






标题:高维向量挑战与量化技术突破
文章信息摘要:
高维向量在生产环境中面临存储成本、计算复杂性和财务可扩展性等挑战,限制了生成式AI应用的大规模部署和效率。存储高维向量成本高昂,计算复杂度导致延迟增加,财务可扩展性成为实现最佳投资回报率的障碍。内存密集型操作和段构建与合并进一步增加了系统复杂性。为应对这些挑战,量化技术(如标量量化、二进制量化和乘积量化)被引入,通过降低向量精度减少存储和计算需求,提高检索速度。结合HNSW和量化技术,可以在大规模数据集中实现快速检索和内存优化,提升生成式AI应用的性能和可扩展性。
利用GPT提高信息处理效率
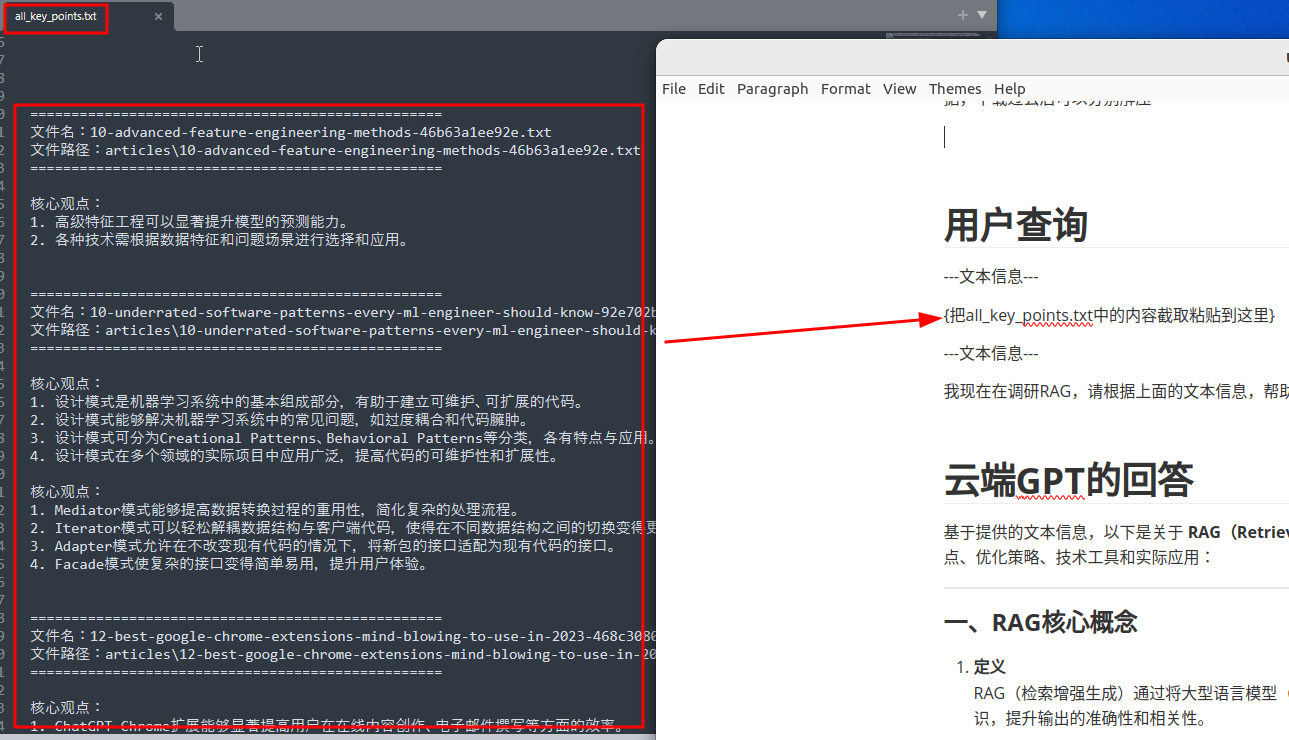
==================================================
详细分析:
核心观点:高维向量在生产环境中面临存储成本、计算复杂性和财务可扩展性等挑战,这些挑战限制了生成式AI应用的大规模部署和效率。
详细分析:
高维向量在生产环境中确实面临诸多挑战,这些挑战不仅影响了生成式AI应用的效率,还限制了其大规模部署的可能性。以下是对这些挑战的详细分析:
1. 存储成本
高维向量通常以32位浮点数的形式存储,每个向量可能包含数百甚至数千个维度。当数据量庞大时,存储这些向量会带来巨大的成本。例如,存储2.5亿个维度为1024的向量,在AWS等云平台上每月可能花费约3600美元。这种高存储需求不仅增加了基础设施的负担,还使得扩展应用变得昂贵。
2. 计算复杂性与延迟
高维向量的计算复杂度较高,尤其是在进行相似性搜索时。随着维度的增加,计算时间和所需的计算资源也会显著增加。这对于实时应用(如推荐系统)来说是一个严重的问题,因为用户期望快速响应。高延迟可能导致用户体验下降,甚至使用户转向竞争对手的应用。
3. 财务可扩展性
随着AI应用的普及和用户参与度的增加,存储和计算成本也会随之增长。这些高昂的成本可能成为实现最佳投资回报率(ROI)的障碍。特别是在数据量快速增长而用户基础尚未完全扩展的情况下,索引和提供向量的成本可能使这些应用难以启动或维持。
4. 内存密集型操作
某些索引技术(如HNSW)需要将所有嵌入向量及其连接存储在内存中,以实现低延迟查询。随着嵌入向量数量的增加,内存需求也会急剧上升,这进一步增加了系统的复杂性和成本。
5. 段构建与合并
在Lucene等系统中,数据被划分为多个段。当新数据(包含新嵌入向量)被添加时,系统需要处理和重新组织这些向量及其HNSW图。这个过程类似于每次出现新地标或道路重组时更新大型地图,既耗时又资源密集。
6. 量化技术的必要性
为了应对这些挑战,量化技术(如标量量化、二进制量化和乘积量化)被引入,以减少嵌入向量的存储需求和计算复杂度。这些技术通过降低向量的精度,显著减少了存储空间和内存使用,同时提高了检索速度。然而,量化也带来了精度损失的问题,需要通过过采样和重评分等策略来弥补。
总结
高维向量在生产环境中的挑战是多方面的,涉及存储、计算、财务和内存等多个维度。为了克服这些挑战,开发者需要采用高效的量化技术和索引方法,以在保持应用性能的同时,降低成本和资源消耗。这不仅有助于生成式AI应用的大规模部署,还能提升其整体效率和用户体验。
==================================================
