






在现实世界的数据处理中,异常值(Outliers)是一个常见的问题。从制造业的质量控制、金融市场交易到电力数据测量,都会出现突如其来的异常观测值,这些数据可能是意料之外的,甚至在统计学上极不可能发生。出现异常值的原因多种多样,比如数据测量或录入时的人为错误、自然波动带来的变化、数据输入失误,或者真实但罕见的事件,如市场崩盘、自然灾害,甚至是突发封锁(lockdown)等情况。
本文将通过实际操作,介绍几种有效的异常值处理策略,这些策略的选择取决于数据集的性质以及项目的具体需求。在介绍三种常见策略之前,我们首先进行数据准备,包括创建和可视化一个包含两个属性的合成数据集。
第一步:导入必要的 Python 库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
第二步:创建合成数据集
在本示例中,我们生成两个维度(属性)上服从正态分布的数据点,并手动添加三个额外的异常值,即 (90,40)、(150,30) 和 (200,50)。
np.random.seed(0)
x = np.random.normal(50, 10, 100)
y = np.random.normal(30, 5, 100)
x = np.append(x, [90, 150, 200]) # 添加 x 方向上的异常值
y = np.append(y, [40, 30, 50]) # 对应的 y 方向值
data = {'Feature1': x, 'Feature2': y}
df = pd.DataFrame(data)
第三步:数据可视化
plt.scatter(df['Feature1'], df['Feature2'], color='blue', label='Original Data')
plt.title('Original Data')
plt.xlabel('Feature1')
plt.ylabel('Feature2')
plt.legend()
plt.show()
输出:
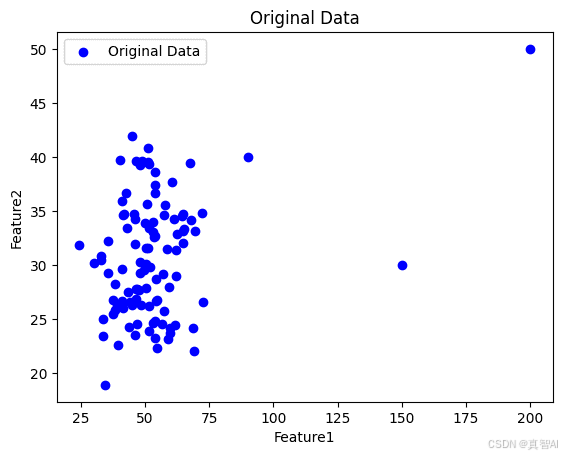
为了更好地说明不同异常值处理策略的效果,我们假设数据集中的 Feature1 和 Feature2 代表的是某种热带花卉的花瓣长度和宽度(单位:毫米),且该物种在花瓣大小上存在显著的变异性。
策略 1:直接删除异常值
最简单且有效的方法之一是直接删除异常值,假设它们是由于错误导致的。
虽然在数据量较小的情况下可以手动删除异常值,但通常更优的做法是使用统计方法来识别和剔除异常值。其中,Z 分数(Z-score)是一种常见的检测方法: [ z = \frac{x - \mu}{\sigma} ] 其中 ( \mu ) 为均值,( \sigma ) 为标准差。如果某个数据点的 Z 分数大于 3(即距离均值超过 3 倍标准差),我们可以认为它是异常值并剔除。
mean_x, mean_y = df['Feature1'].mean(), df['Feature2'].mean()
std_x, std_y = df['Feature1'].std(), df['Feature2'].std()
df['Z-Score1'] = (df['Feature1'] - mean_x) / std_x
df['Z-Score2'] = (df['Feature2'] - mean_y) / std_y
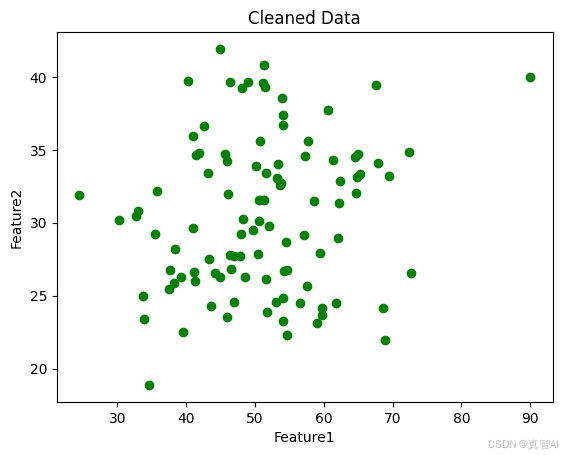
df_cleaned = df[(abs(df['Z-Score1']) <= 3) & (abs(df['Z-Score2']) <= 3)]
可视化清理后的数据
plt.scatter(df_cleaned['Feature1'], df_cleaned['Feature2'], color='green', label='Cleaned Data')
plt.title('Cleaned Data')
