






一、OCR应用需求
光学字符识别(Optical Character Recognition, OCR),是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。随着人工智能和计算机视觉技术的不断发展,OCR技术在各个领域得到了广泛应用,如:证件识别,车牌识别、票据识别、办公文档数字化等,极大地提高了处理效率。
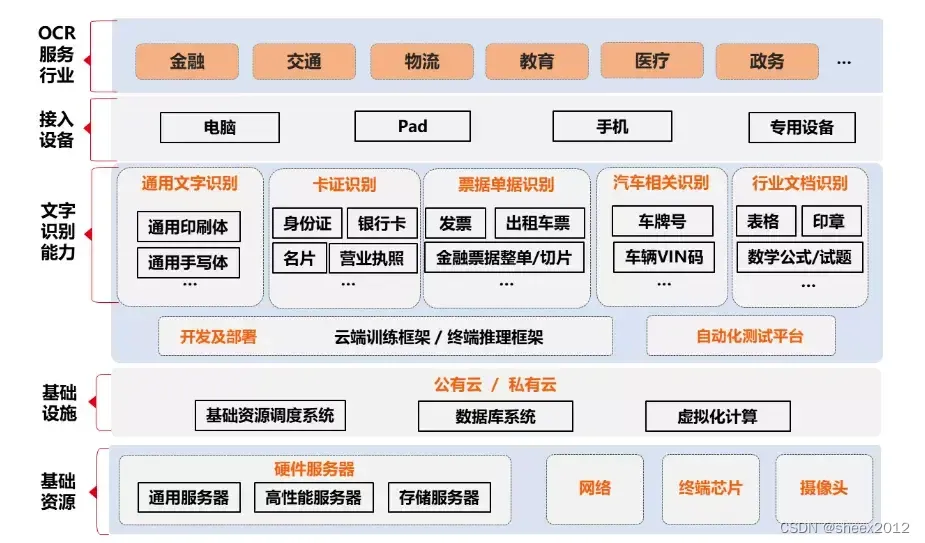
目前OCR技术已日渐成熟,对于常见应用,很多厂商如阿里、百度、腾讯等都提供了第三方服务,识别的速度、准确度也非常不错。但API调用是收费的,对于服务调用频次高的个人和企业,这个费用会显得比较高昂,另一方面,很多单位的敏感内容也不宜连接互联网。因而寻求一种可以部署在本地的OCR服务显得尤为重要。同时,随着深度学习技术的不断深入和普及,开源OCR的识别性能也大幅度提升,达到实用水平,成为一个非常不错的选择。
在PaddleOCR、CnOCR、chinese_lite OCR、EasyOCR、Tesseract OCR和chineseocr等支持中文的开源OCR中,整体来看PaddleOCR和CnOCR在识别性能、速度和易用性等方面相对来说比较有优势,推荐使用。因而我们这里采用PaddleOCR。
二 、PaddleOCR 简介
PaddleOCR是一个基于PaddlePaddle框架开发的OCR系统,其技术体系包括文字检测、文字识别、文本方向检测和图像处理等模块。PaddleOCR具有高精度、高效性、易用性、多语种支持和鲁棒性等优点,为用户提供了一个强大的OCR解决方案。PaddleOCR依托于PaddlePaddle核心框架,在模型算法、预训练模型库、工业级部署等层面均提供了丰富的解决方案,并且提供了数据合成、半自动数据标注工具,满足开发者的数据生产需求。

PaddleOCR支持五种部署方案,分别为服务化Paddle Serving、服务端/云端Paddle Inference、移动端/边缘端Paddle Lite、网页前端Paddle.js。在工业级部署层面,PaddleOCR提供了基于Paddle Inference的服务器端预测方案,基于Paddle Serving的服务化部署方案,以及基于Paddle-Lite的端侧部署方案,满足不同硬件环境下的部署需求,同时提供了基于PaddleSlim的模型压缩方案,可以进一步压缩模型大小。以上部署方式都完成了训推一体全流程打通,以保障开发者可以高效部署,稳定可靠。
上面提到,PaddleOCR依托于PaddlePaddle框架的,在部署时往往需要同时安装PaddlePaddle框架以及相应的底层CUDA等驱动程序,安装部署的工作量大,学习曲线陡峭,给一般的开发者带来很大困扰(Paddle Inference可以脱离PaddlePaddle框架,但是在对CUDA的支持上,存在版本少,兼容性不足等问题,而动辄1个多G的动态库也不是个事呀)。而且,部署环境复杂时,也容易带来环境兼容性、内存占用等一系列问题[1]。
那,有没有更加简洁高效的部署方式呢?
