







单向链表
1.概述
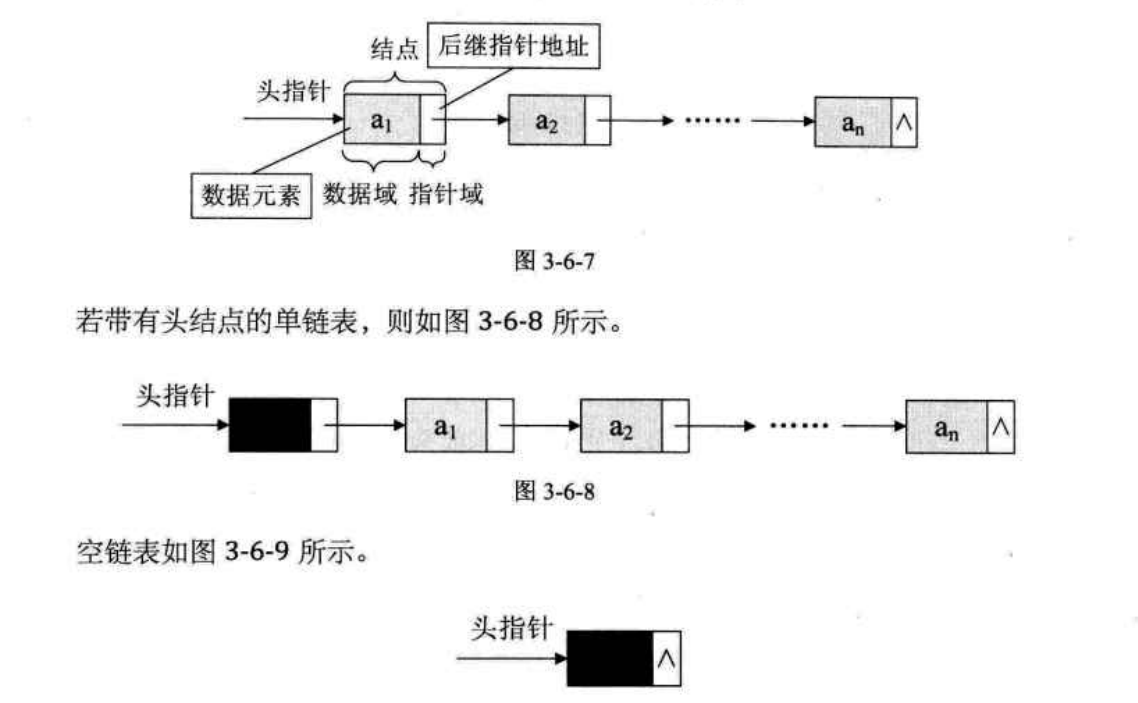
为了表示每个数据元素a与其直接后继数据元素ai+1之间的逻辑关系,对数据元素a来说除了存储其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置)。我们把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域。指针域中存储的信息称做指针或链。这两部分信息组成数据元素ai的存储映像,称为结点(Node)。
2.组成
头指针(哨兵节点):链表指向第一个节点的指针,若有头节点则指向头节点(必要)
头节点:为统一操作方便而设立,放在第一个元素的节点之前,其数据域一般无意义(非必要)
尾节点:线性链表的最后一个节点指针指向为NULL
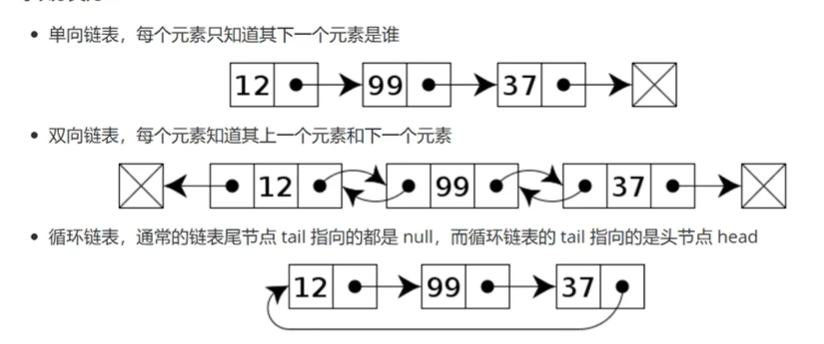
3.分类
4.代码实现
Java实现方式
1)创建初始节点
private Node head = null; //头指针:方便处理端值
private static class Node {
int value; //节点的值
Node next; //指向下一个节点的指针
public Node(int value, Node next) {
this.value = value;
this.next = next;
}
}
2)插入操作
- 头插法
public void addFirst(int value){
/** 分析
* //1.链表为空链表
* head = new Node(value, null);
* //2.链表不为空
* head = new Node(value, head.next);
*/
//合并情况处理
head = new Node(value, head);
}
注意:
head = new Node()也可写成head.next = new Node();
head = new Node(value, head.next) 和 head.next = new Node(value, head.next) 在功能上是相同的,都是用于在链表的头部插入一个新的节点。
区别在于赋值的逻辑,head = new Node(value, head.next) 是将变量 head 直接指向新的节点,将新的节点设置为链表的新头节点。
而 head.next = new Node(value, head.next) 是将原先的头节点的下一个节点指向新的节点,新节点成为链表的新头节点,但是 head 的值保持不变。
所以,两者的结果相同,都能实现在链表头部插入新节点的操作,只是赋值的逻辑略有不同。
- 尾插法
public void addLast(int value){
Node p = head;
//1.如果是空链表,可以直接插入节点
if (p == null) {
addFirst(value);
return;
}
//2.如果不是空链表,先进行遍历,找到末尾
while (p.next != null){
p = p.next;
}
p.next = new Node(value, null);
}
- 任意位置插入
/**
* 根据索引值插入值
* @param index
* @param value
*/
public void insert(int index, int value) {
//对索引第一个位置的节点插入
if (index == 0) {
addFirst(value);
return;
}
Node p = getNode(index - 1);
//检查索引是否合法
if (p == null){ throw new IllegalArgumentException(String.format("索引不合法"));}
//插入操作
