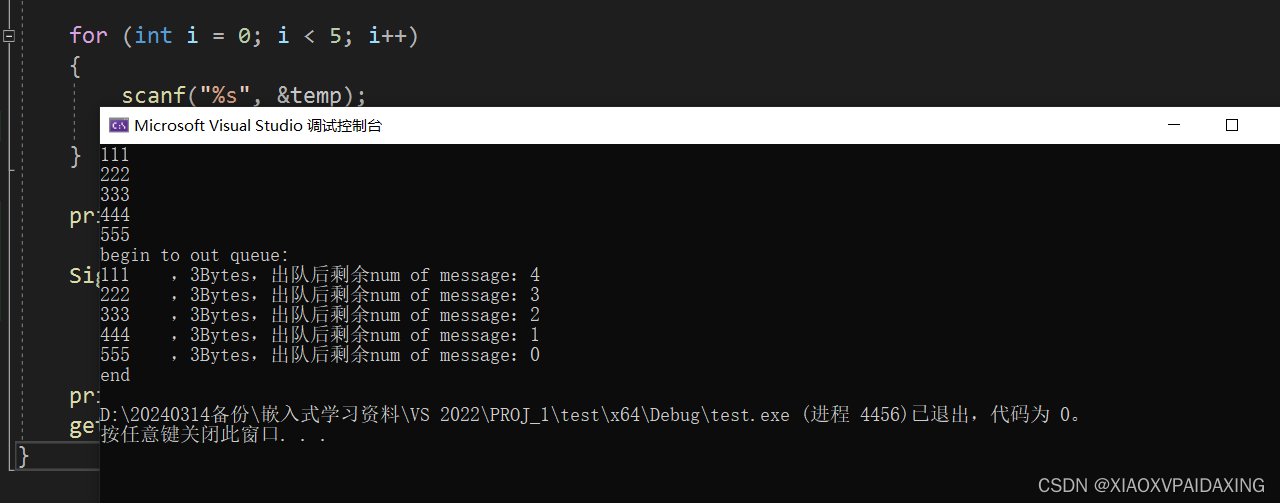
可见,先入队的先出队,后入队的后出队,所以也能成功实现队列的基本操作。相比起双向链表,单向链表的速度可能慢一些,尤其在消息数目很多的时候,因为只有一个单向指针,找到队尾位置不容易。另外增删查改功能上也是双向链表实现起来更加方便,而付出仅仅是多增加一个指针而已,这也是我更加偏向双向链表的原因。















 1743
1743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