有,那就是ONNX。
三、 ONNX简介
通常我们在训练模型时可以使用很多不同的框架,比如有的喜欢用 Pytorch,有的喜欢 TensorFLow,也有的喜欢 MXNet,以及深度学习最开始流行的 Caffe等,这样不同的训练框架就导致了产生不同的模型结果包,在模型进行部署推理时就需要不同的依赖库,而且同一个框架不同的版本之间的差异较大,为了解决这个混乱问题,LF AI 联合Facebook, MicroSoft等公司制定了机器学习模型的标准,这个标准叫做开放神经网络交换(Open Neural Network Exchange)简称ONNX,所谓开放就是ONNX定义了一组和环境,平台均无关的标准格式,来增强各种AI模型的可交互性。
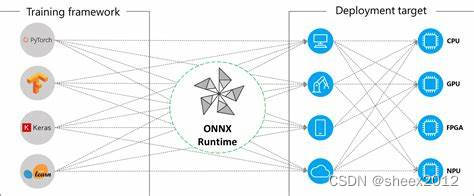
ONNX 定义了一种可扩展的计算图模型、一系列内置的运算单元(OP)和标准数据类型。每一个计算流图都定义为由节点组成的列表,并构建有向无环图。其中每一个节点都有一个或多个输入与输出,每一个节点称之为一个 OP。这相当于一种通用的计算图,不同深度学习框架构建的计算图都能转化为它。

有了ONNX,经过工业界和学术界数年的探索,模型部署有了一条基于ONNX的推理流水线,这一流水线解决了模型部署中的两大问题:使用对接深度学习框架和推理引擎的中间表示,开发者不必担心如何在新环境中运行各个复杂的框架;通过中间表示的网络结构优化和推理引擎对运算的底层优化,模型的运算效率大幅提升。
四、ONNX Runtime安装部署
ONNX Runtime (ORT)是Microsoft开源的一个项目,用于跨平台的机器学习模型推理,支持多种编程语言和框架、操作系统及硬件平台。当一个模型从PyTorch、TensorFlow等框架转换为ONNX模型后,使用ONNX Runtime即可进行模型推理,而不再需要原先的训练框架。这使得模型的部署更为便捷和通用。此外,ONNX Runtime通过内置的图优化策略和集成的硬件加速库,可以获得更快的推理速度。即使是在相同的硬件平台,ONNX Runtime也可以获得比PyTorch和TensorFlow更好的运行速度。
1. Paddle模型转换为ONNX
PaddlePaddle支持将训练完成后的模型转换为ONNX格式,可以从PaddlePaddle官方的Paddle2ONNXhttps://github.com/PaddlePaddle/Paddle2ONNX![]() https://github.com/PaddlePaddle/Paddle2ONNX下载和编译,其步骤如下:
https://github.com/PaddlePaddle/Paddle2ONNX下载和编译,其步骤如下:
1). 打开VS命令行工具
系统菜单中,找到x64 Native Tools Command Prompt for VS 2019,打开
2). 安装Protobuf
git clone https://github.com/protocolbuffers/protobuf.git
cd protobuf
git checkout v3.16.0
cmake -G "Visual Studio 16 2019" -A x64
-DCMAKE_INSTALL_PREFIX=D:\Paddle\installed_protobuf_lib
-Dprotobuf_MSVC_STATIC_RUNTIME=OFF -Dprotobuf_BUILD_SHARED_LIBS=OFF
-Dprotobuf_BUILD_TESTS=OFF -Dprotobuf_BUILD_EXAMPLES=OFF .
