






绝大多数数据科学工作都发生在事后,分析的是静态数据集,这些数据集反映了已经发生的事情。但现实世界中的数据是连续产生的:点击、交易、传感器更新和评论,这些信息都是实时到达,而不是批量传送。
要处理这样的数据,你需要采用不同的方法。
本指南从数据科学的角度介绍了数据流处理。我们将解释什么是数据流处理、它为何重要,以及如何使用 Apache Kafka、Apache Flink 和 PyFlink 等工具,构建实时数据管道。过程中,我们会通过异常检测和评论主题分析等示例,结合像 GPT-4 这样的基础大模型进行讲解。
如果你希望让自己的工作更贴近数据本身及其驱动的决策,这将是一个实用的起点。
什么是数据流处理?数据科学家为何要关注?
数据流处理(Data Streaming)指的是在数据生成的同时,持续不断地处理数据。与其等待一批数据到来,不如在每个事件(每一次点击、消息或更新)到达时立即处理。
这种转变非常重要,因为如今越来越多的数据都是实时生成的。例如:
-
用户浏览网站,每次点击、滚动或搜索都是一个信号。
-
支付系统及时标记可疑交易。
-
配送车队每秒发送 GPS 与传感器数据。
-
聊天机器人根据用户的实时反馈调整行为。
对于数据科学家来说,这带来了新的机遇:你可以构建能够实时响应的模型,部署即时分析系统,支持依赖于及时、丰富上下文数据的 AI 系统。
流式处理不是批处理的替代品,而是补充。在低延迟、高频率或持续监控至关重要时,应该使用流处理;而对于长期趋势建模或大规模历史训练,批处理依然有效。
不过,流处理可以实现批处理无法做到的事情,主要体现在机器学习工作流的三个高影响领域:
- 在线预测
:无需每隔数小时批量生成推荐或预测,而是在用户操作时即时生成。例如,电商网站可以基于用户当前浏览行为实时计算折扣。
- 实时监控
:无需等待批处理作业标记模型问题,可以直接在实时数据上计算指标,缩短检测和响应时间,尤其适用于新模型上线后的监控。
- 持续学习
:即使不每小时更新模型,实时收集新鲜数据也能缩短反馈周期、测试再训练迭代,并即时评估新模型表现。
流式系统也支持有状态处理(stateful processing),可以避免重复处理相同数据。
无状态处理 vs 有状态处理
举例来说,如果你要计算用户过去 30 分钟的平均购物车价值,系统无需每次都从头开始计算,而是记住上次的进度。这比无状态计算(如 Serverless 函数或临时批处理作业)更快、更省资源、更易扩展。
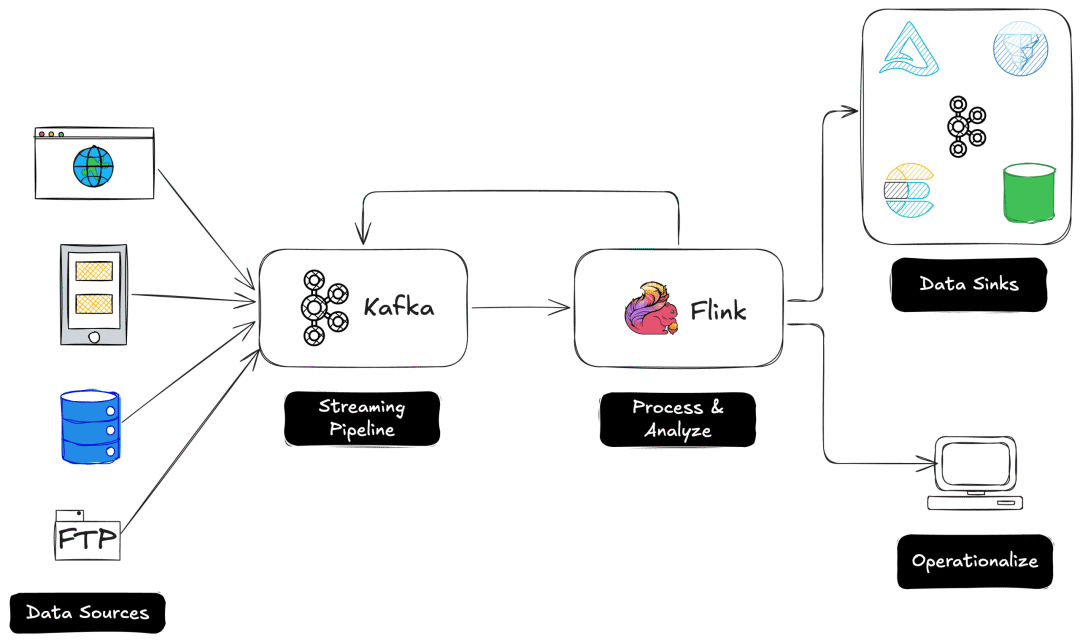
流处理背后的工具:Apache Kafka 与 Apache Flink
两大技术成为实时数据系统的基石:
- Apache Kafka
:分布式事件流平台。支持事件流的发布与订阅,可靠存储并实时处理,是系统间实时数据传输的中枢。
- Apache Flink
:流处理引擎。能处理连续、无限的数据流,支持低层事件处理与高层分析。Flink 可以以低延迟、高吞吐和“精确一次”保证,处理百万级事件。
Kafka 负责数据采集与传输,Flink 负责计算与分析,两者共同构成现代流处理架构的核心。
典型流处理管道
在典型的流处理管道中,Kafka 从上游系统(如网站或 IoT 设备)采集数据,Flink 订阅相关主题进行分析或模型推理,处理后的数据再被推送到新的 Kafka 主题、数据库或仪表盘。
流处理已带来的价值
许多全球领先的数据驱动公司已在实时场景中广泛采用流处理:
- Netflix
:将 Kafka 作为个性化推荐引擎的基础。每次点击、暂停和播放都会进入 Kafka 流,帮助优化推荐内容。
- Pinterest
:依赖 Kafka 和流处理为推荐系统提供动力。用户与内容互动的最新行为会被实时处理,实现秒级的新推荐推送。有状态处理让 Pinterest 能够跨会话、跨行为追踪上下文,而不仅仅是对单一事件做出反应。
这个模式已在各行各业得到应用。
认识 PyFlink:用 Python 做流处理
Flink 功能强大,但其核心实现是 Java 和 Scala。PyFlink 是 Flink 的 Python API,专为数据科学家和 Python 开发者设计,让强大的流处理能力变得易于使用。
PyFlink 提供两大主要 API:
- Table API
:类 SQL 的高级抽象,适合结构化数据的过滤、聚合和流连接。
- DataStream API
:低级、更灵活,适合定制事件处理逻辑或与机器学习模型集成。
这种灵活性对数据科学家尤为重要。例如,可用 Table API 将客户点击流与产品元数据做流式关联,或用 DataStream API 对传感器数据实时进行异常检测。
Flink 适用于 AI 场景,因为它支持大规模数据的低延迟处理和高容错性,适合实时推理、监控和反馈。其“精确一次”保证、动态扩展能力和原生状态管理,让 AI 管道更稳定可靠。
