







今天分享的论文是《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》
原文链接:[2005.11401v4] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
开放源代码:https://github.com/huggingface/transformers/blob/master/examples/rag/
模型:https://huggingface.co/rag/
为了学习RAG开始看的这篇论文!加油加油!我要发顶会!
大型预训练语言模型已被证明能在其参数中存储事实性知识,并且在针对下游自然语言处理任务进行微调时可取得最先进的成果。然而,它们获取和精确处理知识的能力仍然有限。因此,在知识密集型任务上,其表现落后于特定任务架构。此外,为其决策提供出处以及更新其世界知识仍是有待研究的问题。目前,具有可微访问机制以访问显式非参数内存的预训练模型仅在抽取式下游任务中得到研究。探索了一种通用的微调方法,用于检索增强生成(RAG)模型——该模型将预训练的参数化和非参数化内存相结合以进行语言生成。引入了RAG模型,其中参数化内存是一个预训练的序列到序列模型,而非参数化内存是维基百科的密集向量索引,可通过预训练的神经检索器进行访问。比较了两种RAG模型形式,一种在整个生成序列中依赖相同的检索段落,另一种则可以为每个词元使用不同的段落。在广泛的知识密集型自然语言处理任务上对模型进行微调并评估,在三个开放域问答任务上取得了最先进的成果,优于参数化序列到序列模型和特定任务的检索提取架构。对于语言生成任务,发现RAG模型比最先进的仅参数化序列到序列基线模型生成的语言更具体、更多样且更符合事实。
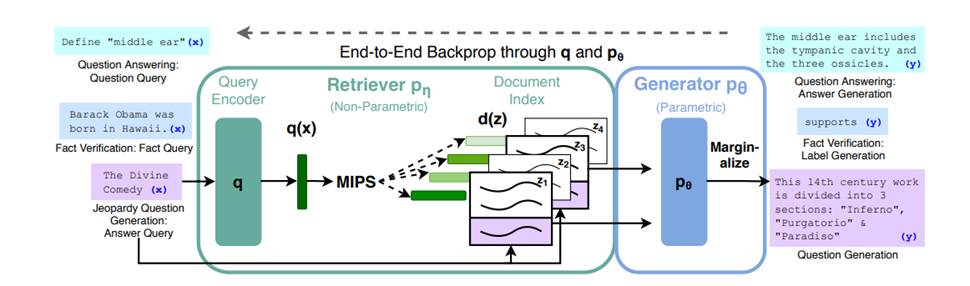
方法概述。将预训练的检索器(查询编码器 + 文档索引)与预训练的seq2seq模型(生成器)相结合,并进行端到端的微调。对于查询x,使用最大内积搜索(MIPS)找到前K个文档\(z_{i}\) 。对于最终预测y,将z视为潜在变量,并对给定不同文档的seq2seq预测进行边缘化:
一些相关工作
- 单任务检索:先前的研究表明,在单独考虑时,检索可以提高各种自然语言处理任务的性能。这些任务包括开放域问答、事实验证、事实补全、长文本问答、维基百科文章生成、对话、翻译和语言建模。工作统一了先前将检索融入单个任务的成功经验,表明单一的基于检索的架构能够在多个任务中取得优异性能。
- 自然语言处理通用架构:先前关于自然语言处理任务通用架构的研究在不使用检索的情况下取得了巨大成功。单个预训练语言模型在经过微调后,已被证明能在GLUE基准测试中的各种分类任务中取得优异性能。GPT-2随后表明,单个从左到右的预训练语言模型可以在判别式和生成式任务中都取得良好性能。为了进一步提升性能,BART和T5提出了单个预训练的编码器 - 解码器模型,利用双向注意力机制在判别式和生成式任务中实现更强的性能。工作旨在通过学习一个检索模块来增强预训练的生成式语言模型,从而扩展单个统一架构能够处理的任务范围。
- 学习检索:在信息检索领域,有大量关于学习检索文档的工作,最近出现了类似的使用预训练神经语言模型的研究。一些工作通过搜索、强化学习或像本文一样的潜在变量方法,优化检索模块以辅助特定的下游任务,如问答任务。这些成功案例利用不同的基于检索的架构和优化技术在单个任务中取得了优异性能,而本文展示了单个基于检索的架构可以通过微调在多种任务中取得良好性能。
基于内存的架构
本文的文档索引可被视为神经网络的大型外部内存,类似于记忆网络[64, 55]。同期研究[14]尝试学习为输入中的每个实体检索训练好的嵌入,而不是像这样检索原始文本。其他研究则通过关注事实嵌入来提升对话模型生成事实性文本的能力[15, 13]。本文内存的一个关键特性在于它由原始文本构成,而非分布式表示,这使得内存具备两个优势:其一,人类可读,为模型赋予了一定的可解释性;其二,人类可写,能够通过编辑文档索引动态更新模型的内存。这种方法也应用于知识密集型对话中,在这些对话中,生成器直接基于检索到的文本进行条件生成,尽管这些文本是通过TF-IDF获取的,而非端到端学习的检索方式[9]。
检索与编辑方法
本文的方法与检索 - 编辑风格的方法有一些相似之处,后者针对给定输入检索相似的训练输入 - 输出对,然后对其进行编辑以提供最终输出。这些方法在包括机器翻译[18, 22]和语义解析[21]在内的多个领域都取得了成功。不过,方法也有一些不同之处,相对较少强调对检索到的内容进行轻微编辑,而是侧重于聚合多个检索到的内容,同时还包括学习潜在检索,以及检索证据文档而非相关的训练对。尽管如此,RAG技术在这些场景中可能也会表现出色,有望成为未来有前景的研究方向。
讨论与总结
在这项工作中,提出了可访问参数化和非参数化内存的混合生成模型。RAG模型在开放域问答任务中取得了最先进的成果。发现人们更倾向于RAG生成的内容,而非纯粹基于参数化的BART生成的内容,认为RAG生成的内容更符合事实且更具体。对学习到的检索组件进行了深入研究,验证了其有效性,并展示了如何通过热交换检索索引来更新模型,而无需进行任何重新训练。在未来的工作中,研究这两个组件是否可以从头开始联合预训练可能会很有价值,可以采用类似于BART的去噪目标或其他目标。工作为参数化和非参数化内存如何相互作用以及如何最有效地结合它们开辟了新的研究方向,有望应用于广泛的自然语言处理任务。
更广泛的影响
与先前的工作相比,这项工作具有一些积极的社会意义:它更紧密地基于真实的事实知识(在本文中为维基百科),这使得生成内容时更少产生“幻觉”,更符合事实,并且提供了更多的可控性和可解释性。RAG可应用于多种场景,直接造福社会,例如为其配备医学索引并让其回答相关的开放域问题,或者帮助人们更高效地工作。
但这些优势也伴随着潜在的缺点:维基百科或任何潜在的外部知识源都可能永远无法做到完全准确且毫无偏见。由于RAG可用作语言模型,与GPT-2[50]类似的担忧在这里同样存在,尽管程度可能较轻,包括它可能被用于在新闻或社交媒体上生成攻击性、虚假或误导性内容;用于冒充他人;或用于自动化生成垃圾邮件/网络钓鱼内容[54]。在未来几十年,先进的语言模型还可能导致各种工作的自动化[16]。为了降低这些风险,可以使用人工智能系统来对抗误导性内容和自动化的垃圾邮件/网络钓鱼行为。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









