









今天分享的论文是《DFEPT: Data Flow Embedding for Enhancing Pre-Trained Model Based Vulnerability Detection》
开源代码:https://github.com/GCVulnerability/DFEPT
这是一篇应用图嵌入和预训练模型进行漏洞挖掘的论文。
软件漏洞是计算系统面临的最紧迫威胁之一。识别源代码中的漏洞对于保护用户隐私和减少经济损失至关重要。传统的静态分析工具依赖具备安全知识的专家手动构建操作规则,这一过程需要大量的时间和人力成本,并且在适应新漏洞方面也面临挑战。预训练代码语言模型的出现为自动化漏洞检测提供了新的解决方案。然而,代码预训练模型通常基于标记级的大规模预训练,这阻碍了它们有效捕捉代码段之间的结构和依赖关系。在软件漏洞的背景下,某些类型的漏洞与代码内部的依赖关系相关。因此,识别和分析这些漏洞样本对预训练模型来说是一个重大挑战。
在本文中,提出了一种数据流嵌入技术,以提高预训练模型在漏洞检测任务中的性能,名为DFEPT(Data Flow Embedding for Enhancing Pre-Trained Model Based Vulnerability Detection),它为预训练模型提供有效的漏洞数据流信息。具体来说,从函数级源代码解析数据流图(DFG),并使用变量的数据类型作为DFG的节点特征。通过应用图学习技术,嵌入数据流图,并使用正弦位置编码将相对位置信息纳入图嵌入中,以确保漏洞数据流信息的完整性。研究表明,DFEPT可以为预训练模型提供有效的漏洞语义信息,在Devign数据集上达到64.97%的准确率,在Reveal数据集上达到47.9%的F1分数。与仅进行微调的预训练模型相比,性能提升了1.96%-17.26%。
目前,基于深度学习的漏洞检测工具主要分为两类:
1. 基于图的模型:这些方法试图利用静态分析来揭示源代码中不同类型的依赖关系,包括抽象语法树(AST)、控制流图(CFG)、数据流图(DFG)和程序依赖图(PDG)。这些技术采用图学习来整合从源代码中获得的结构和语义信息进行检测。例如,Devign[47]使用编程语言(PL)解析器提取多方面的图信息进行分类。DeepWukong[5]首先通过考虑控制流和数据依赖生成程序依赖图,然后从系统API调用或操作符中提取子图,称为XFGs,最后输入XFG来训练切片级漏洞检测模型。
2. 基于序列的模型:这些方法将源代码视为类似于自然语言的序列,采用流行的自然语言处理技术来识别漏洞[24]。预训练和微调技术的出现已成为一种流行的学习范式[8]。受BERT[8]等模型的启发,研究人员相继提出了CodeBERT[11]、GraphCodeBERT[16]、UniXcoder[15]和LineVul[12]等预训练模型。这些模型在漏洞检测任务中相继表现出良好的性能[31]。
然而,在实际应用中,上述方法通常存在一些局限性:
1. 在嵌入过程中,图的节点特征通常是切片级代码段。不幸的是,与漏洞无关的文本或标记信息,如变量名和函数名,也被嵌入,引入了额外的噪声和干扰[30]。
2. 代码结构图中节点的相对位置对漏洞的出现至关重要。相同的代码段在不同的上下文中可能会被标记为不同的安全状态[26]。然而,图学习忽略了节点的相对位置。