核心观点:向量量化技术通过减少向量的存储和计算需求,显著提高了生成式AI应用的可扩展性和效率,不同的量化技术(如标量量化、二进制量化和乘积量化)各有优势,可以根据具体需求进行选择。
详细分析:
向量量化技术(Vector Quantization)在生成式AI应用中扮演着至关重要的角色,尤其是在处理高维向量时。通过减少向量的存储和计算需求,向量量化显著提高了应用的可扩展性和效率。不同的量化技术各有其独特的优势,可以根据具体需求进行选择。以下是对几种主要量化技术的详细解析:
1. 标量量化(Scalar Quantization)
标量量化是最简单的量化方法,它通过将向量中的每个元素从高精度(如32位浮点数)转换为低精度(如8位整数)来减少存储空间。具体来说,标量量化会为每个维度确定一个最大值和最小值,然后将这些值划分为若干个等宽的区间(如255个区间,对应8位整数的取值范围)。每个元素会被映射到最近的区间,从而将浮点数向量转换为整数向量。
优势:
- 存储成本显著降低:标量量化可以将存储空间减少32倍,同时保持73%-96%的原始精度。
- 计算效率提升:由于数据量减少,相似性搜索等操作的速度会显著提高。
- 通用性强:标量量化适用于大多数应用场景,尤其是在需要高精度的任务中。
适用场景:图像压缩、音频文件处理、机器学习模型等。
2. 二进制量化(Binary Quantization)
二进制量化将向量中的每个元素简化为两个值:0或1。具体来说,如果元素的值大于零,则表示为1;如果小于或等于零,则表示为0。这种方法将每个浮点数压缩为1位,极大地减少了存储需求。
优势:
- 存储效率极高:二进制量化可以将存储空间减少30倍,是内存效率最高的量化方法。
- 检索速度极快:由于数据量大幅减少,相似性搜索的速度显著提升。
适用场景:适用于向量元素分布集中的模型,尤其是在存储和计算资源极度受限的场景中。
3. 乘积量化(Product Quantization)
乘积量化将高维向量分割为多个子向量,然后对每个子向量进行独立量化。具体来说,乘积量化首先将大向量分割为等长的子向量,然后为每个子向量找到最接近的“质心”(来自预定义的码本),最后用质心的唯一ID代替子向量。
优势:
- 高压缩率:乘积量化可以实现更高的压缩率,适合处理大规模数据集。
- 精确控制:通过调整子向量的大小和质心的数量,可以在精度和效率之间找到平衡。
适用场景:适用于内存占用是首要考虑因素的应用,如FAISS(Facebook AI Similarity Search)等系统。
4. 选择适合的量化方法
不同的量化方法在精度、速度和压缩率方面各有优劣,选择时需要根据具体应用的需求进行权衡:
- 二进制量化:适合对速度和存储效率要求极高的场景,但需要确保模型在二进制量化条件下表现良好。
- 标量量化:作为默认选择,适合大多数需要高精度的应用,平衡了精度、速度和存储成本。
- 乘积量化:适合内存占用是首要考虑因素的应用,但可能会牺牲一定的检索速度。
5. 解决量化带来的召回损失
量化虽然能显著减少存储和计算需求,但也可能导致召回率下降。为了在用户应用中保持高召回率,可以采用以下两种策略:
- 过采样(Oversampling):通过检索更多的候选结果来增加包含相关项的可能性。
- 重评分(Rescoring):对初始检索结果使用高精度向量重新计算相似性,以提高结果的准确性和相关性。
6. 量化与HNSW的结合