金融、电商、制造、物流等行业,已普遍用 Flink 实现实时决策系统,如反欺诈、推荐引擎、预测性维护和供应链预警。
实时监控或在线预测的示例流程
下面以 DataStream API 实现异常检测为例:
示例:用 PyFlink 和 Kafka 实现实时异常检测
假设我们有一个 Kafka 主题流式传输工厂传感器数据,每条消息包含 device_id、timestamp 和温度读数。需要实时检测温度异常,并将标记事件写入另一个 Kafka 主题以便告警或分析。
以下是一个最小化的 PyFlink 流水线,读取 Kafka 数据、标记异常并写出结果(完整代码见原文链接)。
-
定义异常检测函数:
def detect_anomalies(event_str):
try:
event = clean_and_parse(event_str)
temperature = float(event.get('temperature', 0))
if temperature > 100: # 示例阈值
event['anomaly'] = True
return json.dumps(event)
except Exception:
pass
return None
-
设置流式执行环境:
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1)
env.set_runtime_mode(RuntimeExecutionMode.STREAMING)
-
创建 Kafka 源读取数据:
source = KafkaSource.builder() \
.set_bootstrap_servers(confluent_config.get("bootstrap.servers")) \
.set_topics("sensor_data") \
.set_properties(confluent_config) \
.set_starting_offsets(KafkaOffsetsInitializer.earliest()) \
.set_value_only_deserializer(SimpleStringSchema()) \
.build()
ds = env.from_source(source, WatermarkStrategy.for_monotonous_timestamps(), "Kafka Source")
-
定义 Kafka 数据下游输出:
sink = KafkaSink.builder() \
.set_bootstrap_servers(confluent_config.get("bootstrap.servers")) \
.set_record_serializer(
KafkaRecordSerializationSchema.builder()
.set_topic("sensor_anomalies")
.set_value_serialization_schema(SimpleStringSchema())
.build()
) \
.set_delivery_guarantee(DeliveryGuarantee.AT_LEAST_ONCE) \
.set_property("security.protocol", confluent_config.get("security.protocol")) \
.set_property("sasl.mechanism", confluent_config.get("sasl.mechanism")) \
.set_property("sasl.jaas.config", confluent_config.get("sasl.jaas.config")) \
.build()
-
应用转换并输出异常数据:
anomalies_stream = ds.map(detect_anomalies, output_type=Types.STRING()) \
.filter(lambda x: x is not None)
anomalies_stream.sink_to(sink)
env.execute()
运行原理
该流水线每当有事件到达时就实时处理,检测异常并将其发送到下游。虽然示例简单,但可以换用机器学习模型(如 scikit-learn 的异常检测)、加入状态或对接监控系统,所有这些都基于相同的模式。
下面看一个更复杂的示例:
示例:用 GPT-4 实时分析产品评论主题
大规模、实时了解客户反馈一直是难题。传统评论情感或主题分析依赖批处理:收集评论、清洗、离线建模、生成报告——等到结果出来为时已晚。
但有了流处理基础设施和 GPT-4 等模型,可以在评论到达时立即分析、提取主题、分类,实时驱动仪表盘或预警。
为什么实时主题分析重要?