3. 在检测漏洞时,这些模型难以理解代码中漏洞的语义[30, 40]。虽然预训练模型可以适应特定任务,但仅专注于文本分析会妨碍它们掌握代码的内在结构,如数据流和控制流。
本文的主要贡献如下:
1. 方法:提出了一种数据流嵌入技术,该技术使用变量的数据类型来识别数据流,并应用图学习和正弦位置编码来生成关于漏洞的有效语义信息和相对位置信息。这使预训练模型能够捕捉漏洞中的语义和数据流模式。
2. 研究:使用两个数据集和四个预训练模型评估DFEPT的有效性,并与七种基线策略进行基准测试。此外,进行了消融研究,以确认DFEPT每个组件的重要作用。研究结果表明,与仅微调的预训练模型相比,DFEPT的见解提高了模型识别漏洞的能力,性能提升范围为1.96%至17.23%。DFEPT的每个组件都提供了有价值的信息。
3. 开放科学:将DFEPT与常见的预训练模型相结合,创建了高性能、高效的漏洞检测模型。通过与CodeT5[41]相结合,超越了最先进的漏洞检测性能。DFEPT的源代码是公开的 。
方法流程:
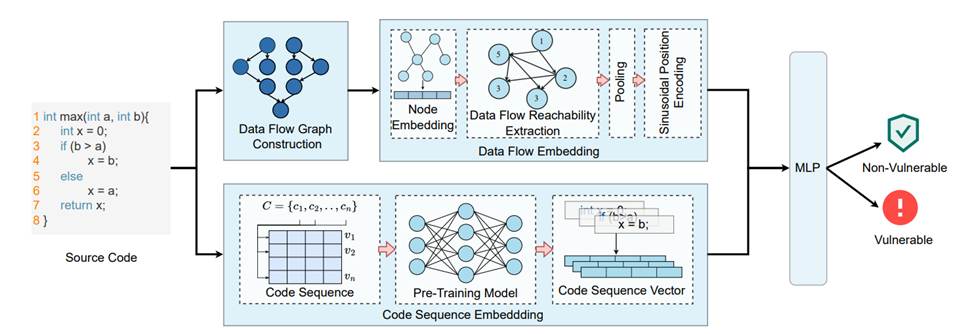
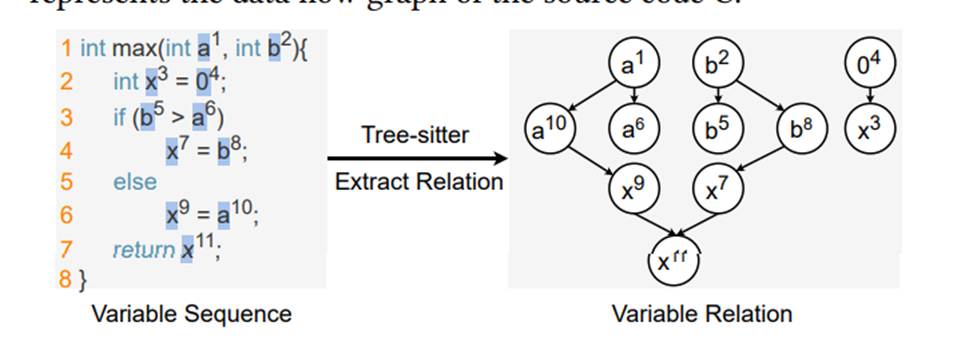
数据流图建立过程:
在实验评估中,将DFEPT与七种最先进的方法进行比较。
- CodeBERT:一种双模态预训练模型,专为自然语言和编程语言的精细处理而设计。它擅长构建通用表示,适用于自然语言和编程领域的广泛任务,包括代码理解、克隆识别等。
- GraphCodeBERT:在CodeBERT的基础上进行扩展,通过编码技术将代码的数据流信息整合到Transformer架构中。经过这样的预训练,它在CodeBERT设定的基线基础上有所改进。
- CodeT5:基于T5架构构建,是一个编码器 - 解码器模型。它引入了一种创新的标识符感知预训练任务,使模型能够区分和恢复模糊的标识符,从而增强其对代码的理解和处理能力。此外,它还提出了双模态代码生成任务,实现了自然语言和编程语言之间更好的对齐。
- UniXcoder:扩展了类似CodeBERT等模型的功能,整合了对代码语法和语义的全面理解。这种增强提升了模型在下游任务中的性能,如代码摘要、翻译和补全。
- ReGVD:提出了两种新颖的技术,用于将源代码构建为图结构,并利用GraphCodeBERT的嵌入层进行图分类。
- VulBERTa:一种专门用于漏洞检测的预训练模型,基于RoBERTa架构。适用于多类漏洞检测任务。
- CSGVD:提出使用预训练模型和双向长短期记忆网络(BiLSTM)对控制流图进行双重嵌入。此外,它引入了双仿射池化层,并使用图卷积神经网络对源代码进行分类。
确立了以下三个研究问题(RQs)进行评估。
- RQ1:DFEPT能否提高预训练模型的性能?在RQ1中,验证DFEPT是否可以与大多数代码预训练模型相结合,以提高漏洞检测的性能。将DFEPT与四种流行的代码预训练模型相结合,使用它们的嵌入层进行节点嵌入,并使用GCN进行数据流嵌入。在4.1节提到的两个数据集上对原始预训练模型和结合DFEPT的模型进行微调。然后将这些模型应用于漏洞检测任务。报告每个模型的性能指标和性能提升比例。
- RQ2:DFEPT能否超越现有的漏洞检测方法?在RQ2中,验证DFEPT是否能够有效地检测漏洞。对于将源代码解析为AST表示,使用开源工具tree-sitter。然后,从AST中提取数据流,并使用GCN进行嵌入,从而促进对代码结构和语义的更深入分析和理解。报告DFEPT取得的最佳性能,并与其他七种基线方法进行比较。
