






标题:GPT-4o:多模态AI的新里程碑
文章信息摘要:
GPT-4o 是一款多模态全能模型,能够处理文本、音频、图像和视频等多种输入,并生成相应的输出,所有处理均由同一神经网络完成。它在文本推理、语音识别、视觉理解和多语言处理方面表现卓越,特别是在复杂问题和低资源语言任务中取得了显著突破。此外,GPT-4o 的结构化输出功能能够精确匹配开发者提供的 JSON 模式,简化了非结构化数据的处理流程。同时,GPT-4o mini 作为其经济版本,在多个学术基准测试中表现优于 GPT-3.5 Turbo,为资源有限的用户提供了高效且经济的解决方案。这些进步不仅提升了技术性能,也为未来的 AI 应用开辟了更广阔的可能性。
利用GPT提高信息处理效率
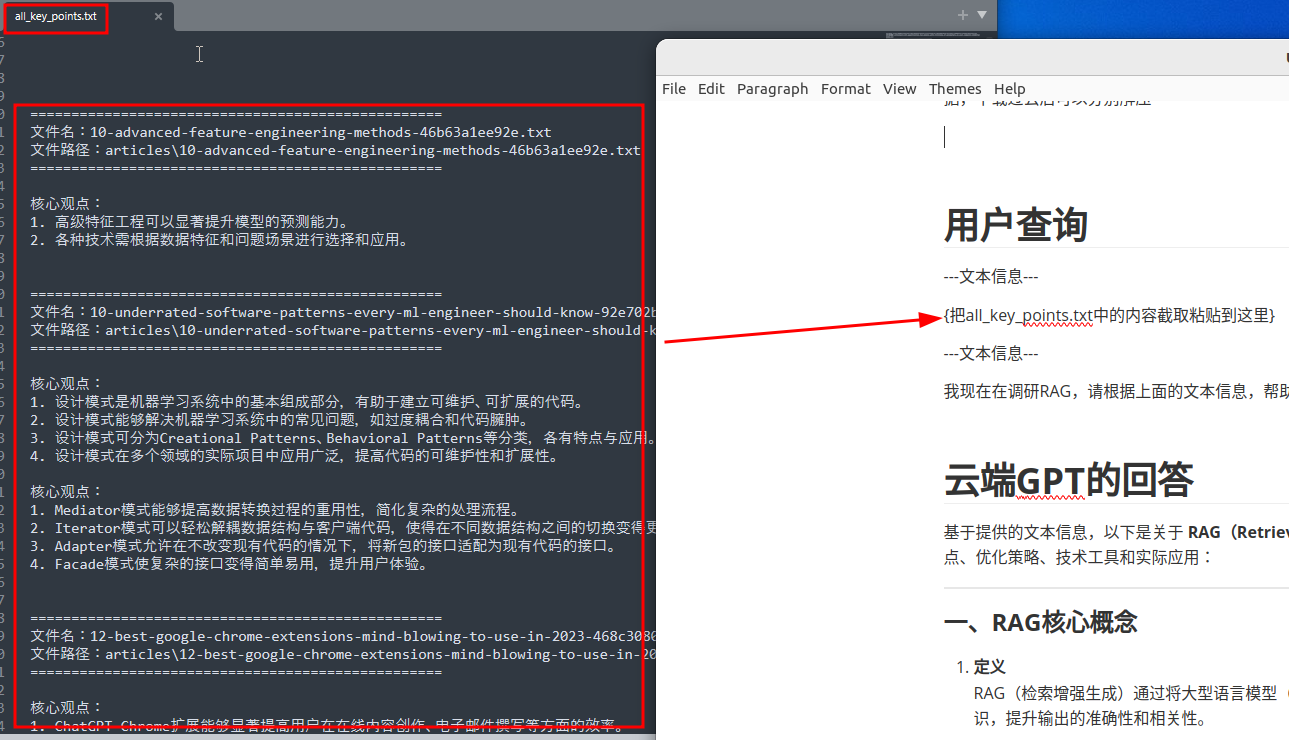
==================================================
详细分析:
核心观点:GPT-4o 是一个自回归的全能模型,能够处理多种输入(包括文本、音频、图像和视频)并生成多种输出(如文本、音频和图像),所有输入和输出均由同一个神经网络处理,且在文本、音频和视觉理解方面的性能显著提升,特别是在多语言处理、语音识别和翻译任务中表现优异。
详细分析:
GPT-4o 作为一款自回归的全能模型,展现了在多模态处理领域的重大突破。它的核心优势在于能够无缝处理多种输入形式(文本、音频、图像、视频)并生成多种输出(文本、音频、图像),且所有处理均由同一个神经网络完成。这种端到端的处理方式不仅简化了模型架构,还显著提升了信息传递的完整性和准确性。
在文本处理方面,GPT-4o 在推理能力上取得了显著进步,例如在 0-shot COT MMLU(通用知识问答)中创下了 88.7% 的高分。这表明它在处理复杂问题和逻辑推理任务时表现更加出色。
在音频处理领域,GPT-4o 的语音识别性能大幅超越 Whisper-v3,尤其是在低资源语言上的表现尤为突出。此外,它在语音翻译任务中也达到了新的技术巅峰,特别是在 MLS 基准测试中表现优异。
视觉理解方面,GPT-4o 在视觉感知基准测试中同样取得了领先成绩,能够更好地处理包含图表和图像的复杂问题。
多语言处理是 GPT-4o 的另一大亮点。它在 M3Exam 基准测试中展现了强大的多语言和视觉理解能力,能够处理来自不同国家的标准化考试题目,包括包含图表和图像的问题。
GPT-4o 的这些进步不仅体现在技术指标上,更在实际应用中展现了其价值。例如,它能够更好地捕捉语音中的情感、背景噪音和多人对话,从而生成更加自然和富有表现力的音频输出。
总的来说,GPT-4o 的推出标志着多模态 AI 模型进入了一个新的时代,它不仅在技术上实现了突破,更为未来的 AI 应用开辟了更广阔的可能性。
==================================================
核心观点:GPT-4o 通过结构化输出功能,能够精确匹配开发者提供的 JSON 模式,有效解决了从非结构化输入生成结构化数据的问题,为开发者提供了更高的灵活性和精确性。
详细分析:
GPT-4o 的结构化输出功能确实是一个重要的突破,尤其是在处理非结构化数据时,它为开发者提供了更高的灵活性和精确性。这个功能的核心在于,GPT-4o 能够根据开发者提供的 JSON 模式,生成完全符合该模式的结构化数据,从而避免了传统方法中常见的输出不一致或格式错误的问题。
结构化输出的优势
-
精确匹配 JSON 模式:开发者可以预先定义好 JSON 模式,GPT-4o 会严格按照这个模式生成输出。这意味着开发者不再需要担心模型输出的格式问题,可以直接将输出用于后续的处理或存储。
-
解决非结构化数据问题:传统的非结构化数据(如自由文本)往往难以直接用于程序化处理。通过结构化输出,GPT-4o 能够将这些非结构化数据转化为结构化的 JSON 格式,极大地简化了数据处理流程。
-
