







语料链接:https://pan.baidu.com/s/1wpP4t_GSyPAD6HTsIoGPZg
提取码:jqq8
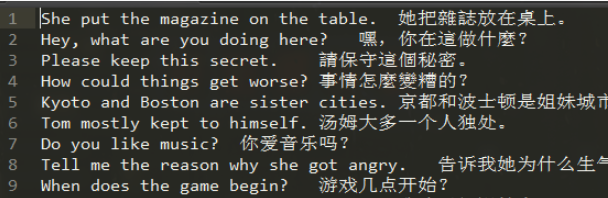
数据格式如图:
导包:
import os
import sys
import math
from collections import Counter
import numpy as np
import random
import torch
import torch.nn as nn
import torch.nn.functional as F
import nltk
nltk.download('punkt')1. 数据预处理
1.1 读入中英文数据
-
英文使用nltk的
word_tokenizer来分词,并且使用小写字母 -
中文直接使用单个汉字作为基本单元
def load_data(in_file):
cn = []
en = []
num_examples = 0
with open(in_file, 'r', encoding='utf8') as f:
for line in f:
line = line.strip().split('\t')
en.append(['BOS'] + nltk.word_tokenize(line[0].lower()) + ['EOS'])
cn.append(['BOS'] + [c for c in line[1]] + ['EOS'])
return en, cn
train_file = 'nmt/en-cn/train.txt'
dev_file = 'nmt/en-cn/dev.txt'
train_en, train_cn = load_data(train_file)
dev_en, dev_cn = load_data(dev_file)查看返回的数据内容:
print(dev_en[:2])
print(dev_cn[:2])[['BOS', 'she', 'put', 'the', 'magazine', 'on', 'the', 'table', '.', 'EOS'], ['BOS', 'hey', ',', 'what', 'are', 'you', 'doing', 'here', '?', 'EOS']]
[['BOS', '她', '把', '雜', '誌', '放', '在', '桌', '上', '。', 'EOS'], ['BOS', '嘿', ',', '你', '在', '這', '做', '什', '麼', '?', 'EOS']]
1.2 构建单词表
UNK_IDX = 0
PAD_IDX = 1
def build_dict(sentences, max_words = 50000):
word_count = Counter()
for sentence in sentences:
for word in sentence:
word_count[word] += 1
ls = word_count.most_common(max_words) # 词频前max_words个单词(降序)
total_words = len(ls) + 2
word_dict = {w[0] : index + 2 for index, w in enumerate(ls)} # {单词:索引}, w[0]:单词, w[1]:词频
word_dict['UNK'] = UNK_IDX
word_dict['PAD'] = PAD_IDX
return word_dict, total_words # total_words所有单词数, 最大50002
en_dict, en_total_words = build_dict(train_en)
cn_dict, cn_total_words = build_dict(train_cn)
inv_en_dict = {v: k for k, v in en_dict.items()} # 英文; {索引 : 单词}
inv_cn_dict = {v: k for k, v in cn_dict.items()} # 中文; {索引 : 字}1.3 把单词全部转变成数字
sort_by_len=True :是为了使得一个batch中的句子长度差不多,所以按长度排序。
def encode(en_sentences, cn_sentences, en_dict, cn_dict, sort_by_len=True):
length = len(en_sentences)
out_en_sentences = [[en_dict.get(w, 0) for w in sent] for sent in en_sentences]
out_cn_sentences = [[cn_dict.get(w, 0) for w in sent] for sent in cn_sentences]
# sort sentences by word
def len_argsort(seq):
return sorted(range(len(seq)), key=lambda x: len(seq[x]))
# 把中文和英文按照同样的顺序排序
if sort_by_len:
sorted_index = len_argsort(out_en_sentences)
out_en_sentences = [out_en_sentences[i] for i in sorted_index]
out_cn_sentences = [out_cn_sentences[i] for i in sorted_index]
return out_en_sentences, out_cn_sentences
train_en, train_cn = encode(train_en, train_cn, en_dict, cn_dict)
dev_en, dev_cn = encode(dev_en, dev_cn, en_dict, cn_dict) # [[2, 168, 201, 4, 3], [], ...., [2, 5, 14, 13, 22, 9, 149, 17, 107, 24, 121, 16, 20, 267, 7, 181, 23, 15, 6, 422, 25, 220, 4, 3]]查看返回的数据内容:
print(train_cn[2])
print([inv_cn_dict[i] for i in train_cn[2]])
print([inv_en_dict[i] for i in train_en[2]])[2, 982, 2028, 8, 4, 3]
['BOS', '祝', '贺', '你', '。', 'EOS']
['BOS', 'congratulations', '!', 'EOS']