msbuild protobuf.sln /m /p:Configuration=Release /p:Platform=x64
msbuild INSTALL.vcxproj /p:Configuration=Release /p:Platform=x64注意当前Paddle2Onnx工程应该只能支持3.16.0这个版本的protobuf,高版本的protobuf安装后反而有问题。
3). 安装Paddle2ONNX
git clone https://github.com/PaddlePaddle/Paddle2ONNX.git
cd Paddle2ONNX
git submodule init
git submodule update
python setup.py install4). 使用 Paddle2ONNX 将Paddle静态图模型转换为ONNX模型格式:
paddle2onnx --model_dir .\ch_PP-OCRv3_det_infer --model_filename inference.pdmodel --params_filename inference.pdiparams --save_file .\ch_PP-OCRv3_det_infer\model.onnx --opset_version 10 --input_shape_dict="{'x':[-1,3,-1,-1]}" --enable_onnx_checker True当然,如果嫌麻烦的话,可以直接下载转换好的ONNX模型。
2. ONNX Runtime包安装
有了ONNX模型后,我们就可以部署ONNX Runtime环境了。我这里重点演示C#版本的推理程序(C#构建界面还是方便啊),C++,Python版本的参见[2]。
1). 首先,当然是下载和安装Onnx Runtime,打开 Visual Studio,创建一个PaddleOCRTestOnnx的工程,然后打开程序包管理控制台,输入以下命令:
Install-package Microsoft.ML.OnnxRuntime包管理器将自动下载和安装Microsoft.ML.OnnxRuntime包,当出现类似下述的文字时,表明包已经成功安装。
已将“Microsoft.ML.OnnxRuntime.Managed 1.17.3”成功安装到 PaddleOCRTestOnnx
执行 nuget 操作花费时间 107 毫秒同时为了方便操控图像,这里需要安装OpenCvSharp
Install-package OpenCvSharp4
Install-package OpenCvSharp4.runtime.win我们可以使用get-package来查看已经安装好的库:

注意,OpenCvSharp4.runtime.win是OpenCvSharp4的运行时,必须同步安装。否则会出现以下错误:
内部异常:
DllNotFoundException: Unable to load DLL 'OpenCvSharpExtern' or one of its dependencies: 找不到指定的模块。 (0x8007007E)3. ONNX Runtime推理流程
ONNX Runtime的推理过程非常简单,可以分为加载模型,准备输入数据,执行推理和处理输出数据四个部分,其骨干代码如下所示:
static void Main()
{
// 加载模型
var modelPath = "your_model.onnx";
var onnxModel = new InferenceSession(modelPath);
