






目录
1.安装PPOCRLabel并为自己的数据打标签,构建数据集
代码:从网址中下载压缩包并解压缩得到名为“PaddleOCR-main”的文件夹(我直接放到了桌面上)。
一、环境配置
(一)PaddlePaddle运行环境部署
1.安装anaconda(网上教程很多很详细)
2.创建环境
conda create --name padocr python=3.9
# 检查是否是64位版本(基本上都是)
python --version
python -c "import platform;print(platform.architecture()[0]);print(platform.machine())"3.激活环境并在该环境下安装PaddlePaddle框架
飞桨PaddlePaddle-源于产业实践的开源深度学习平台

conda activate padocr
# 比自己电脑的cuda版本低就行,我这里下载的我电脑可以接受的最新的
conda install paddlepaddle-gpu==2.6.1 cudatoolkit=11.6 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge
# 检查是否安装成功
import paddle
paddle.utils.run_check() # 如果出现PaddlePaddle is installed successfully!,说明已成功安装
4.下载requirments.txt中的库
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple(二)PaddleOCR安装【非重点】
如果训练自己的数据集,则不需要安装。
参考资料:
- PaddleOCR/doc/doc_ch/quickstart.md at main · PaddlePaddle/PaddleOCR · GitHub
- PaddleOCR开源代码有NameError: name ‘predict_system‘ is not defined问题-CSDN博客
pip install paddleocr==2.7.0.0 -i https://mirror.baidu.com/pypi/simple
# 放一张图片在桌面上,测试安装是否成功
cd Desktop
paddleocr --image_dir img.pdf --use_angle_cls true --use_gpu false在测试的过程中,出现了OMP的错误,显示如下。
解决该错误的方法如下(这里我同样属于情况一,删去其中一个,问题就解决了):
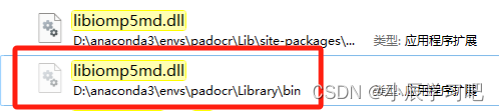
【补充,没有这些错误就不用看了】
注意:如果上面安装出现问题时,比如缺少shapely,可以采用如下的方法。
对于Windows环境用户:直接通过pip安装的shapely库可能出现[winRrror 126]找不到指定模块的问题。建议从下面网址下载shapely安装包完成安装。
Links for shapely (tsinghua.edu.cn)
(1)下载shapely安装包并将其放置在“PaddleOCR-main”文件夹中
(2)安装shapely后再执行下载paddleocr的命令
cd PaddleOCR-main
pip install shapely-2.0.4-cp38-cp38-win_amd64.whl二、在自己的数据集上训练模型
(一)制作自己的数据集
参考:
1.安装PPOCRLabel并为自己的数据打标签,构建数据集
pip install PPOCRLabel -i https://pypi.tuna.tsinghua.edu.cn/simple
# 完成后,位置在D:\anaconda3\envs\padocr\Lib\site-packages\PPOCRLabel
# 选择标签模式来启动,一般选第一个【检测+识别】的即可
PPOCRLabel --lang ch # 启动【普通模式】,用于打【检测+识别】场景的标签
PPOCRLabel --lang ch --kie True # 启动 【KIE 模式】,用于打【检测+识别+关键字提取】场景的标签2.数据集的划分
# 下面是官网给出的示例
cd ./PPOCRLabel # 将目录切换到PPOCRLabel文件夹下
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath ../train_data
# 一定要注意:路径一定要设置正确!!!
'''
trainValTestRatio 是训练集、验证集、测试集的图像数量划分比例,根据实际情况设定,默认是6:2:2
datasetRootPath 是PPOCRLabel标注的完整数据集存放路径。默认路径是 PaddleOCR-main/train_data 。
数据集在划分前应有如下结构:
|-train_data
|-crop_img
|- word_001_crop_0.png
|- word_002_crop_0.jpg
|- word_003_crop_0.jpg
| ...
|- Label.txt
|- rec_gt.txt
|- word_001.png
|- word_002.jpg
|- word_003.jpg
| ...
'''我的数据集的划分
cd ./PPOCRLabel
python gen_ocr_train_val_test.py --trainValTestRatio 7:2:1 --datasetRootPath ../train_data/carriages
'''
划分前我数据集的结构:
|- train_data
|- carriages
|- crop_img
|- carriage1450036_1_crop_0.jpg
|- carriage1450036_1_crop_1.jpg
|- carriage1450036_2_crop_0.jpg
| ...
|- fileState.txt
|- Label.txt
|- rec_gt.txt
|- Cache.cach
|- carriage1450036_1.png
|- carriage1450036_2.jpg
|- carriage1500244_1.jpg
| ...
'''