1.4 把全部句子分成batch
# 函数返回:一个minibatch,每个句子的索引, [[11, 4, 3, 5], [16, 7, 5, 7], ...]]
def get_minibatches(n, minibatch_size, shuffle=True): # n是传进来的句子数
idx_list = np.arange(0, n, minibatch_size) # [0, 1, ..., n-1] 按minibatch_size大小分割
if shuffle:
np.random.shuffle(idx_list)
minibatches = []
for idx in idx_list:
minibatches.append(np.arange(idx, min(idx + minibatch_size, n)))
return minibatches查看上面函数的功能:
get_minibatches(100, 15)[array([90, 91, 92, 93, 94, 95, 96, 97, 98, 99]),
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]),
array([60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74]),
array([15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]),
array([30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44]),
array([75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89]),
array([45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59])]
# seqs传入的是minibatches中的一个minibatch对应的batch_size个句子索引(嵌套列表),此处batch_size=64
def prepare_data(seqs):
lengths = [len(seq) for seq in seqs]
n_samples = len(seqs) # n_samples个句子
max_len = np.max(lengths) # batch_size个句子中最长句子长度
x = np.zeros((n_samples, max_len)).astype('int32')
x_lengths = np.array(lengths).astype('int32') # batch中原始句子长度
for idx, seq in enumerate(seqs):
x[idx, :lengths[idx]] = seq # lengths[idx]: 每个句子的索引, 长度不够补0
return x, x_lengths
def gen_examples(en_sentences, cn_sentences, batch_size):
minibatches = get_minibatches(len(en_sentences), batch_size)
all_ex = []
for minibatch in minibatches:
mb_en_sentences = [en_sentences[t] for t in minibatch] # 一个batch中每个句子的对应编码,[[[2, 982, 8], [14,5,6],...]
mb_cn_sentences = [cn_sentences[t] for t in minibatch]
mb_x, mb_x_len = prepare_data(mb_en_sentences) # 一个batch中每个句子的对应编码,长度不够补0; 一个batch中每个句子长度
mb_y, mb_y_len = prepare_data(mb_cn_sentences)
all_ex.append((mb_x, mb_x_len, mb_y, mb_y_len))
# 返回内容依次是 n / batch_size 个 (batch个句子编码,batch个英文句子长度,batch个中文句子编码,batch个中文句子长度)
return all_ex
batch_size = 64
train_data = gen_examples(train_en, train_cn, batch_size)
dev_data = gen_examples(dev_en, dev_cn, batch_size)2. Encoder Decoder模型(没有Attention版本)
2.1 定义计算损失的函数
# masked cross entropy loss
class LanguageModelCriterion(nn.Module):
def __init__(self):
super(LanguageModelCriterion, self).__init__()
def forward(self, input, target, mask):
# input: [64, 12, 3195] target: [64, 12] mask: [64, 12]
# input: (batch_size * seq_len) * vocab_size
input = input.contiguous().view(-1, input.size(2))
# target: batch_size * seq_len
target = target.contiguous().view(-1, 1)
mask = mask.contiguous().view(-1, 1)
output = -input.gather(1, target) * mask # 将input在1维,把target当索引进行取值
#这里算得就是交叉熵损失,前面已经算了F.log_softmax
#output.shape=torch.Size([768, 1])
#因为input.gather时,target为0的地方不是零了,mask作用是把padding为0的地方重置为零,
#因为在volab里0代表的也是一个单词,但是我们这里target尾部的0代表的不是单词
output = torch.sum(output) / torch.sum(mask)
# 均值损失,output前已经加了负号,所以这里还是最小化
return output2.2 Encoder部分
Encoder模型的任务是把输入文字传入embedding层和GRU层,转换成一些hidden states作为后续的context vectors;
对 nn.utils.rnn.pack_padded_sequence 和 nn.utils.rnn.pad_packed_sequence 的理解:http://www.mamicode.com/info-detail-2493083.html
class PlainEncoder(nn.Module):
def __init__(self, vocab_size, hidden_size, dropout=0.2): # 假设embedding_size=hidden_size
super(PlainEncoder, self).__init__()
self.embed = nn.Embedding(vocab_size, hidden_size)
self.rnn = nn.GRU(hidden_size, hidden_size, batch_first=True) # batch_first=True: [batch_size, seq_len, hidden_size]
self.dropout = nn.Dropout(dropout)
# x: 一个batch的每个句子的编码
# lengths: 每个句子的原始编码长度(未补0的长度)
# 最后一个hidden_state要取出来作为context vector,所以需要lengths
def forward(self, x, lengths):