p.next = new Node(value, p.next.next);
}
//查找元素
private Node getNode(int index) {
//遍历索引
Node p = head;
for (int i = 0; p != null; p = p.next, i++) {
if (i == index) break;//找到索引前一个位置的节点
}
return p;
}
3)查找元素
private Node getNode(int index) {
//遍历索引
Node p = head;
for (int i = 0; p != null; p = p.next, i++) {
if (i == index) break;//找到索引前一个位置的节点
}
return p;
}
4)遍历链表
//遍历链表
/**
* 循环遍历
* @param consumer
*/
public void loop1(Consumer<Integer> consumer){
Node p = head;//创建一个遍历元素的指针
while (p != null){//当链表不为空的情况下进行遍历
//这里用consumer去接收参数,将获得的元素的使用方法交给用户
consumer.accept(p.value);
p = p.next;
}
}
/**
* 迭代器实现元素的遍历
* @param
*/
@Override
public Iterator<Integer> iterator() {
return new Iterator<Integer>() {
Node p = head;
@Override
public boolean hasNext() {//是否存在下一个元素
return p != null;
}
@Override
public Integer next() {//返回当前值,并指向下一个元素
int v = p.value;
p = p.next;
return v;
}
};
}
//根据索引获取元素的值
public int getElem(int index){
//1.遍历链表,当到index时返回其值
int i = 0;//用于记录遍历的次序
for (Node p = head; p != null; p = p.next, i++){
if (i == index){
return p.value;
}
}
//2.没有找到抛异常
throw new IllegalArgumentException(String.format("索引不合法"));
}
注意:
对于内部类是否加static的经验:如果在调用的方法中,方法内部没有全局变量,则不可以加static,否则可以加。
在Java中,static关键字用于声明静态成员,即与特定对象实例无关的成员。以下是在Java中需要使用static的一些情况:
静态成员变量:当一个成员变量需要在多个对象之间共享,或者希望在没有创建对象实例的情况下访问成员变量时,可将其声明为静态。
class MyClass {
static int count; // 静态成员变量
}
静态方法:当一个方法不需要访问和操作特定对象的状态,即不依赖于对象的实例变量,可将其声明为静态方法。
class MyClass {
static void printHello() { // 静态方法
System.out.println("Hello");
}
}
静态代码块:静态代码块在类加载时执行,并且只执行一次,可用于初始化静态变量或执行其他必要的静态操作。
class MyClass {
static {
// 静态代码块
// 执行一些初始化操作
}
}
静态内部类:当一个内部类不需要访问外部类的实例变量或方法时,可将其声明为静态内部类。
class OuterClass {
static class InnerClass { // 静态内部类
// ...