'''
划分后我数据集的结构:
|- train_data
|- carriages
|- det
|- train(图像)
|- val
|- test
|- train.txt(标签)
|- val.txt
|- test.txt
|- rec
|- train
|- val
|- test
|- train.txt
|- val.txt
|- test.txt
'''【补充】如果在ubuntu中运行划分数据集的命令的话,在修改fileState.txt中的路径后,会产生如下错误。

此时,只需要将gen_ocr_train_val_test.py中的 \\ 修改为 / 即可。

(二)训练
参考:PaddleOCR/applications/轻量级车牌识别.md at main · PaddlePaddle/PaddleOCR (github.com)
doc/doc_ch/models_list.md,在这里面下载预训练权重,并放在新建的pretrain_models中。

首先在汽车车牌号数据集下做初步的训练。
汽车车牌号数据集CCPD2020的文件结构如下:
|- train_data
|- carriages
|- det
|- rec
|- CCPD2020
|- ccpd_green
|- train(图像)
|- val
|- test
|- PPOCR
|- train
|- crop_imgs(图像)
|- det.txt
|- rec.txt
|- val
|- crop_imgs(图像)
|- det.txt
|- rec.txt
|- test
|- crop_imgs(图像)
|- det.txt
|- rec.txt1.文本检测训练
# 首先,在汽车车牌号数据集CCPD2020上训练检测模型,具体过程可以前面参考链接里的内容
python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=pretrain_models/ch_PP-OCRv3_det_distill_train/ch_PP-OCRv3_det_distill_train/student.pdparams Global.save_model_dir=output/det_carlicense Global.epoch_num=100 Global.eval_batch_step="[0, 772]" Optimizer.lr.name=Const Optimizer.lr.learning_rate=0.0005 Optimizer.lr.warmup_epoch=5 Optimizer.regularizer.factor= 5.0e-05 Train.dataset.data_dir=./train_data/CCPD2020/ccpd_green Train.dataset.label_file_list=[./train_data/CCPD2020/PPOCR/train/det.txt] Eval.dataset.data_dir=./train_data/CCPD2020/ccpd_green Eval.dataset.label_file_list=[./train_data/CCPD2020/PPOCR/val/det.txt]
# 然后,利用在汽车车牌号数据集上训练得到的权重来训练车厢号数据集
python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=./output/det_carlicense/best_accuracy.pdparams Global.save_model_dir=./output/PP-OCRv3_det Global.epoch_num=500 Optimizer.lr.name=Const Optimizer.lr.learning_rate=0.0005 Optimizer.lr.warmup_epoch=20 Optimizer.regularizer.factor=5.0e-05 Train.dataset.data_dir=./train_data/det/train/ Train.dataset.label_file_list=[./train_data/det/train.txt] Eval.dataset.data_dir=./train_data/det/val/ Eval.dataset.label_file_list=[./train_data/det/val.txt]2.文本识别训练