# (排序好元素,排序好元素下标)
sorted_len, sorted_idx = lengths.sort(0, descending=True) # 把batch里的seq按照长度降序排列
x_sorted = x[sorted_idx.long()]
embedded = self.dropout(self.embed(x_sorted))
# 句子padding到一样长度的(真实句长会比padding的短)
# 为了rnn时能取到真实长度的最后状态,先pack_padded_sequence进行处理
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, sorted_len.long().cpu().data.numpy(),
batch_first=True)
# out:[batch, seq_len, hidden_zize]
# hidden: [num_layers=1, batch, hidden_size]
packed_out, hidden = self.rnn(packed_embedded)
out, _ = nn.utils.rnn.pad_packed_sequence(packed_out, batch_first=True) # 回到padding长度
_, original_idx = sorted_idx.sort(0, descending=False) # 排序回原来的样子
out = out[original_idx.long()].contiguous() # [batch_size, seq_len, hidden_size]
hidden = hidden[:, original_idx.long()].contiguous() # [num_layers, batch_size, hidden_size]
# print("out.shape: ", out.shape, 'hidden.shape: ', hidden.shape)
return out, hidden[[-1]] # hidden[[-1]], 相当于out[:, -1]测试一下:(可注释掉)
# 测试维度
p = PlainEncoder(en_total_words, 100)
mb_x = torch.from_numpy(train_data[0][0]).long()
mb_x_len = torch.from_numpy(train_data[0][1]).long()
print("数据集:", mb_x.shape, mb_x_len.shape)
o, h = p(mb_x, mb_x_len)
print(o.shape, h.shape)
print(o[:, -1].shape, '\n', o[:, -1] == h)数据集: torch.Size([64, 14]) torch.Size([64])
out.shape: torch.Size([64, 14, 100]) hidden.shape: torch.Size([1, 64, 100])
torch.Size([64, 14, 100]) torch.Size([1, 64, 100])
torch.Size([64, 100])
tensor([[[True, True, True, ..., True, True, True],
[True, True, True, ..., True, True, True],
[True, True, True, ..., True, True, True],
...,
[True, True, True, ..., True, True, True],
[True, True, True, ..., True, True, True],
[True, True, True, ..., True, True, True]]])
2.3 Decoder部分
Decoder会根据已经翻译的句子内容和context vectors,来决定下一个输出的单词;
class PlainDecoder(nn.Module):
def __init__(self, vocab_size, hidden_size, dropout=0.2):
super(PlainDecoder, self).__init__()
self.embed = nn.Embedding(vocab_size, hidden_size)
self.rnn = nn.GRU(hidden_size, hidden_size, batch_first=True) # [batch_size, seq_len, hidden_size]
self.fc = nn.Linear(hidden_size, vocab_size)
self.dropout = nn.Dropout(dropout)
# 和PlainEncoder的forward过程大致差不多,区别在于hidden_state不是0而是传入的
# y:一个batch的每个中文句子编码
# hid: hidden_state, context vectors
def forward(self, y, y_lengths, hid):
sorted_len, sorted_idx = y_lengths.sort(0, descending=True)
y_sorted = y[sorted_idx.long()]
hid = hid[:, sorted_idx.long()]
# [batch_size, y_lengths, embed_size=hidden_size]
y_sorted = self.dropout(self.embed(y_sorted))
packed_seq = nn.utils.rnn.pack_padded_sequence(y_sorted, sorted_len.long().cpu().data.numpy(),
batch_first=True)
out, hid = self.rnn(packed_seq, hid)
unpacked, _ = nn.utils.rnn.pad_packed_sequence(out, batch_first=True)
_, original_idx = sorted_idx.sort(0, descending=False) # 原来的索引升序
output_seq = unpacked[original_idx.long()].contiguous() # [batch_size, y_length, hidden_size]
hid = hid[:, original_idx.long()].contiguous() # [1, batch_size, hidden_size]
output = F.log_softmax(self.fc(output_seq), -1) # [batch_size, y_lengths, vocab_size]
return output, hid2.4 构建Seq2Seq模型
构建Seq2Seq模型把encoder, attention, decoder串到一起;
class PlainSeq2Seq(nn.Module):
def __init__(self, encoder, decoder):
super(PlainSeq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, x, x_lengths, y, y_lengths):
encoder_cut, hid = self.encoder(x, x_lengths)
output, hid = self.decoder(y, y_lengths, hid)
return output, None
def translate(self, x, x_lengths, y, max_length=10):
encoder_cut, hid = self.encoder(x, x_lengths)
preds = []
batch_size & 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2468
2468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