plt.xlabel('Feature1')
plt.ylabel('Feature2')
plt.show()
输出:
策略 2:数据变换以减少异常值影响
在某些情况下,异常值可能包含重要信息,或者数据呈现非线性或偏态分布,这时直接删除可能不是最佳方案。此时,可以对数据进行数学变换,使其更加符合正态分布,减少异常值的影响。例如,常见的对数变换(log transformation)可以有效缩小极端值的影响。
df['Log-Feature1'] = np.log1p(df['Feature1'])
df['Log-Feature2'] = np.log1p(df['Feature2'])
plt.scatter(df['Log-Feature1'], df['Log-Feature2'], color='green', label='Transformed Data')
plt.title('Transformed Data')
plt.xlabel('Log-Feature1')
plt.ylabel('Log-Feature2')
plt.legend()
plt.show()
输出:
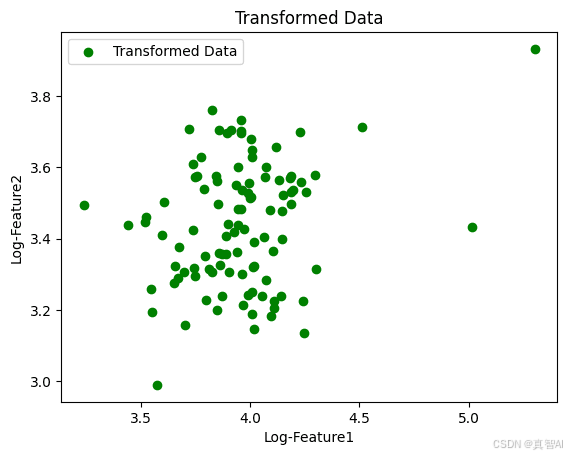
对数变换能够将极端值拉近整体数据分布,使数据更加平滑。在实际应用中,是否采用变换取决于具体问题的需求。例如,在训练机器学习分类器时,我们希望模型在转换前后保持相似的预测性能。
策略 3:截断(Capping)或温莎化(Winsorizing)
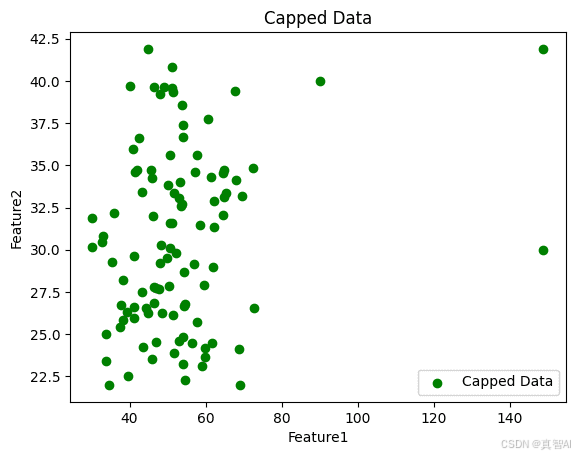
如果不想整体转换数据,可以仅调整最极端的观测值,使其限制在特定范围内。例如,我们可以将数据裁剪至 1%-99% 分位数范围内:
lower_cap1, upper_cap1 = df['Feature1'].quantile(0.01), df['Feature1'].quantile(0.99)
lower_cap2, upper_cap2 = df['Feature2'].quantile(0.01), df['Feature2'].quantile(0.99)
df['Capped-Feature1'] = np.clip(df['Feature1'], lower_cap1, upper_cap1)
df['Capped-Feature2'] = np.clip(df['Feature2'], lower_cap2, upper_cap2)
plt.scatter(df['Capped-Feature1'], df['Capped-Feature2'], color='green', label='Capped Data')
plt.title('Capped Data')
plt.xlabel('Feature1')
plt.ylabel('Feature2')
plt.legend()
plt.show()
输出:
温莎化(Winsorizing)
温莎化与截断类似,但不是直接将极端值替换为界限值,而是用最接近的非异常值替代它们。例如,所有低于 1% 分位数的数据点都会被替换为 1% 分位数的值,而所有高于 99% 分位数的数据点都会被替换为 99% 分位数的值。
截断和温莎化适用于希望保留数据完整性,同时仅调整最极端观测值的情况。它们特别适用于避免数据分布发生重大变化的场景。
总结
在实际数据处理中,异常值的处理方式取决于数据集的具体情况和项目需求:
- 删除异常值(Z-score 方法):适用于异常值明显为错误数据的情况。
- 数据变换(对数变换):适用于数据偏态严重或异常值可能包含重要信息的情况。
- 截断或温莎化(Capping & Winsorizing):适用于保留数据完整性,仅调整极端值的情况。
无论选择哪种方法,都应根据具体业务需求进行评估和调整,以确保数据的可用性和分析的准确性!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









