






SVM 练习的学习笔记
1.线性支撑向量机
1.1 算法方面
在程序编写之前,对于算法的公式一定要都先写成矩阵的形式,确保维度一支,我这里后面直接根据矩阵和向量的维度大小一致而得到的表达式,不知道有啥好的技巧没有。。。。对于svm整个流程来说,应该是1,在训练集中,写出我的目标函数形式,然后对于这个二次规划问题,用quadprog函数,即

写成这个函数目标与约束的形似,注意如果没有那项约束就把它写成[],这样可以得到α,!!!然后注意这里是在训练集练习得到的我的分界面的w和b,所以是将训练集的数据与α代入w的表达式中,由于b的唯一性,因此只要随便找α中0和C之间的数带入b的表达式中,结果应是一致。其次求得w和b后,来看测试集的效果如何,怎么得到的预测的标签值呢通过w’*X+b,大于0说明是正标签,小于0 说明是负标签。这样就得到了预测的测试集的一个结,再与测试集的真实结果对比。
1.2 程序方面
clc;
clear all;
close all;
%% 1、读取heart数据集的文件。分割特征数据和标签数据,分别保存为data和label
heart = load('C:\Users\15745\Desktop\ML data\heart.dat');
data = heart(:,1:end-1);
label = heart(:,end);
label(label ~= 1) = -1;
%% 2、随机取80%的数据为训练集,剩下的20%为测试集。
%%%%%%%%分别保存为data_train, data_test, label_train, label_test
m = size(data,1);
index_data = randperm(m);%%%随机选取索引
len = round(0.8*m);%%四舍五入取整
data_train = data(index_data(1:len),:);%%%训练集
label_train = label(index_data(1:len),:);
data_test = data(index_data(len+1:end),:);%%%测试集
label_test = label(index_data(len+1:end),:);
%% 3、分别编写名为SVM_linear和SVM_gauss的函数。
%%%%%%%输入为data_train, data_test, label_train,C。 输出为svm的预测值和预测标签。
C = 1;
[pre_value,pre_label] = SVM_linear(data_train,data_test,label_train,C);
%% 4、使用ACC和F1_score来评价模型的性能。
ACC = 1/(m-len)*(sum(pre_label == label_test));
F1_score = F1_cal(pre_label,label_test);
%% 3、分别编写名为SVM_linear和SVM_gauss的函数。
%%%%%%%输入为data_train, data_test, label_train,C。 输出为svm的预测值和预测标签。
function [pre_value,pre_label] = SVM_linear(data_train,data_test,label_train,C)
H = diag(label_train)*data_train*data_train'*diag(label_train);
f = -ones(size(data_train,1),1);
Aeq = label_train';
beq = 0;
lb = zeros(length(label_train),1);
ub = C*ones(length(label_train),1);
alpha = quadprog(H,f,[],[],Aeq,beq,lb,ub);
w = data_train'*diag(alpha)*label_train;
index = find(alpha>0 & alpha<C,1);
alpha1 = alpha(index);
b = label_train(index)-(label_train.*alpha)'*data_train*data_train(index,:)';
pre_value = data_test*w+b;
pre_label = sign(pre_value);
% for i = 1:length(data_test)
% if pre_value(i) <= 0
% pre_label(i,1) = -1;
% else
% pre_label(i,1) = 1;
% end
% end
end
function [F1_score] = F1_cal(pre_label,label_test)
TP = sum(pre_label(pre_label == label_test)==1);
P = TP/sum(pre_label ==1);
R = TP/sum(label_test ==1);
F1_score = 2*P*R/(P+R);
end
首先要先将整个流程写出来,这里分为四块,读取数据分割特征数据和标签,分训练集和测试集,编写SVM函数,评价模型性能。在第一部分的时候要注意标签的表示,要将所有标签改成1和-1,第二部分,