减少开发工作量:在以往,开发者可能需要通过多次请求或使用开源工具来调整模型的输出,以确保其符合预期的格式。而 GPT-4o 的结构化输出功能直接解决了这个问题,减少了开发者的额外工作。
-
提高可靠性:根据 OpenAI 的评估,GPT-4o 在复杂 JSON 模式匹配的测试中达到了 100% 的可靠性,而之前的模型(如 GPT-4-0613)的得分不到 40%。这表明 GPT-4o 在生成结构化数据方面具有极高的准确性和稳定性。
应用场景
- API 集成:在 API 调用中,结构化输出功能可以确保返回的数据格式与预期完全一致,减少了集成时的调试和适配工作。
- 数据自动化处理:对于需要从大量非结构化数据中提取信息的场景,GPT-4o 的结构化输出功能可以自动生成符合特定格式的数据,便于后续的自动化处理。
- 实时数据处理:在需要快速响应的实时系统中,结构化输出功能可以确保数据的格式和内容都符合要求,提高了系统的整体效率和可靠性。
总的来说,GPT-4o 的结构化输出功能不仅提升了模型的实用性,还为开发者提供了更多的灵活性和控制权,使得处理非结构化数据变得更加高效和可靠。
==================================================
核心观点:GPT-4o mini 是 GPT-4o 的成本效益更高的版本,在多个学术基准测试中表现优于 GPT-3.5 Turbo 和其他小型模型,为资源有限的用户提供了高效且经济的解决方案。
详细分析:
GPT-4o mini 是 OpenAI 推出的一款成本效益更高的模型,旨在为资源有限的用户提供一个高效且经济的解决方案。它在多个学术基准测试中表现优异,甚至超越了 GPT-3.5 Turbo 和其他小型模型。以下是关于 GPT-4o mini 的详细展开:
1. 成本与性能的平衡
GPT-4o mini 的设计目标是在保持高性能的同时,显著降低使用成本。它比 GPT-3.5 Turbo 便宜超过 60%,这使得它成为那些需要频繁调用模型或处理大量数据的应用的理想选择。尽管成本更低,但它在多个任务中的表现却优于 GPT-3.5 Turbo,尤其是在文本生成、推理和编码任务中。
2. 学术基准测试中的表现
GPT-4o mini 在多个学术基准测试中表现出色,具体包括:
- MMLU(文本智能与推理):得分为 82.0%,优于 Gemini Flash 和 Claude Haiku。
- MGSM(数学推理):得分为 87.0%,同样优于 Gemini Flash 和 Claude Haiku。
- HumanEval(编码性能):得分为 87.2%,再次超越竞争对手。
- MMMU(多模态理解):得分为 59.4%,表现优于其他小型模型。
这些结果表明,GPT-4o mini 不仅在文本处理方面表现出色,还在数学推理和编码任务中展现了强大的能力。
3. 应用场景
GPT-4o mini 的低成本和低延迟使其适用于多种应用场景,包括:
- 多模型调用:可以轻松地与其他模型进行链式调用或并行处理。
- 大上下文处理:支持高达 128K 的上下文窗口,适合处理大量上下文信息的任务。
- 实时交互:能够快速生成文本响应,适合与客户进行实时交互的应用。
4. 未来扩展
目前,GPT-4o mini 支持文本和视觉输入输出,未来还将支持图像、视频和音频的输入输出。这将进一步扩展其应用范围,使其成为多模态任务的强大工具。
5. 资源有限的用户的理想选择
对于资源有限的用户来说,GPT-4o mini 提供了一个高效且经济的解决方案。它不仅降低了使用成本,还保持了高性能,使得用户能够在有限的预算内实现复杂的任务处理。
总的来说,GPT-4o mini 是 OpenAI 在模型优化方面的一次重要尝试,它通过平衡成本与性能,为用户提供了一个更加灵活和高效的选择。
==================================================


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









