









今天分享的论文是《Graph Matching Networks for Learning the Similarity of Graph Structured Objects》
原文链接:[1904.12787v2] Graph Matching Networks for Learning the Similarity of Graph Structured Objects
开放源代码:https://github.com/Lin-Yijie/Graph-Matching-Networks
这篇论文主要是关于图神经网络的,但是在其中的一个漏洞场景是漏洞挖掘(二进制相似性匹配)。
本文解决了图结构对象的检索和匹配这一具有挑战性的问题,并做出了两个主要贡献。首先,展示了图形神经网络(GNN)是如何被训练成在向量空间中产生图形嵌入,从而实现有效的相似性推理的,该图形神经网络已经成为在结构化数据上定义的各种监督预测问题的有效模型。第二,提出了一种新的图匹配网络模型,给定一对图作为输入,通过一种新的基于跨图注意力的匹配机制对这对图进行联合推理来计算它们之间的相似性得分。展示了模型在不同领域的有效性,包括基于控制流图的函数相似性搜索的挑战性问题,该问题在软件系统漏洞检测中起着重要作用。实验分析表明,模型不仅能够在相似性学习的背景下利用结构,而且它们还能够优于针对这些问题精心手工设计的特定领域基线系统。
在三个任务上评估了所提出的模型和基线:一个仅捕获结构相似性的合成图编辑远程学习任务,以及两个真实世界的任务
本文的主要贡献:
(1)展示了图神经网络(GNNs)如何能够用于生成用于相似性学习的图嵌入;
(2)提出了新的图匹配网络,该网络通过基于跨图注意力机制的匹配来计算相似性;
(3)通过实验证明,所提出的图相似性学习模型在一系列应用中都取得了良好的性能,优于不考虑结构信息的模型以及已有的手工设计的基线模型。
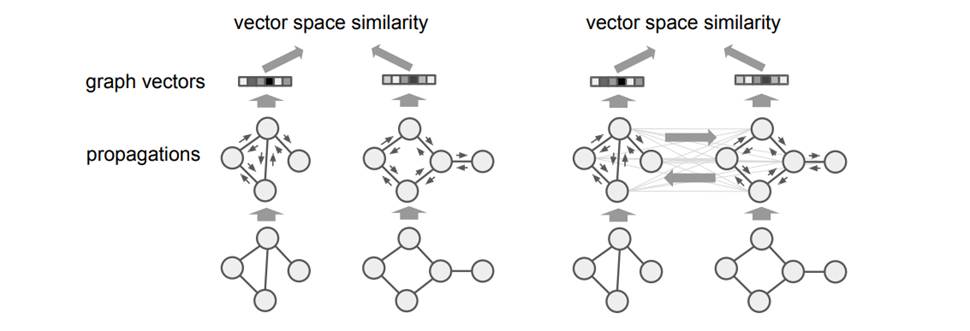
图形嵌入(左)和匹配模型(右)的图示:
问题背景二元函数相似性搜索是计算机安全中的一个重要问题。当无法访问源代码时,例如在处理商业或嵌入式软件或可疑的可执行文件时,就需要分析和搜索二进制文件。将反汇编器和代码分析器结合起来,可以提取出一个控制流图(CFG ),它以结构化的格式包含了一个二元函数中的所有信息。见图1 和附录B.2 举几个CFG的例子。在CFG中,每个节点是汇编指令的基本块,节点之间的边代表控制流,例如由分支、循环或函数调用中使用的跳转或返回指令来指示。在这一节中,针对漏洞搜索问题,其中一段已知有一些漏洞的二进制文件被用作查询,在库中搜索以找到可能有相同漏洞的相似二进制文件。2 对类似漏洞的准确识别使安全工程师能够快速缩小搜索范围并应用补丁。
过去,二元函数相似性搜索问题已经用经典的图论匹配算法(Eschweiler et al.,2016;Pewny et al.,2015),以及Xu et al. (2017)和Feng et al. (2016)提出学习CFG的嵌入并在嵌入空间中进行相似性搜索。Xu et al. (2017)特别提出了一种基于图形神经网络的嵌入方法,从每个节点的一些手动选择的特征向量开始。在这里,进一步研究图嵌入和匹配模型的性能,使用对和三元组训练、不同数量的传播步骤以及从汇编指令中学习节点特征。
训练设置和基线在通过使用不同的编译器gcc和clang以及不同的编译器优化级别来编译流行的开源视频处理软件ffmpeg所生成的数据上训练和评估模型,这导致了7940个函数和每个函数大约8个CFG。CFG的平均大小是每个图大约55个节点,一些更大的图有几千个节点(参见附录B.2 更详细的统计数据)。不同的编译器优化级别会导致相同函数的CFG大小非常不同。拆分数据,使用80%的函数和相关的CFG用于培训,10%用于验证,10%用于测试。模型被训练以学习CFG的相似性度量,使得相同功能的CFG具有高相似性,否则具有低相似性。一旦经过训练,这种相似性度量可以用于搜索二进制文件库,并且对于编译器类型和优化级别是不变的。