HNSW(Hierarchical Navigable Small World)是一种广泛使用的近似最近邻搜索(ANN)算法,通过将向量组织成多层图来加速搜索。将HNSW与量化结合,可以进一步减少内存占用并提高检索速度。例如,使用二进制量化向量与HNSW结合,可以在保持高检索速度的同时,显著降低存储成本。
7. 实际应用案例
假设你有一个餐厅推荐应用,用户可以根据食物偏好(如亚洲菜、印度菜、快餐等)获得推荐。如果你已经有一个优秀的嵌入模型,并且该模型支持二进制量化,你可以考虑以下技术组合:
- 二进制量化:将嵌入向量压缩为二进制向量,减少存储需求。
- HNSW索引:使用HNSW对量化向量进行索引,实现快速图遍历和高效相似性搜索。
- 实时检索:系统能够在保持低存储成本的同时,实时检索推荐结果。
总结
向量量化技术通过减少向量的存储和计算需求,显著提高了生成式AI应用的可扩展性和效率。不同的量化技术各有其独特的优势,可以根据具体需求进行选择。在实际应用中,结合量化与高效的索引技术(如HNSW),可以在保持高检索速度的同时,显著降低存储和计算成本,从而为大规模实时应用提供支持。
==================================================
核心观点:二进制量化通过将数据简化为0或1,显著减少存储需求,但会牺牲一定的精度,适用于对精度要求不高的场景。
详细分析:
二进制量化(Binary Quantization)是一种将高维向量数据简化为二进制形式的技术,即将每个向量元素转换为0或1。这种方法的核心思想是通过极端的简化来大幅减少存储需求,但同时也带来了一定的精度损失。以下是对这一技术的详细展开:
1. 工作原理
二进制量化的过程非常简单:对于每个向量元素,如果其值大于0,则将其量化为1;如果其值小于或等于0,则量化为0。例如,假设我们有一个包含温度数据的向量,二进制量化不会存储具体的温度值,而是只记录每个温度是否高于或低于0度。
2. 存储优势
由于每个向量元素只需要1位(bit)来表示(0或1),二进制量化可以显著减少存储空间。相比于原始的32位浮点数(float32),二进制量化可以将存储需求减少32倍。这对于需要处理大规模数据集的应用场景来说,是一个巨大的优势。
3. 精度损失
然而,二进制量化的简化过程也带来了精度上的损失。由于数据被极端简化,原本的细微差异被忽略,这可能导致在某些应用场景中,检索结果的准确性下降。例如,在推荐系统中,二进制量化可能会导致一些相关性较低的物品被错误地推荐。
4. 适用场景
二进制量化最适合那些对精度要求不高,但对存储和计算速度有极高要求的场景。例如:
- 实时推荐系统:在需要快速响应用户请求的推荐系统中,二进制量化可以显著提高检索速度,同时减少存储成本。
- 大规模数据集:当处理的数据集非常庞大时,二进制量化可以帮助系统在有限的存储资源下高效运行。
5. 补偿精度损失的方法
为了弥补二进制量化带来的精度损失,可以采用以下两种策略:
- 过采样(Oversampling):在检索时,系统会返回比实际需求更多的候选结果,以增加找到相关项的概率。例如,系统可以返回前50个候选结果,而不是前10个。
- 重评分(Rescoring):在初始检索完成后,系统会使用高精度的原始向量对候选结果进行重新评分,以提高最终结果的准确性。
6. 实际应用
在实际应用中,二进制量化通常与其他技术结合使用,例如HNSW(Hierarchical Navigable Small World)索引。通过将二进制量化与HNSW结合,系统可以在保持高速检索的同时,进一步减少内存使用。例如,在餐厅推荐系统中,二进制量化可以显著减少存储需求,而HNSW索引则确保系统能够快速找到与用户偏好匹配的餐厅。