// 准备输入数据
float[] inputValues = new float[] { 1.0f, 2.0f, 3.0f, 4.0f };
var inputTensor = new DenseTensor<float>(inputValues, new int[] { 1, 4 });
// 执行推理
var inputs = new List<NamedOnnxValue>
{
NamedOnnxValue.CreateFromTensor("input", inputTensor)
};
using (var results = onnxModel.Run(inputs))
{
var outputTensor = results.First().AsTensor<float>();
float[] outputValues = outputTensor.ToArray();
// 处理输出数据
}
}4. PaddleOCR ONNX Runtime 推理适配
在使用ONNX Runtime推理时,准备输入数据和输出数据处理是大量工作所在,往往首先了解模型的工作原理,搞清模型对输入数据的要求,以及输出数据的含义。这里边包含了输入和输出张量的维度,数据是否需要归一化处理等等。
PaddleOCR包含了文字(位置)检测,文字方向判断和字符识别三个部分,分别由三个模型(网络)承担。系统从骨干网选择与调整、预测头设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用、模型自动裁剪与量化等8个方面采用19种有效策略,优化瘦身。
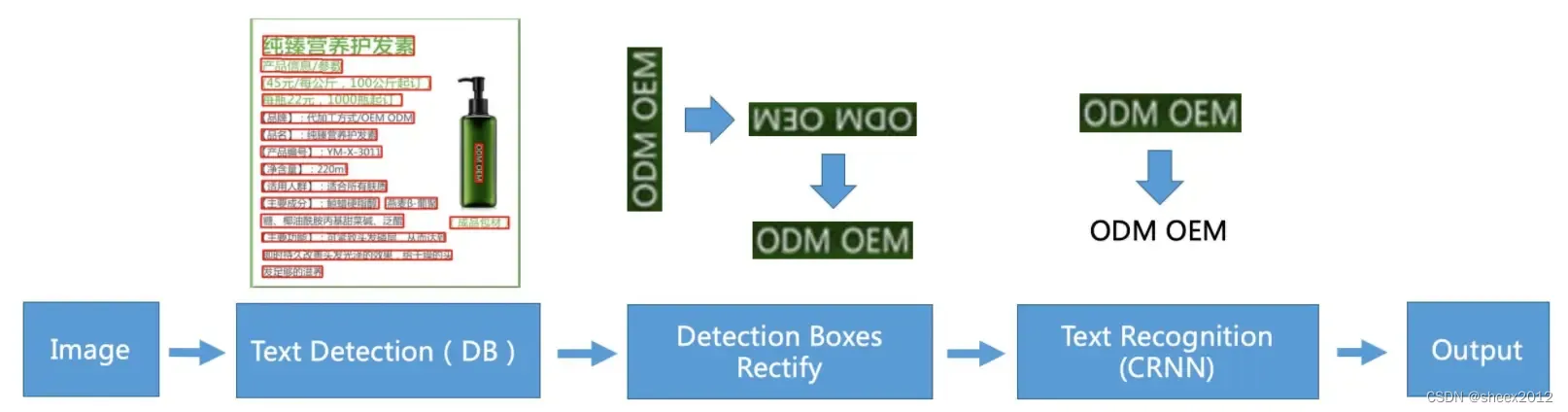
为了适配每个网络的输入和输出,我们可以通过查找官方技术文档,或者利用
NetronVisualizer for neural network, deep learning and machine learning models.![]() https://netron.app/来查看网络的输入和输出结构,然后以此适配输入和输出,下图是文本检测网络的输入和输出:
https://netron.app/来查看网络的输入和输出结构,然后以此适配输入和输出,下图是文本检测网络的输入和输出:
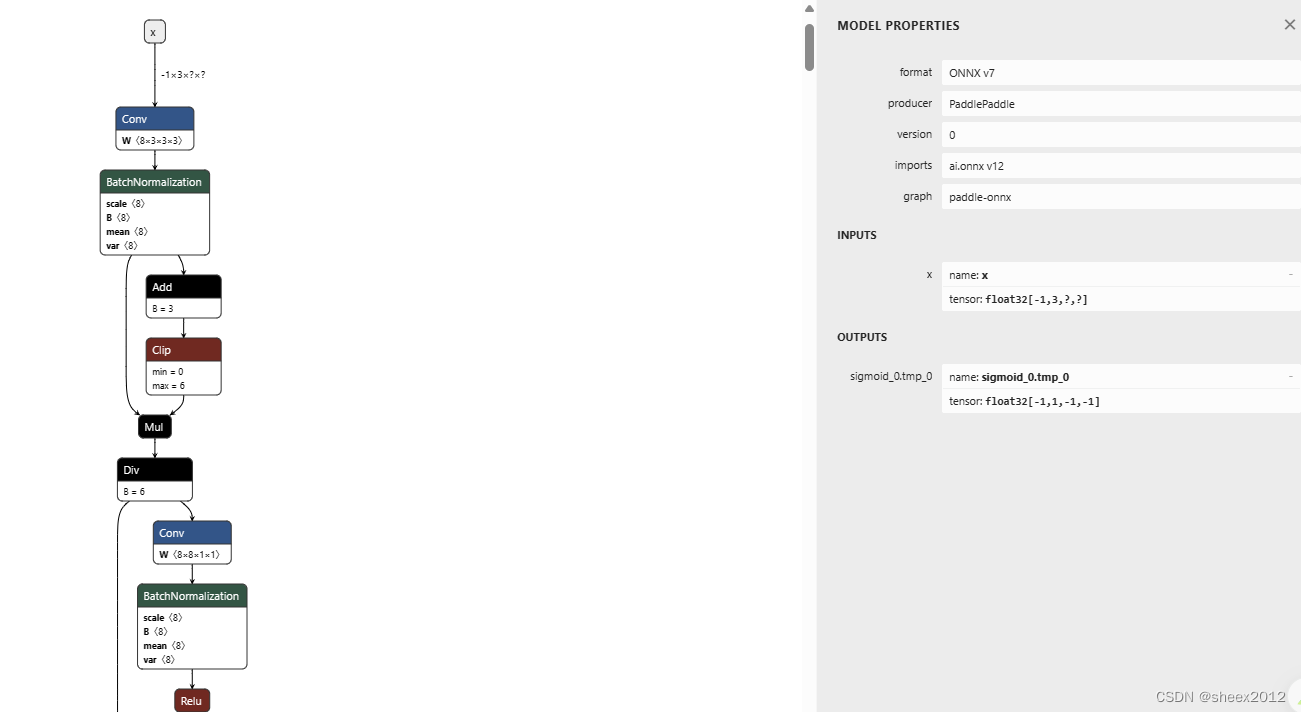
Input
name: x
tensor: float32[-1,3,?,?]
Output
name: sigmoid_0.tmp_0
tensor: float32[-1,1,-1,-1]4.1 输入适配
首先打开图像文件,转换为RGB形式,根据事先设定的比例要求重新设置宽度和高度,然后将0-255的值归一化为0-1之间的浮点数,最后构建输入张量。
//1. 打开图像,并转换为RGB形式
Mat srcImg = Cv2.ImRead(textBoxImageFile.Text);
Cv2.CvtColor(srcImg, srcImg, ColorConversionCodes.BGR2RGB);
//2. 图像大小适配
int h = srcImg.Rows;
int w = srcImg.Cols;
float scaleH = 1;
float scaleW = 1;
if (h < w)
{
scaleH = (float)this.shortSize / (float)h;
float tarW = (float)w * scaleH;
tarW = tarW - (int)tarW % 32;