}
}
需要注意的是,静态成员可以通过类名直接访问,而不需要创建对象实例。但是,静态成员不能直接访问非静态成员,因为非静态成员依赖于对象实例的存在。
5)获取元素
/**
* 获取对于索引中链表的元素
* @param index
* @return
*/
public int getElem(int index){
//1.遍历链表,当到index时返回其值
int i = 0;//用于记录遍历的次序
for (Node p = head; p != null; p = p.next, i++){
if (i == index){
return p.value;
}
}
//2.没有找到抛异常
throw new IllegalArgumentException("索引不合法"));
}
6)删除元素
/**
* 根据索引值删除链表节点的元素
* @param index
*/
public void remove(int index){
//删除第一个元素
if (head == null){ return;}//链表为空则不予进行删除
if (index == 0){ head = head.next;return;}
//遍历链表查找元素
Node prev = getNode(index - 1);
Node removed = prev.next;
//判断索引位置是否合法:即索引是否越界
//1.删除元素刚好为末尾后的的第一个元素
if (prev == null){ throw new IllegalArgumentException("索引不合法");}
//2.删除元素越界且不为为末尾后的的第一个元素
if (removed == null){ throw new IllegalArgumentException("索引不合法");}
//删除元素
prev.next = removed.next;
}
C实现方法
1)创建单向链表:
typedef int ElemType;//方便更改数据类型
/*线性表的单链表存储结构*/
typedef struct Node{
ElemType data;
struct Node *next;
} Node;
typedef struct Node *LinkList;//创建链表LinkList
2)单链表的取值:
Status GetElem(LinkList L, int i, ElemType *e){
int j = 1;
LinkList p;
p = L->next; //让p指向链表第一个节点
while(p && j<i){//p不为空或者j还没有等于i
p = p->next;
++j;
}
if(!p || j>i) return ERROR;//第一个元素不存在
*e = p->data;
return OK;
}
3)单链表插入元素:
Status ListInsert(LinkList *L, int i, ElemType e){
//1.查找新元素
int j = 1;
LinkList p;
p = *L;
//2.先判断是否存在第一个节点
if(!p || j > i) return ERROR;
//3.寻找节点并插入
while(p && j < i){
p = p->next;
j++;
}
//4.创建新节点
LinkList s = (LinkList) malloc(sizeof(Node));
s->data = e;
s->next = p->next;
p->next = s;
return OK;
}
4)单链表删除元素:
Status ListDelete(LinkList *L, int i, ElemType *e){
//1.查找新元素
int j = 1;
LinkList p, q;
p = *L;
//2.先判断是否存在第一个节点
if(!p || j > i || !(p->next)) return ERROR;
//3.查找元素
while(p && j < i){
p = p->next;
j++;
}
q = p->next;
p->next = q->next;
*e = q->data;
//4.让系统回收此节点,释放内存
free(q);
return OK;
}
5)结构体知识回顾:
1.结构体的声明:
struct 结构体名(也就是可选标记名)
{
成员变量;
};//使用分号表示定义结束;
//此时的结构体名相当于int,float,即自定义类型
2.结构体变量名
方法一:
struct 结构体名{
...
}变量名;
方法二:
struct 结构体名 变量名;
方法三:
typedef struct{
}结构体名;
3.结构体初始化
1.可以直接在创建结构体时赋值
struct book s1={//对结构体初始化
"yuwen",//title为字符串
"guojiajiaoyun",//author为字符数组
22.5 //value为flaot型
};
//要对应起来,用逗号分隔开来,与数组初始化一样;
2.如果初始化之后,就不可以直接赋值
book.title = ""
book -> data = 1 //指针赋值
4.malloc()函数和free()函数;
malloc()函数的作用就是动态分配内存;
介绍:
malloc 向系统申请分配指定size个字节的内存空间。返回类型是 void* 类型。void* 表示未确定类型的指针。C,C++规定,void* 类型可以通过类型转换强制转换为任何其它类型的指针;
头文件为;#include<stdlib.h>
总结;
1;malloc只分配内存不初始化值,
2;注意malloc分配内存后,要来个判断是否成功分配;
3;malloc返回的指针需要强制转化;
4;malloc和free是配对使用的;
5;free之后,要将那指针指向NULL;














 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