7. 总结
二进制量化是一种极端的简化技术,虽然它带来了显著的存储和计算速度优势,但也伴随着精度上的损失。因此,在选择使用二进制量化时,需要根据具体应用场景的需求,权衡存储、速度和精度之间的关系。对于那些对精度要求不高,但对存储和速度有极高要求的场景,二进制量化无疑是一个强大的工具。
==================================================
核心观点:乘积量化通过将高维向量分割为子向量并分别量化,实现高效的数据压缩和检索,适用于需要高精度和高效检索的场景。
详细分析:
乘积量化(Product Quantization, PQ)是一种高效的数据压缩和检索技术,特别适用于处理高维向量数据。它的核心思想是将高维向量分割成多个子向量,并对每个子向量进行独立的量化处理,从而实现数据的压缩和高效检索。这种方法在需要高精度和高效检索的场景中表现出色,尤其是在大规模数据集和实时应用中。
乘积量化的核心步骤
-
分割(Splitting)
首先,将高维向量分割成多个等长的子向量。例如,一个1024维的向量可以被分割成8个128维的子向量。这种分割方式使得每个子向量的维度降低,便于后续的量化处理。 -
量化(Quantizing)
每个子向量会被量化到一个预定义的“码本”(codebook)中的最近邻“质心”(centroid)。码本是通过对训练数据进行聚类生成的,每个质心代表了一组相似子向量的平均值。通过将子向量映射到最近的质心,可以将高精度的浮点数向量转换为低精度的整数索引。 -
编码(Encoding)
量化后,每个子向量被替换为其对应的质心索引。这些索引可以进一步压缩存储,从而大幅减少数据的存储空间。例如,一个128维的子向量可能只需要一个8位的整数来表示,而不是原始的32位浮点数。
乘积量化的优势
-
高效压缩
通过将高维向量分割并量化,乘积量化可以显著减少数据的存储空间。例如,一个1024维的向量经过乘积量化后,可能只需要原来1/4甚至更少的存储空间。 -
快速检索
由于量化后的向量数据量大幅减少,相似性搜索的计算复杂度也相应降低。这使得乘积量化在实时应用中表现出色,尤其是在需要快速响应的场景中,如推荐系统或搜索引擎。 -
高精度
尽管乘积量化对数据进行了压缩,但它通过保留子向量的局部信息,仍然能够保持较高的检索精度。通过合理设计码本和量化策略,可以在压缩率和精度之间找到平衡。
适用场景
乘积量化特别适用于以下场景:
-
大规模数据集
当数据量非常大时,存储和计算成本成为主要瓶颈。乘积量化通过压缩数据,使得系统能够处理更大规模的数据集,而无需增加硬件资源。 -
实时应用
在需要快速响应的应用中,如实时推荐系统或搜索引擎,乘积量化能够显著提高检索速度,同时保持较高的精度。 -
高维数据
对于高维数据,传统的检索方法往往计算复杂度较高。乘积量化通过分割和量化,降低了计算复杂度,使得高维数据的处理更加高效。
实际应用示例
假设你正在构建一个图像搜索引擎,需要处理数百万张高维图像嵌入向量。使用乘积量化,你可以将每个图像嵌入向量分割成多个子向量,并对每个子向量进行量化。这样,你不仅可以大幅减少存储空间,还能在用户搜索时快速找到相似的图像,提供实时的检索体验。
总结