对于怎样选取随机是数据,这里用randperm函数产生了一个1-给定数值的随机数列,然后将其置于数据的索引位置。第三部分函数,根据quadprog函数,一定要注意,这里的零,在表示零向量的时候不能直接写成0,要用zeros写成零向量的形式,注意参数是什么形式,有些是矩阵有些是向量,这个上张图片里有,否则结果就会出错。ps:在查找函数的用法时,一定要仔细一点将函数的输入是什么,输出是什么看清楚,否则bug都找不到问题所在。
2.非线性支持向量机
2.1算法理解
非线性与线性的区别主要在于将每个数据通过一个函数映射到了一个空间,这个空间可以做内积,对于核函数,理解为核函数可看做是一个内积,或者说是一种距离的度量。目标函数的具体形式是将线性的x‘·x这个内积改为映射函数的内积,即f(x)’·(x)的内积,将其表示为核函数K,得到目标函数,然后根据其对偶形式,计算w和b,但是注意的是,一搬我们只知道核函数的形式,而对于映射函数f的具体表达是不知道,因此w的具体是算不出来的,!!!巧妙的是,我们算w和b的目的是为了知道测试集的预测值(大于0为正,小于0为负)进而得到预测标签,这里是通过wx+b算得,w的表达式中是αdiag(y)x,wx得到α*diag(y)·(x’*x),将(x’x)替换为核函数的形式,即αdiag(y)*K,这样就可得到预测值了。
2.2程序注意点
function [pre_value,pre_label] = SVM_gauss(data_train,data_test,label_train,C,delta)
K = guass_kernel(data_train,data_train,delta);
H = diag(label_train)*K*diag(label_train);
f = -ones(size(data_train,1),1);
Aeq = label_train';
beq = 0;
lb = zeros(length(label_train),1);
ub = C*ones(length(label_train),1);
alpha = quadprog(H,f,[],[],Aeq,beq,lb,ub);
% w = data_train'*diag(alpha)*label_train;
index = find(alpha>0 & alpha<C,1);
alpha1 = alpha(index);
b = label_train(index)-(label_train.*alpha)'*guass_kernel(data_train,data_train(index,:),delta);
pre_value = guass_kernel(data_test,data_train,delta)*diag(alpha)*label_train;
pre_label = sign(pre_value);
end
function [K] = guass_kernel(X,Y,delta)
K = exp(-pdist2(X,Y,'euclidean').^2/delta^2);
end
程序与线性的区别主要就是两行的区别,一个是对偶函数中对应的H矩阵,一个是w不需要求,但是求预测值的表达式变了,1注意点,写之前想当然的以为就是书上的高斯核函数的形式,其中的分子也就是范数,直接算训练集的欧式距离,但是首先有函数pdist2()是可以算欧式距离的,而不是说直接用x’x,2注意点,看函数帮助的时候要看清楚输入形式,输出形式,在用函数pdist2()时要注意它是用行向量的形式计算,(Ps:看帮助不清楚的时候,将示例程序自己运行一下看结果),因此,两个输入矩阵的列是一样的,而且这个函数输出的是距离的平方,3注意点,写核函数的时候由于要经常用,而且代码长,所以最好是另外写个核函数的function,还有个注意点,这里有矩阵的平方,因此要用点平方,4注意点,算测试预测值时,由于高斯核要分清是哪两个矩阵之间的,这里要将w的原来表达式写清楚*,wx_test=x_testx_traindiag(α)*y_train,应该是测试集与训练集之间的核。
3. 支持向量回归
3.1 模型理解
回归模型与分类类似,主要思想是,让所有点到回归线的距离最小化,允许它有epsinon的损失,希望损失函数:|f(xi)-yi|-epsinon越少越好, 目标函数为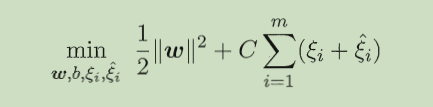
约束条件为:
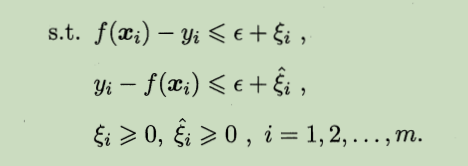
对目标函数的理解:直观上看,要使损失最小应该是min( Σ( |f(xi)-yi| ) ),但是由于绝对值不好求最小,我们找一个|f(xi)-yi|的上界ξi,因此,损失最小相当于上界的和最小即min Σξi,对于|f(xi)-yi|<=ξi,去掉绝对值之后变为f(xi)-yi<=ξi, yi-f(xi)<=ηi,ξi和ηi都大于等于0,因此去掉绝对值之后损失最小变为了min Σ(ξi+ηi),满足f(xi)-yi<=ξi, yi-f(xi)<=ηi约束条件,但是如果一个数据满足f(xi)-yi>0,说明ξi必须要大于0,此时由于yi-f(xi)<0,要使损失最小的话,必须ηi=0,所以ξi与ηi一定有一个为0 ,这样就说明min( Σ( |f(xi)-yi| ) )等价于min Σ(ξi+ηi)。
支持向量回归允许一部分损失,f(x)与y中间的差异大于ε,我们才计算损失,也就是说应该是