tarW = Math.Max((float)32, tarW);
scaleW = tarW / (float)w;
}
else
{
scaleW = (float)this.shortSize / (float)w;
float tarH = (float)h * scaleW;
tarH = tarH - (int)tarH % 32;
tarH = Math.Max((float)32, tarH);
scaleH = tarH / (float)h;
}
Cv2.Resize(dstImg, dstImg, new OpenCvSharp.Size((int)(scaleW * dstImg.Cols), (int)(scaleH * dstImg.Rows)), interpolation: InterpolationFlags.Linear);
//3. 像素值归一化
for (int c = 0; c < 3; c++)
{
for (int i = 0; i < row; i++)
{
for (int j = 0; j < col; j++)
{
float pix = dstImg.Get<Vec3b>(i, j)[c];
this.inputImage.Add((pix / 255.0f - this.meanValues[c]) / this.normValues[c]);
}
}
}
//4. 构建输入张量
int[] inputShape = { 1, 3, dstImg.Rows, dstImg.Cols };
var inputTensor = new DenseTensor<float>(this.inputImage.ToArray(), inputShape);
var inputs = new List<NamedOnnxValue>
{
NamedOnnxValue.CreateFromTensor(this.inputNames[0], inputTensor)
};4.2 输出解码
检测网络输出对应的是归一化图像的边界点,获取推理输出,然后利用轮廓检测等一系列方法,获得文本区域列表。
//1. 获取输出值
var floatArray = outputs[0].AsTensor<float>().ToArray();
int outputCount = 1;
foreach (var dim in outputs[0].AsTensor<float>().Dimensions)
{
outputCount *= dim;
}
//2. bitmap表示二值化矩阵
Mat binary = new Mat(dstImg.Rows, dstImg.Cols, MatType.CV_8UC1);
Mat bitmap = new Mat(dstImg.Rows, dstImg.Cols, MatType.CV_8UC1);
for (int y = 0; y < dstImg.Rows; y++)
{
for (int x = 0; x < dstImg.Cols; x++)
{
binary.Set<byte>(y, x, (byte)(255.0 * floatArray[y* dstImg.Cols+x]));
bitmap.Set<byte>(y, x, (byte)(floatArray[y * dstImg.Cols + x] > this.binaryThreshold ? 255:0));
}
}
float scaleHeight = (float)(h) / (float)(bitmap.Size(0));