乘积量化通过将高维向量分割为子向量并分别量化,实现了高效的数据压缩和检索。它在需要高精度和高效检索的场景中表现出色,尤其是在大规模数据集和实时应用中。通过合理设计量化策略,可以在压缩率和精度之间找到平衡,从而为各种AI应用提供强大的支持。
==================================================
核心观点:量化技术虽然能提高存储和检索效率,但可能导致召回率下降,需要通过重评分和过采样等技术来弥补,以确保检索结果的准确性。
详细分析:
量化技术在提高存储和检索效率方面确实表现出色,但它也带来了一些潜在的挑战,尤其是召回率的下降。召回率是指系统能够检索到所有相关结果的能力,而量化过程可能会因为数据精度的降低而导致一些相关结果被遗漏。为了弥补这一缺陷,生产环境中通常会采用重评分(Rescoring)和过采样(Oversampling)等技术来确保检索结果的准确性。
1. 过采样(Oversampling)
过采样的核心思想是扩大检索范围,增加候选结果的数量,从而提高召回率。具体来说,系统在初始检索时会返回比实际需求更多的结果。例如,如果用户需要10个推荐结果,系统可能会先检索50个候选结果。这样做的好处是,即使量化过程中丢失了一些精度,通过扩大检索范围,系统仍然有更高的概率捕捉到相关的结果。
应用场景:过采样特别适用于那些对召回率要求较高的场景,比如推荐系统或搜索引擎。在这些场景中,用户希望尽可能多地看到相关结果,而不仅仅是前几个最匹配的结果。
2. 重评分(Rescoring)
重评分则是在过采样的基础上,对候选结果进行进一步的精确筛选。具体步骤如下:
- 初始检索:系统首先使用量化后的向量进行快速检索,返回一组候选结果。
- 重评分:然后,系统会使用原始的高精度向量(如float32)对这些候选结果进行重新计算相似度,以确保最终推荐结果的准确性。
优势:重评分可以在不显著增加计算开销的情况下,显著提高检索结果的准确性。因为只有一小部分候选结果需要重新计算,系统可以在保持高效的同时,确保最终结果的精确性。
3. 过采样与重评分的结合
在实际生产环境中,过采样和重评分通常会结合使用,以达到最佳的效果。例如,在一个推荐系统中:
- 初始检索:系统使用量化向量快速检索出50个候选结果。
- 过采样:这50个结果中包含了更多的潜在相关项。
- 重评分:系统再对这50个结果中的前10%或20%进行重评分,确保最终推荐的10个结果是最相关和最准确的。
4. 量化与召回率的权衡
虽然量化技术可以显著降低存储和计算成本,但它也带来了召回率的潜在损失。通过过采样和重评分,系统可以在保持高效的同时,最大限度地减少召回率的下降。这种权衡在生产环境中尤为重要,尤其是在用户对结果准确性要求较高的应用中。
5. 实际应用中的选择
在实际应用中,选择哪种技术取决于具体的业务需求。如果存储和计算资源非常紧张,量化技术可能是首选,但必须结合过采样和重评分来弥补召回率的损失。如果对召回率要求极高,可能需要考虑使用更高精度的量化方法,或者减少量化的程度。
总之,量化技术虽然带来了存储和检索效率的提升,但通过过采样和重评分等技术,我们可以在不牺牲召回率的情况下,确保检索结果的准确性。这种平衡是生产环境中成功应用量化技术的关键。
==================================================
核心观点:结合HNSW(分层可导航小世界)和量化技术,可以在大规模数据集中实现快速检索和内存优化,进一步提升生成式AI应用的性能和可扩展性。
详细分析:
在生成式AI应用中,高维向量(如嵌入)的处理和存储是一个关键挑战。为了应对这一挑战,结合HNSW(分层可导航小世界)和量化技术可以显著提升系统的性能和可扩展性。以下是如何通过这两种技术实现快速检索和内存优化的详细解释:
1. HNSW 的基本原理
HNSW 是一种用于高维空间中近似最近邻搜索(ANN)的算法。它通过构建一个多层图结构来组织向量,每一层都代表不同粒度的相似性。这种分层结构使得搜索过程能够快速缩小范围,从而在大量数据中高效地找到最相似的向量。
- 多层图结构:HNSW 将向量组织成一个多层图,每一层的节点代表一个向量,边连接相似的节点。搜索时,算法从顶层开始,逐步向下层移动,快速定位到最相似的节点。
- 快速检索:由于 HNSW 的分层结构,搜索过程避免了全量扫描,大大减少了计算复杂度,特别适合实时应用。
2. 量化技术的作用
量化技术通过减少向量的精度来压缩其存储空间,从而降低内存和存储成本。常见的量化方法包括标量量化、二进制量化和乘积量化。
- 标量量化:将浮点数向量转换为整数向量,例如将 float32 转换为 int8,从而减少存储空间。
- 二进制量化:将向量中的每个元素转换为二进制值(0 或 1),进一步压缩存储空间。
- 乘积量化:将高维向量分割为多个子向量,每个子向量单独量化,通过查找码表来减少存储需求。
3. HNSW 与量化的结合
将 HNSW 与量化技术结合,可以在保持高效检索的同时,显著减少内存和存储开销。
- 内存优化:量化后的向量占用的内存更少,HNSW 图结构中的节点和边也因此变得更轻量,从而降低了整体内存需求。例如,二进制量化可以将存储需求减少 20 倍。
- 快速检索:量化后的向量在 HNSW 图中可以更快地遍历,因为每个节点的数据量更小,计算速度更快。这对于实时应用(如推荐系统)尤为重要。
- 可扩展性:通过量化,系统可以处理更大规模的数据集,而无需增加额外的硬件资源。这使得生成式AI应用能够随着用户和数据量的增长而扩展。
4. 实际应用场景
假设你正在开发一个餐厅推荐系统,用户可以根据食物偏好(如亚洲菜、印度菜、快餐等)获得推荐。结合 HNSW 和量化技术,系统可以实现以下优化:
- 二进制量化:将嵌入向量压缩为二进制形式,减少存储需求。
- HNSW 索引:将量化后的向量组织成 HNSW 图,实现快速相似性搜索。
- 实时检索:系统能够在毫秒级时间内返回推荐结果,同时保持较低的存储成本。
5. 性能与精度的平衡
虽然量化技术可以显著减少存储和计算成本,但它也可能导致一定的精度损失。为了在性能和精度之间取得平衡,可以采用以下策略:
- 重评分(Rescoring):在初始检索后,使用高精度向量对候选结果进行重新评分,以提高推荐的准确性。
- 过采样(Oversampling):检索更多的候选结果,以增加相关项被包含的可能性,然后通过重评分筛选出最相关的结果。
6. 总结
通过将 HNSW 与量化技术结合,生成式AI应用可以在大规模数据集中实现快速检索和内存优化。这种组合不仅降低了存储和计算成本,还提升了系统的可扩展性,使其能够应对不断增长的数据和用户需求。在实际应用中,选择合适的量化方法和优化策略,可以在保持高效检索的同时,最大限度地减少精度损失,从而为用户提供更好的体验。
==================================================


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









