






标题:Mistral-7B:开源AI的效率革命
文章信息摘要:
Mistral-7B模型通过创新的“滑动窗口注意力机制”和“滚动缓存”技术,显著降低了计算和内存需求,提升了训练效率。这些技术使模型在性能和效率上超越了同规模甚至更大规模的模型,展示了开源AI的巨大潜力。Mistral-7B的成功不仅证明了小型、高效模型在特定任务上的优势,还为企业应用提供了新的方向。未来,AI模型可能呈现分化趋势:大型模型适用于消费者端,而小型、高效模型将在企业端广泛应用,推动AI技术在不同场景中的优化和普及。
==================================================
详细分析:
核心观点:Mistral-7B模型通过创新的’滑动窗口注意力机制’和’滚动缓存’技术,显著降低了计算和内存需求,提升了训练效率,在性能和效率上超越了同规模甚至更大规模的模型,展示了开源AI的潜力。
详细分析:
Mistral-7B模型确实在AI领域掀起了一场小革命,尤其是在计算效率和性能优化方面。它的创新主要体现在两个关键技术:滑动窗口注意力机制和滚动缓存。这些技术不仅降低了计算和内存需求,还提升了模型的训练效率,使其在性能和效率上超越了同规模甚至更大规模的模型。
1. 滑动窗口注意力机制(Slided-Window Attention)
传统的Transformer模型在处理长序列时,计算成本会随着序列长度的增加呈二次方增长。这是因为每个词都需要与序列中所有前面的词进行“对话”(即计算注意力权重)。Mistral-7B通过引入滑动窗口注意力机制,巧妙地解决了这个问题。
-
核心思想:每个词不再与所有前面的词进行对话,而是只与固定数量的前面词进行对话。比如,窗口大小为3时,每个词只与它前面的3个词进行交互。
-
优势:这种限制大大减少了计算量,因为每个词只需要与少数几个词进行注意力计算,而不是整个序列。虽然这看起来可能会丢失一些全局上下文信息,但实际上,Transformer的多层结构允许信息通过注意力层逐步传递。即使某个词不能直接与序列开头的词对话,它仍然可以通过中间词间接获取到这些信息。
-
效果:Mistral-7B在处理长序列时表现出色,证明了这种机制不仅没有降低模型质量,反而因为减少了计算需求,使得模型能够处理更长的序列。
2. 滚动缓存(Rolling Cache)
另一个创新是滚动缓存技术,它进一步优化了内存使用。
-
核心思想:在传统的Transformer中,每个新词生成时都需要重新计算与前面所有词的注意力权重,这导致了大量的冗余计算。Mistral-7B通过引入滚动缓存,只存储最近的计算结果,随着序列的增长,旧的缓存会被新的计算结果覆盖。
-
优势:这种机制不仅减少了内存需求,还提高了计算效率。由于每个词只与固定数量的前面词进行对话,缓存的大小也得到了控制,从而进一步降低了内存占用。
3. 开源AI的潜力
Mistral-7B的成功展示了开源AI的巨大潜力。尽管与硅谷巨头的大型模型相比,开源模型在资源上处于劣势,但通过创新的技术手段,Mistral-7B在性能和效率上实现了突破。这不仅证明了小型、高效的模型在特定任务上可以超越大型模型,还为开源社区提供了新的发展方向。
-
企业应用:对于企业来说,小型、高效的模型具有巨大的吸引力。它们不仅成本更低,还能在特定任务上表现出色,这使得开源模型在企业应用中具有广阔的前景。
