







 本文介绍了基于自监督学习的微表情特征表达方法,通过双循环自动编码器(TCAE)从无标注人脸视频中提取面部动作单元(AU)特征,解决数据集有限导致的模型过拟合问题。TCAE通过四阶段学习,包括特征解耦、图像重建、AU循环变换和姿态循环变换,实现了AU的高效提取。实验结果显示,TCAE在AU识别任务上表现出与监督方法相当的性能,具有潜在的表情编辑价值。
本文介绍了基于自监督学习的微表情特征表达方法,通过双循环自动编码器(TCAE)从无标注人脸视频中提取面部动作单元(AU)特征,解决数据集有限导致的模型过拟合问题。TCAE通过四阶段学习,包括特征解耦、图像重建、AU循环变换和姿态循环变换,实现了AU的高效提取。实验结果显示,TCAE在AU识别任务上表现出与监督方法相当的性能,具有潜在的表情编辑价值。
编者按:著名心理学家Paul Ekman和研究伙伴W.V.Friesen,通过对脸部肌肉动作与对应表情关系的研究,于1976年创制了“面部运动编码系统”,而利用微表情的“读心术”正是基于这一研究体系。由于该领域有限的数据集和高昂的标注成本,有监督学习的方法往往会导致模型过拟合。本文中,将为大家介绍中科院计算所VIPL组的CVPR2019新作:作者提出了一种基于视频流的自监督特征表达方法,通过利用巧妙的自监督约束信号, 得到提纯的面部动作特征用于微表情识别。
1.研究背景
面部运动编码系统 (FACS,Facial Action Coding System)从人脸解剖学的角度,定义了44个面部动作单元(Action Unit,简称AU)用于描述人脸局部区域的肌肉运动,如图1所示,AU9表示“皱鼻”,AU12表示“嘴角拉伸”。各种动作单元之间可以自由组合,对应不同的表情。如“AU4(降低眉毛)+AU5(上眼睑上升)+AU24(嘴唇相互按压)”这一组合对应“愤怒”这一情绪状态。
面部动作单元能够客观、精确、细粒度地描述人脸表情。然而昂贵的标注代价在很大程度上限制了AU识别问题的研究进展,其原因在于不同的AU分布在人脸的不同区域,表现为不同强度、不同尺度的细微变化。具体来说,为一分钟的人脸视频标注一个AU,需要耗费一名AU标注专家30分钟。目前学术界已发布的AU数据集只包含了有限的采集对象,以及有限的人脸图像(如2017年CMU发布的GFT数据集有96个人,约35,000张人脸图像)。
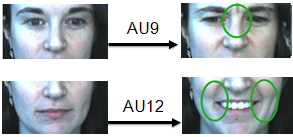
图1. 面部动作单元示例
当前已有的工作多采用人脸区域分块、注意力机制等方法学习人脸局部区域的AU特征,这类方法在训练阶段需要利用精确标注的AU标签,由于目前业界发布的AU数据集人数及图像总量不足,采用监督学习方法训练得到的模型往往呈现出在特定数据集上的过拟合现象,这无疑限制了其实际使用效果。
我们提出了一种能够在不依赖AU标签的前提下,从人脸视频数据中自动学习AU表征的方法(Twin-Cycle Autoencoder,简称TCAE)。TCAE用于后续的AU识别任务时,只需要利用训练数据训练一个分类器即可,显著减少了所需的训练数据,并提升了模型的泛化能力。
2.方法概述
如图2所示,该方法以两帧人脸图像(源图,目标图)之间的运动信息为监督信号,驱使模型提取出用于解码运动信息的图像特征。这个方法的理念在于,模型只有感知并理解了人脸图像中各个面部动作单元的状态(AU是否激活),才能够将源图的面部动作转换为目标图像的面部动作。
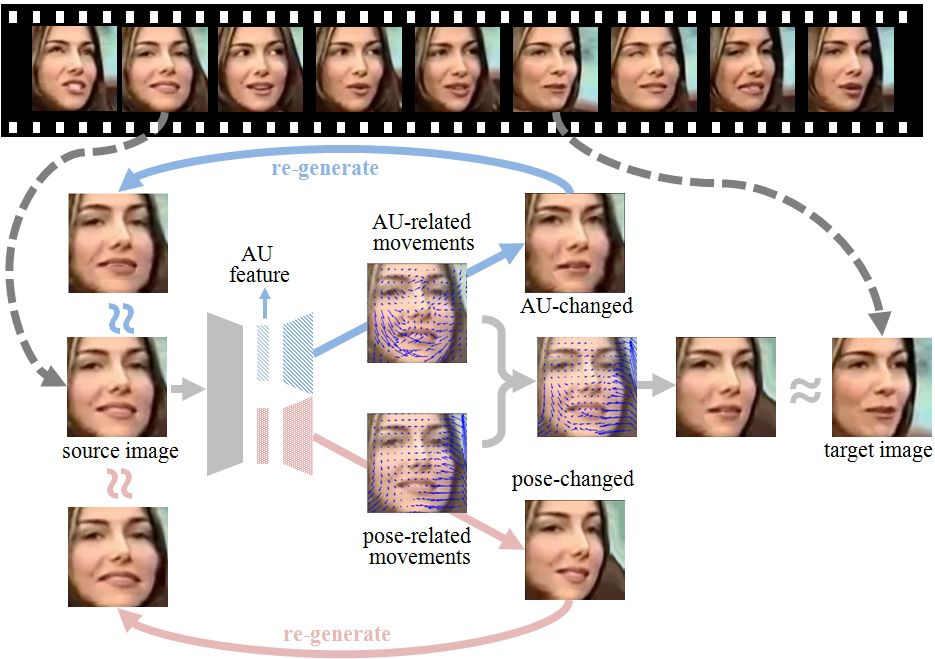
图2. TCAE 设计图
考虑到两帧人脸图像之间的运动信息包含了AU以及头部姿态的运
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