float scaleWidth = (float)(w) / (float)(bitmap.Size(1));
//3. 轮廓发现
OpenCvSharp.Point[][] contours;
HierarchyIndex[] hierarchy;
Cv2.FindContours(bitmap, out contours, out hierarchy, RetrievalModes.List, ContourApproximationModes.ApproxSimple);
//4. 轮廓过滤
int numCandidate = Math.Min(contours.Length, this.maxCandidates > 0 ? this.maxCandidates : int.MaxValue);
var confidences = new List<float>();
var results = new List<List<Point2f>>();
for (int i = 0; i < numCandidate; i++)
{
var contour = contours[i];
//计算轮廓分值,并忽略分值小于设定阈值的
if (this.ContourScore(binary, contour) < this.polygonThreshold)
continue;
// Rescale
var contourScaled = new List<OpenCvSharp.Point>();
contourScaled.AddRange(contour.Select(p => new OpenCvSharp.Point((int)(p.X * scaleWidth), (int)(p.Y * scaleHeight))));
// 计算轮廓的最小外接矩形(可旋转的)
var box = Cv2.MinAreaRect(contourScaled);
float shortSide = Math.Min(box.Size.Width, box.Size.Height);
if (shortSide < this.shortSideThresh)
continue;
results.Add(polygon);
}类似地,方向分类器和字符识别网络也要根据模型输入进行适配,并对输出进行解码,这里不再一一赘述。工程代码详见:PaddleOCR-Onnx-CSharp
找了一个官方样例和程序运行结果如下图:

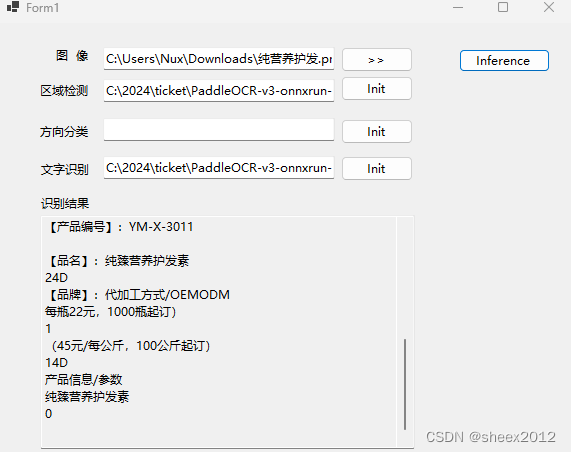
小结
将训练完成的神经网络模型转换为通用的标准ONNX格式,可以脱离原先的训练环境,在部署上带来更大的灵活性。本文以PaddleOCR ONNX模型在.NET环境下基于ONNX Runtime的推理为例,简要介绍了ONNX Runtime安装和输入适配和输出解码过程。
参考文献
2. https://github.com/PaddlePaddle/Paddle2ONNX
3. https://onnxruntime.ai/docs/
4. https://zhuanlan.zhihu.com/p/265359676
5. https://blog.csdn.net/bugang4663/article/details/131720149















 5798
5798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