-
未来趋势:随着技术的进步,未来可能会出现更多像Mistral-7B这样的高效模型,推动开源AI的进一步发展,甚至可能改变AI领域的竞争格局。
总的来说,Mistral-7B通过创新的技术手段,展示了开源AI在性能和效率上的巨大潜力,为未来的AI发展提供了新的思路。
==================================================
核心观点:未来,大型模型可能更适用于消费者端,而小型、高效的模型将在企业端有更广泛的应用,这一趋势将推动AI技术在不同场景中的优化和普及。
详细分析:
未来,AI模型的发展可能会呈现出一种分化的趋势:大型模型更适用于消费者端,而小型、高效的模型则将在企业端有更广泛的应用。这种趋势不仅反映了技术需求的多样性,也预示着AI技术在不同场景中的优化和普及。
大型模型在消费者端的优势
大型模型,如ChatGPT,因其强大的通用性和多功能性,非常适合消费者端的需求。消费者通常需要一个能够处理各种任务的AI助手,无论是日常生活中的问题解答、创意写作,还是复杂的知识查询。大型模型能够提供广泛的服务,满足多样化的需求,因此它们在消费者市场中具有巨大的吸引力。
此外,消费者端的应用场景通常对模型的响应速度和交互体验有较高的要求。大型模型通过其强大的计算能力和丰富的训练数据,能够提供更加流畅和自然的交互体验,从而提升用户满意度。
小型、高效模型在企业端的应用
相比之下,企业端的需求则更加专注于特定任务的优化和效率。企业通常需要AI模型在某个特定领域表现出色,而不是在所有领域都具备广泛的能力。例如,金融行业可能需要一个专门用于风险评估的模型,而医疗行业则可能需要一个专注于疾病诊断的模型。
小型、高效模型在这些场景中具有显著的优势。它们不仅能够在特定任务上表现出色,还能够降低计算成本和资源消耗。这对于企业来说尤为重要,因为它们需要在保证性能的同时,控制运营成本。
推动AI技术的优化和普及
这种分化的趋势将推动AI技术在不同场景中的优化和普及。大型模型在消费者端的广泛应用将促使技术不断进步,提升用户体验;而小型、高效模型在企业端的普及则将推动AI技术在各个行业的深入应用,提升企业的运营效率和竞争力。
此外,这种趋势还可能促进开源社区的发展。企业可以通过使用开源的小型模型,获得更高的灵活性和控制权,从而更好地满足自身的需求。这不仅有助于推动AI技术的创新,还能够加速技术的普及和应用。
总的来说,未来AI模型的发展将更加注重多样性和优化,以满足不同场景的需求。这种趋势将推动AI技术在消费者端和企业端的广泛应用,促进技术的不断进步和普及。
==================================================
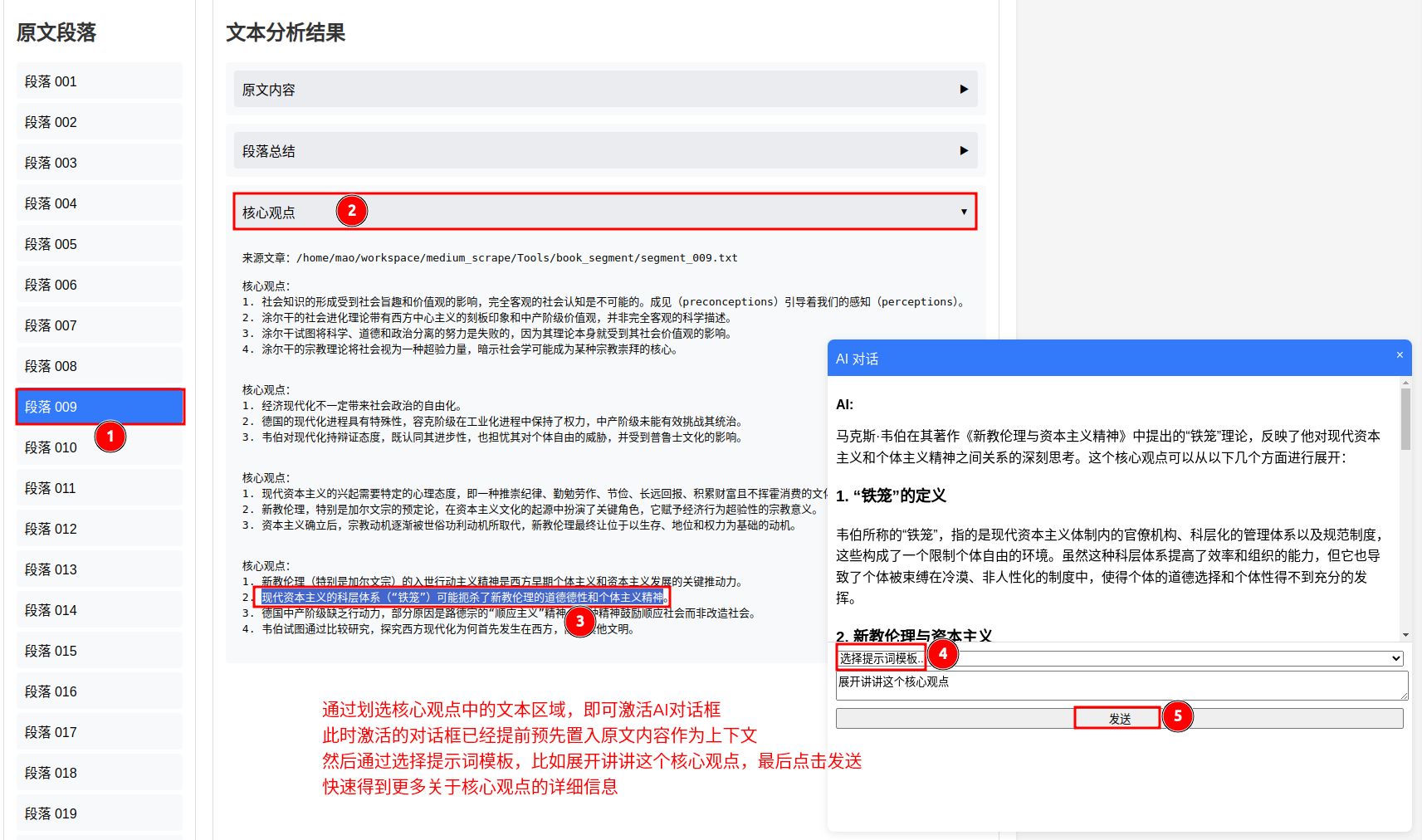
我搭建了一个小网页,关于利用GPT读书的
Demo试玩: http://123.57.80.68:3000/
先介绍一下数据信息,然后说这种读书方法的优势:
1、10倍信息压缩
2、阅读每个段落的核心观点
3、针对感兴趣的观点,可通过划选文本再通过预设提示词,快速提问


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