- 更快反馈
:第一时间发现产品问题或客户痛点
- 更智能个性化
:基于最新反馈调整推荐
- 运营感知
:当“电池寿命”、“配送问题”、“客服”等主题出现高峰时,及时通知相关团队
假设客户评论被推入 Kafka 主题,可用 PyFlink 流水线实时处理,每条评论通过 GPT-4 提取主题,并写入新流或分析库,还可聚合主题及时发现趋势。
步骤一:用 GPT-4 提取主题
首先定义函数,从 Kafka 事件中提取评论主题:
def extract_themes(review_text):
try:
client = OpenAI(api_key=open_ai_key)
chat_completion = client.chat.completions.create(
model="gpt-4",
messages=[
{"role": "user", "content": f"""Identify key themes in this product review: {review_text}
Return a JSON array of themes"""}
]
)
content = chat_completion.choices[0].message.content
logging.info(f"OpenAI API call successful: {content}")
return json.loads(chat_completion.choices[0].message.content)
except Exception as e:
print(f"Error in extract_themes: {e}")
return []
def process_reviews(event_str):
try:
review = clean_and_parse(event_str)
review_text = review.get('review_text', '')
review['themes'] = extract_themes(review_text)
return json.dumps(review)
except Exception:
pass
return None
省略 Kafka 源和目标的设置,只需将 process_reviews 应用于 product_reviews 主题的数据流,并写入 product_reviews_with_themes 主题:
themes_stream = ds.map(process_reviews, output_type=Types.STRING()) \
.filter(lambda x: x is not None)
themes_stream.sink_to(sink)
步骤二:实时分析主题
评论流入 product_reviews_with_themes 主题后,可以聚合统计各主题出现次数,实时追踪热门话题:
themes_source = KafkaSource.builder()...
ds_themes = env.from_source(themes_source, WatermarkStrategy.for_monotonous_timestamps(), "Kafka Themes Source")
# 统计主题
theme_counts = ds_themes.map(clean_and_parse, output_type=Types.MAP(Types.STRING(), Types.OBJECT_ARRAY(Types.BYTE()))) \
.filter(lambda x: x is not None and "themes" in x) \
.flat_map(lambda review: [(theme.lower(), 1) for theme in review["themes"]], output_type=Types.TUPLE([Types.STRING(), Types.INT()])) \
.key_by(lambda x: x[0]) \
.sum(1)
# 输出结果
theme_counts.print()
为什么这很重要?
传统主题分析依赖人工标注、规则 NLP 流水线或像 LDA 这样的事后主题建模。这些方法难以大规模扩展,难以捕捉细微变化,也无法及时响应。
有了 GPT-4 和 PyFlink,可以实时分析主观、非结构化数据,无需等待批处理,也无需从零搭建 NLP 模型。
这带来了更智能的客户反馈循环、实时产品监控和更丰富的分析,全部基于流数据和基础大模型实现。
总结
数据流处理正在改变数据科学的工作方式。对数据科学家来说,这是一次拉近与业务价值创造源头的机会:数据生成的那一刻,也是决策发生的那一刻。
通过构建和使用实时工作的模型和分析,你不再被动等待昨天的数据来解释“发生了什么”,而是在主动塑造“接下来会发生什么”。这将你的工作与客户、运营和收益紧密相连。
随着 Kafka、Flink 及 PyFlink 等工具的普及,以及 GPT-4 等基础大模型的出现,流式数据处理的门槛越来越低。让模型贴近实时数据,也让你的影响更贴近业务本身。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