# 注意:文本识别的训练需要有一个txt文件来存储数据集中出现的文字、数字、字母等。
# 其位置放在ppocr/utils/train_carriage_mine.txt
# 首先,在汽车车牌号数据集CCPD2020上训练识别模型,具体过程可以前面参考链接里的内容
python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=./pretrain_models/ch_PP-OCRv3_rec_train/ch_PP-OCRv3_rec_train/student Global.save_model_dir=./output/rec_carlicense Global.character_dict_path=ppocr/utils/train_carriage_mine Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True Train.dataset.data_dir=./train_data/CCPD2020/PPOCR Train.dataset.label_file_list=[./train_data/CCPD2020/PPOCR/train/rec.txt] Eval.dataset.data_dir=./train_data/CCPD2020/PPOCR Eval.dataset.label_file_list=[./train_data/CCPD2020/PPOCR/val/rec.txt] # 混合精度训练
# 然后,利用在汽车车牌号数据集上训练得到的权重训练车厢号数据集
python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=./output/rec_carlicense/best_accuracy Global.save_model_dir=./output/PP-OCRv3_rec Global.character_dict_path=ppocr/utils/train_carriage_mine Global.use_amp=True Global.scale_loss=1024.0 Global.use_dynamic_loss_scaling=True Train.dataset.data_dir=./train_data/rec/train Train.dataset.label_file_list=[./train_data/rec/train.txt] Eval.dataset.data_dir=./train_data/rec/val Eval.dataset.label_file_list=[./train_data/rec/val.txt] # 混合精度训练(三)测试
1.文本检测模型测试
python tools/infer_det.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=./output/PP-OCRv3_det/best_accuracy.pdparams Global.infer_img="C:\Users\W.ChenY\Desktop\PaddleOCR-main\train_data\det\test\carriage1503954_3.jpg"
2.文本识别模型测试
python tools/infer_rec.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=./output/PP-OCRv3_rec/best_accuracy.pdparams Global.infer_img="train_data/carriages/crop_img/carriage1505936_1_crop_1.jpg"(四)转换为推理模型
1.文本检测模型
python tools/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o Global.pretrained_model=output/PP-OCRv3_det/best_accuracy.pdparams Global.save_inference_dir=output/infer_mine/det2.文本识别模型
python tools/export_model.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=output/PP-OCRv3_rec/best_accuracy.pdparams Global.save_inference_dir=output/infer_mine/rec(五)检测模型和识别模型推理
检测模型和识别模型同时使用
# 注意:使用识别模型进行推理时,需要指定rec_char_dict_path
# 单张图像检测+识别
python tools/infer/predict_system.py --image_dir="train_data/carriages/carriage1553696_2.jpg" --det_model_dir="output/infer_mine/det" --rec_model_dir="output/infer_mine/rec" --use_angle_cls=false --rec_char_dict_path="ppocr/utils/train_carriage_mine"
# 文件夹内全部图像检测+识别
python tools/infer/predict_system.py --det_model_dir="output/infer_mine/det" --rec_model_dir="output/infer_mine/rec" --image_dir="train_data/carriages" --draw_img_save_dir=infer/fine-tune --use_dilation=true --rec_char_dict_path="ppocr/utils/train_carriage_mine"只使用识别模型
python tools/infer/predict_rec.py --image_dir="train_data/carriages/crop_img/carriage1505936_1_crop_1.jpg" --rec_model_dir="output/infer_mine/rec" --rec_char_dict_path="ppocr/utils/ppocr/utils/train_carriage_mine"
(六)转换label并计算准确度指标
# 将gt和上一步保存的预测结果转换为端对端评测需要的数据格式,并根据转换后的数据进行端到端指标计算
# 转换gt信息
python tools/end2end/convert_ppocr_label.py --mode=gt --label_path="train_data/carriages/Label.txt" --save_folder=end2end/gt
# 转换fine-tune预测信息
python tools/end2end/convert_ppocr_label.py --mode=pred --label_path=infer/fine-tune/system_results.txt --save_folder=end2end/fine-tune
# 将两者进行比对评估
python tools/end2end/eval_end2end.py end2end/gt end2end/fine-tunegt: fine_tune:
fine_tune:

三、模型转换onnx
(一)环境准备
需要准备 Paddle2ONNX 模型转化环境,和 ONNXRuntime 预测环境
python3 -m pip install paddle2onnx -i https://mirror.baidu.com/pypi/simple
python3 -m pip install onnxruntime -i https://mirror.baidu.com/pypi/simple(二)模型转换
注意:在该步骤中,由于paddlepaddle-gpu版本的问题,转换识别模型时出现了错误,即: [ERROR] Cannot found attribute beta in op: swish
解决方法:
(1)首先,我的paddlepaddle-gpu版本为2.6.1,需要降低为2.5.2。
python -m pip install -U paddlepaddle-gpu==2.5.2 -i https://mirror.baidu.com/pypi/simple(2)然后,将检测模型和识别模型重新转换为推理模型。(步骤在上面,即:二(四))
(3)最后,使用如下命令即可成功转出onnx。
# 检测
paddle2onnx --model_dir ./output/infer_mine/det --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./inference/det_onnx/model.onnx --opset_version 11 --enable_onnx_checker True
# 识别
paddle2onnx --model_dir ./output/infer_mine/rec --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./inference/rec_onnx/model.onnx --opset_version 11 --enable_onnx_checker True
# 分类(这个我用不到)
paddle2onnx --model_dir ./inference/ch_ppocr_mobile_v2.0_cls_infer --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file ./inference/cls_onnx/model.onnx --opset_version 11 --enable_onnx_checker True
python -m paddle2onnx.optimize --input_model=inference/det_onnx/model.onnx --output_model=inference/det_onnx/model.onnx --input_shape_dict="{'x': [-1,3,-1,-1]}"(三)推理预测
python tools/infer/predict_system.py --use_gpu=False --use_onnx=True --det_model_dir=./inference/det_onnx/model.onnx --rec_model_dir=./inference/rec_onnx/model.onnx --image_dir=./train_data/carriages/carriage1450036_1.jpg --rec_char_dict_path="ppocr/utils/train_carriage_mine"--------------------------------------------截止--------------------------------------------
【补充】
车号识别模型的验证和推理
python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml
python tools/infer_rec.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o Global.pretrained_model=output/rec_carlicense/best_accuracy.pdparams Global.infer_img="图像绝对路径"














 1807
1807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









