



模拟散列表的实现
散列表是一种高效的数据结构,常用于快速插入和查询操作。它通过哈希函数将数据映射到固定大小的数组中,从而减少搜索时间。但在映射过程中,不同数据可能映射到同一位置,称为冲突。这一部分将介绍两种冲突处理方法:拉链法和开放寻址法,并基于C++实现一个模拟散列表。
哈希函数与冲突
哈希函数的作用是将范围大的数据映射到小范围数组中。通常使用模运算: k = ( x % N + N ) % N k = (x \% N + N) \% N k=(x%N+N)%N,其中 N N N是数组大小。选择 N N N为质数且远离2的整数幂(如100003或200003),可减少冲突概率。冲突指不同数据映射到同一位置,需通过特定方法处理。
冲突处理方法一:拉链法
拉链法通过链表处理冲突。数组每个位置存储一个链表头指针,冲突数据被链接到同一位置。
原理:
- 初始化数组 h h h,每个元素初始化为-1(表示空链表)。
- 插入时计算哈希值 k k k,将数据插入链表头。
- 查询时遍历链表查找数据。
代码实现:
#include <iostream>
#include <cstring> // memset函数
using namespace std;
const int N = 100003; // 取质数,远离2的幂
int n;
int e[N], ne[N], idx; // 链表:e存储值,ne存储下一个索引,idx当前索引
int h[N]; // 哈希表数组,存储链表头索引
// 插入操作
void insert(int x)
{
int k = (x % N + N) % N; // 处理负数,确保k为正
e[idx] = x;
ne[idx] = h[k]; // 新节点指向原头节点
h[k] = idx; // 更新头节点为新节点
idx++;
}
// 查询操作
bool find(int x)
{
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i])
{
if (e[i] == x) return true; // 找到数据
}
return false; // 未找到
}
int main()
{
scanf("%d", &n);
memset(h, -1, sizeof(h)); // 初始化链表头为-1
char op[2];
int x;
while (n--)
{
scanf("%s%d", op, &x);
if (op[0] == 'I') insert(x);
else
{
if (find(x)) printf("Yes\n");
else printf("No\n");
}
}
return 0;
}
解释:
- 初始化:
memset(h, -1, sizeof(h))将 h h h数组每个元素设为 − 1 -1 −1,表示空链表。 - 插入:计算 k k k后,将数据添加到链表头,时间复杂度 O ( 1 ) O(1) O(1)。
- 查询:遍历链表查找,平均时间复杂度 O ( 1 ) O(1) O(1),最坏 O ( n ) O(n) O(n)。
冲突处理方法二:开放寻址法
开放寻址法通过线性探测处理冲突。数组大小通常为数据量的2~3倍,冲突时顺序查找下一个空位。
原理:
- 初始化数组
h
h
h,每个元素初始化为
null(如0x3f3f3f3f)。 - 插入时计算 k k k,如果位置被占,则向后查找空位。
- 查询时同样从 k k k开始查找,直到找到数据或空位。
代码实现:
#include <iostream>
#include <cstring> // memset函数
using namespace std;
const int N = 200003; // 取数据量2~3倍的质数
const int null = 0x3f3f3f3f; // 空位标记
int n;
int h[N]; // 哈希表数组
// 插入操作
void insert(int x)
{
int k = (x % N + N) % N;
while (h[k] != null)
{ // 如果位置被占,向后查找
k++;
if (k == N) k = 0; // 循环到数组开头
}
h[k] = x; // 找到空位插入
}
// 查询操作:返回可插入下标或数据下标
int find(int x)
{
int k = (x % N + N) % N;
while (h[k] != null && h[k] != x)
{ // 非空且非目标数据,继续查找
k++;
if (k == N) k = 0;
}
return k; // 返回下标
}
int main()
{
scanf("%d", &n);
memset(h, 0x3f, sizeof(h)); // 初始化所有位置为null
char op[2];
int x;
while (n--)
{
scanf("%s%d", op, &x);
if (op[0] == 'I') insert(x);
else
{
int pos = find(x);
if (h[pos] == x) printf("Yes\n");
else printf("No\n");
}
}
return 0;
}
解释:
- 初始化:
memset(h, 0x3f, sizeof(h))将 h h h数组每个元素设为null。 - 插入:线性探测查找空位,时间复杂度平均 O ( 1 ) O(1) O(1)。
- 查询:
find函数返回下标,如果 h [ pos ] = = x h[\text{pos}] == x h[pos]==x则数据存在。
比较与总结
- 拉链法:空间效率高,适合冲突较少场景;实现简单,但需额外链表空间。