f(xi )- yi - ε<= ξi, yi - f(xi) - ε<= ηi,
经过计算得到其对偶问题为:
3.2 程序问题
clc;
clear all;
close all;
%% 1,先预处理数据,将不同列数据的级别大小尽量一致
load('C:\Users\15745\Desktop\ML data\trainX.mat');
load('C:\Users\15745\Desktop\ML data\trainY.mat');
len = size(trainX,1);
stock_data = trainX;
total_value = trainY';
for i = 1:len
stock_data{i,3} = str2double(trainX{i,3});
stock_data{i,4} = str2double(trainX{i,4});
stock_data{i,5} = double(trainX{i,5});
end
stock_data = cell2mat(stock_data);
% stock_data(:,3) = stock_data(:,3).*10;
% stock_data(:,5) = stock_data(:,5)./(10^5);
stock_data = (stock_data- mean(stock_data))./std(stock_data);
total_value = (total_value- mean(total_value))./std(total_value);
%% 2,分训练集和测试集,前80%为训练集,后20%为测试集
len1 = round(0.8*len);
stock_data_train = stock_data(1:len1,:);
total_value_train = total_value(1:len1,:);
stock_data_test = stock_data(len1+1:end,:);
total_value_test = total_value(len1+1:end,:);
%% 3、分别编写名为SVR_linear和SVR_gauss的函数'
C = 1;
epsilon = 0.1;
[pre_value] = SVM_linear(stock_data_train,stock_data_test,total_value_train,C,epsilon);
%% 4、使用误差的一范数来评价模型的性能。
error = sum(abs(pre_value-total_value_test))/(len - len1);
%% 3、分别编写名为SVM_linear和SVM_gauss的函数。
%%%%%%%输入为data_train, data_test, label_train,C。 输出为svm的预测值和预测标签。
function [pre_value] = SVM_linear(data_train,data_test,label_train,C,epsilon)
h = data_train*data_train';
len1 = length(data_train);
H = [h,-h;-h,h];
f = -[-label_train-epsilon*ones(len1,1);label_train-epsilon*ones(len1,1)];
Aeq = [ones(len1,1)',-ones(len1,1)'];
beq = 0;
lb = zeros(2*len1,1);
ub = C*ones(2*len1,1);
alpha = quadprog(H,f,[],[],Aeq,beq,lb,ub);
w = [-data_train',data_train']*alpha;
index = find(alpha>0 & alpha<C,1);
alpha1 = alpha(index);
b = label_train(index)+epsilon-alpha'*[-data_train*data_train(index,:)';data_train*data_train(index,:)'];
pre_value = data_test*w+b;
% pre_label = sign(pre_value);
% for i = 1:length(data_test)
% if pre_value(i) <= 0
% pre_label(i,1) = -1;
% else
% pre_label(i,1) = 1;
% end
% end
end
这里的程序大部分和SVM一致,有两个要注意的地方:
1,由于未知数ε有两个,采用的是分块矩阵的思想,将这两个向量合成一个列向量β,矩阵方程相应得也进行了更改,方程的更改有一个小技巧是,要把矩阵方程写成Aε1+ Bε2,这样方便寻找分块矩阵乘法的形式,变成了[A,B]*[ε1 ; ε2]。
2,由于这次的数据每个特征之间数量级车别太大,因此采用的是将所有数据变成标准正太分布的形式,但是这里不太理解为什么这样变化不会改变数据的可分性。处理方式是(每一列数据 - 平均值)/每一列数据的方差,这样所有数据不管是同一特征值的数据还是不同特征值的数据,数量级别都相同了。
















 2418
2418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