- RQ3:不同的图嵌入或池化方法如何影响模型性能?在RQ3中,研究不同的数据流嵌入方法对DFEPT性能的影响。在本研究中,使用UniXcoder作为基础模型。在节点特征聚合阶段,同时使用GCN和GGNN进行图嵌入。在池化阶段,应用四种池化方法:最大池化、平均池化、求和池化和联合池化,每种方法都与GCN和GGNN结合使用。比较不同嵌入方法对漏洞检测的影响,并报告性能指标。
RQ1回答:DFEPT可以与大多数预训练模型相结合,稳定提高漏洞检测的准确率和稳健性。提升程度受预训练模型本身和嵌入层的影响。
RQ2回答:DFEPT优于所有基线方法。它有效地为预训练模型提供语义信息,在各种实验条件下的漏洞检测任务中都实现了更高的性能。
RQ3回答:无论使用哪种数据流嵌入组合,都可以为预训练模型提供有效的数据流信息。当DFEPT使用GCN结合联合池化进行数据流嵌入时,漏洞检测模型达到了最先进的性能。
讨论一下方法有效性面临的威胁
内部有效性:内部有效性的主要威胁来自预训练模型的选择和不同的代码图结构。预训练模型的性能会影响DFEPT的性能,因为DFEPT在嵌入和编码数据流时使用了预训练模型的嵌入层。不同的预训练模型有不同的预训练任务,它们的嵌入层可能更偏向于生成任务而非分类任务。
DFEPT仅使用单个数据流图作为输入,这可能会限制其性能。抽象语法树、控制流图和程序依赖图在代码分析中也起着极其重要的作用,并且可能包含数据流图没有的结构信息。此外,DFEPT无效的一个可能原因是数据流分析无法识别所有类型的漏洞,因为有些漏洞不是由代码数据流产生的,如认证不足(CWE - 287)。
外部有效性:主要在Devign[47]和Reveal[4]数据集上评估DFEPT,因为所有基线模型都支持这些数据集。这些数据集来自用C语言编写的开源项目。需要注意的是,当将漏洞检测扩展到其他编程语言开发的项目时,语法和关键字的潜在差异可能会引入额外的噪声,影响检测过程。此外,在实际的漏洞检测场景中,经常面临数据极度不平衡的情况,其特点是漏洞样本比例小且漏洞类型多样。这种不平衡可能会使DFEPT无法提取足够有代表性的数据流特征,从而无法获得有效的结构信息。
做一个总结:
提出了DFEPT,这是一种高效的数据流嵌入技术,旨在增强基于预训练模型的漏洞检测能力。数据流嵌入从结构信息和位置信息两个核心方面入手,旨在揭示潜在的漏洞形成模式和特征。使用数据类型来识别同一代码段内不同的数据流,每个数据流都有可能捕捉到漏洞的成因。DFEPT将图嵌入和正弦位置编码与Transformer架构的预训练模型相结合用于漏洞检测,并且适用于大多数预训练模型。实验结果表明,DFEPT非常有效,提高了所有预训练模型的漏洞检测性能,并且优于所有基线方法。还研究了不同图嵌入方法对DFEPT的影响,发现所有嵌入方法都提高了预训练模型的漏洞检测性能。在未来,计划将DFEPT扩展到抽象语法树、控制流图和程序依赖图,探索能够提供更有效信息的图嵌入方法。还打算探索可解释性工具的应用,以精确确定漏洞出现的代码行,并评估技术在不同编程语言中的有效性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