比较了图嵌入和匹配模型
借助谷歌的开源功能相似性搜索工具
(Dullien,2018),过去曾被用来成功地发现二进制文件中的漏洞。该工具通过手工设计的图散列过程来计算CFG的表示,该过程通过散列来自3跳邻域的遍历的度序列来编码每个节点的邻域结构,并且还通过散列汇编指令类型的三元组来编码每个基本块的汇编指令。这些特征然后通过使用SimHash样式(Charikar,2002)算法,以形成128维二进制码。然后,基于LSH的搜索索引被用于使用汉明距离来执行近似最近邻搜索。
跟随(Dullien,2018),还将CFG映射到128维二进制向量,并使用第节中描述的汉明相似性公式3 为了训练。进一步研究了数据的两种变体,一种仅使用图结构,另一种使用图结构和具有学习节点特征的汇编指令。当汇编指令可用时,将每个指令类型嵌入到一个向量中,然后将一个基本块中指令的所有嵌入向量相加,作为每个节点的初始表示向量(xi ),这些嵌入与模型的其余部分一起学习。
结果图4显示了具有不同传播步骤数和不同数据设置的不同模型的性能。再次评估了这些模型在来自测试集的固定组对和三联体上对AUC和三联体准确性的性能。结果表明:(1)图嵌入和匹配模型的性能随着传播步骤的增加而不断提高,特别是明显优于使用0传播步骤的结构不可知模型特例操作步骤;(2)图嵌入模型始终优于具有足够传播步骤的基线;以及(3)在所有设置和传播步骤中,图匹配模型优于嵌入模型。此外,已经尝试了仅使用图结构的WL核,并且它实现了0.619 AUC和24.5%的三元组准确性。这并不奇怪,因为WL核不是为解决这一任务而设计的,而模型学习对感兴趣的任务有用的特征,并且可以获得比一般相似性度量更好的性能。
总结与讨论:
本文研究了利用图形神经网络进行图形相似性学习的问题。与图的标准预测问题相比,相似性学习提出了一系列独特的挑战和潜在的好处。例如,当在数据集中确实有一组类时,可以通过分类设置来学习图嵌入模型,但是将其公式化为相似性学习问题可以处理有非常大量的类而每个类只有非常少的示例的情况。从相似性学习设置中学习到的表示也可以很容易地推广到来自训练期间看不到的类的数据(零镜头推广)。
提出了新的图匹配网络作为图嵌入模型的一个更强的替代方案。图匹配模型的额外能力来自于这样一个事实,即它们不是独立地将每个图映射到一个嵌入,而是除了嵌入计算之外,在图对的所有级别上进行比较。该模型然后可以学习向嵌入部分或匹配部分适当地分配容量。为这种表现性付出的代价是在两个方面增加了计算成本:(1)因为每个跨图匹配步骤要求计算全部注意力矩阵,这至少需要O(V1·V2)时间,这对于大图可能是昂贵的;(2)匹配模型成对操作,以及不能直接用于索引和搜索大型图形数据库。因此,当(1)只关心单个对之间的相似性,或(2)在检索设置中使用图匹配网络以及更快的过滤模型(如图嵌入模型或标准图相似性搜索方法)时,最好使用图匹配网络,以将搜索缩小到更小的候选集,然后使用更昂贵的匹配模型对候选集重新排序以提高精度。
开发用于图形相似性学习的神经模型是一个重要的研究方向,有许多应用。仍然有许多有趣的挑战需要解决,例如提高匹配模型的效率,研究不同的匹配架构,使GNN容量适应不同大小的图,以及将这些模型应用于新的应用领域。希望工作能推动这一方向的进一步研究。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