- 开放寻址法:空间开销大(数组需2~3倍大小),但查询速度快;适合数据量稳定时。
- 两种方法均能高效处理插入和查询操作,时间复杂度平均 O ( 1 ) O(1) O(1)。实际应用中,选择取决于数据特性和内存约束。
通过以上实现,散列表可支持大量操作,是算法设计中重要工具。代码中使用 N N N为质数且远离2的幂,能有效减少冲突,提升性能。
字符串哈希:高效比较子串的利器
问题背景
在字符串处理中,经常需要比较两个子串是否完全相同。如果每次比较都逐字符检查,时间复杂度为 O ( n ) O(n) O(n),在多次查询的场景下效率低下。字符串哈希技术通过预处理字符串,使得每次查询能在 O ( 1 ) O(1) O(1)时间内完成,极大提升效率。
算法原理
核心思想
将字符串视为一个 P P P进制数( P P P为经验质数,如131或13331),通过计算其哈希值实现快速比较。具体步骤包括:
- 预处理前缀哈希数组 h [ ] h[ ] h[]
- 预处理幂数组 p [ ] p[ ] p[](存储 P k P^k Pk)
- 通过数学推导计算子串哈希值
哈希计算公式
- 前缀哈希: h [ i ] = h [ i − 1 ] × P + s t r [ i ] h[i] = h[i-1] \times P + str[i] h[i]=h[i−1]×P+str[i]
- 子串哈希(区间
[
l
,
r
]
[l,r]
[l,r]):
H ( l , r ) = h [ r ] − h [ l − 1 ] × p r − l + 1 H(l,r) = h[r] - h[l-1] \times p^{r-l+1} H(l,r)=h[r]−h[l−1]×pr−l+1
公式推导:
设子串 S [ l . . r ] S[l..r] S[l..r]的哈希值需去掉前缀 [ 1.. l − 1 ] [1..l-1] [1..l−1]的影响。求 [ l , r ] [l, r] [l,r]之间字串的哈希值,相当于是求 h [ r ] h[r] h[r]的低 r − l + 1 r-l+1 r−l+1位的值,我们就用 h [ r ] h[r] h[r]减去他的高 l − 1 l-1 l−1位,高 l − 1 l-1 l−1位可以用 h [ l − 1 ] h[l-1] h[l−1]计算。由于 h [ l − 1 ] h[l-1] h[l−1]已包含前 l − 1 l-1 l−1位的 P P P进制值,将其乘以 P r − l + 1 P^{r-l+1} Pr−l+1(相当于左移对齐),再从 h [ r ] h[r] h[r]中减去即可得到目标子串的独立哈希值。
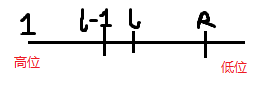
关键细节
-
进制基底 P P P
需满足 P > 字符集大小 P > \text{字符集大小} P>字符集大小(例如ASCII字符集选 P = 131 P=131 P=131),避免哈希冲突。 -
自然溢出处理
使用unsigned long long自动对 2 64 2^{64} 264取模,兼顾效率与正确性。 -
字符映射
直接使用ASCII码值(无需显式映射),但需确保字符不为0(避免前导零问题)。
代码实现
#include <iostream>
using namespace std;
typedef unsigned long long ULL;
const int N = 1e5 + 10, P = 131; // P为经验质数
int n, m;
char str[N];
ULL h[N], p[N]; // h[]存储前缀哈希,p[]存储P的幂次
// 计算子串[l, r]的哈希值
ULL get_hash(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
int main()
{
scanf("%d%d%s", &n, &m, str + 1);
// 初始化幂数组和哈希数组
p[0] = 1;
for (int i = 1; i <= n; i++)
{
p[i] = p[i - 1] * P;
h[i] = h[i - 1] * P + str[i]; // 利用ASCII值计算
}
while (m--)
{
int l1, r1, l2, r2;
scanf("%d%d%d%d", &l1, &r1, &l2, &r2);
ULL h1 = get_hash(l1, r1);
ULL h2 = get_hash(l2, r2);
puts(h1 == h2 ? "Yes" : "No");
}
return 0;
}
复杂度分析
- 时间复杂度
预处理: O ( n ) O(n) O(n)
单次查询: O ( 1 ) O(1) O(1) - 空间复杂度
O ( n ) O(n) O(n)(存储前缀哈希和幂次数组)
示例验证
输入
8 3
ABCDABC
1 3 6 8
1 2 3 4
1 3 2 4
输出
Yes // "ABC" vs "ABC"
No // "AB" vs "CD"
No // "ABC" vs "BCD"
应用场景
- 字符串匹配(Rabin-Karp算法)
- 最长回文子串(Manacher替代方案)
- 最长公共子串(二分+哈希)
注意:虽然冲突概率极低( 1 2 64 \frac{1}{2^{64}} 2641),在严格场景可结合双哈希进一步降低风险。
算法内容来自AcWing算法基础课,感谢AcWing老师的详细讲解。

















 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









