







今天分享的论文是《Inductive Representation Learning on Large Graphs》
读这篇文章也是因为看了别的文章里面提到了,看得一头雾水。
大型图中节点的低维嵌入已被证明在各种预测任务中非常有用,从内容推 荐到识别蛋白质功能。然而,大多数现有的方法要求在嵌入的训练期间图 中的所有节点都存在;这些先前的方法本质上是直推式的,不能自然地推 广到看不见的节点。在这里,提出了 GraphSAGE,这是一个通用的归 纳框架,它利用节点特征信息(例如,文本属性)来有效地为以前未见过的 数据生成节点嵌入。不是为每个节点训练单独的嵌入,而是学习一个 通过从节点的局部邻域采样和聚集特征来生成嵌入的函数。算法在 三个归纳节点分类基准上优于强基线:基于引文和 Reddit 帖子数据对 进化信息图中的不可见节点进行分类,并且使用蛋白质-蛋白质相互作用的多图数据集表明算法推广到完全不可见的图。
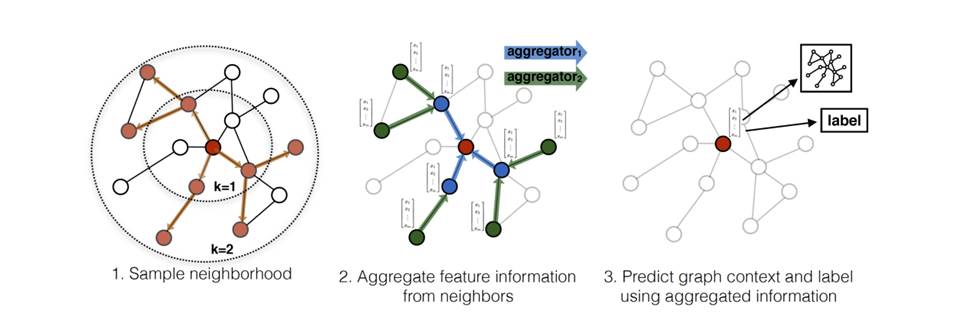
GraphSAGE 示例和聚合方法的可视化说明:
GraphSAGE 嵌入生成(即正向传播)算法:

做个总结:
引入了一种新的方法,允许为看不见的节点有效地生成嵌入。GraphSAGE 始终优于最先 进的基线,通过采样节点邻域有效地权衡了性能和运行时间,并且理论分析提供了方法如何学习局部图结构的洞察力。许多扩展和潜在的改进都是可能的,比如扩展 GraphSAGE 以包含有向图或多模态图。未来工作的一个特别有趣的方向是探索非均匀邻域采 样函数,甚至可能学习这些函数作为 GraphSAGE 优化的一部分。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









