






经过深入调研并且收集了系统相关的资料,提出了系统的建设目标和主要功能,包括图书管理、读书会管理、图书分类推荐(包括科技图书、人文图书、历史图书、中小学图书和其他图书)。在系统建设中,选用了基于机器学习的协同过滤算法进行推荐,前端使用HTML、CSS等技术实现,后端选用基于SpringMVC的框架实现,协同过滤算法的基本思路是先获取图书的基本特征信息,然后根据用户点击的行为记录用户的喜好,最后计算用户喜好的图书和其他图书之间的距离,将距离最近的图书给用户推荐。经过验证,系统满足最初的建设要求,可以给广大读者提供图书个性化推荐服务。
本人专注于软件开发,可以助你升学、就业、深造,我会定期发布对应的软件设计和内容,大家如果有开发需求,可以私信联系、评论,我看到一定就回。
资源链接
论文链接
系统源码链接
第1章 绪 论
1.1背景
随着人民受教育程度提高以及我国经济的高速发展,人们对于精神文化生活的追求也越来越高。数字化时代的到来,书籍作为人类进步的阶梯,也实现了数字化,越来越多的人在电子设备上进行阅读,为了提升大家对知识获取的便捷性,可以构建基于信息化平台的知识分享和知识阅读平台,满足大家的精神文化需求。
据《第十九届中国互联网大会》的报告,中国移动互联网发展速度迅猛,我国移动端网民超过12亿,占据全球移动网名的近三分之一。为了满足移动互联网的发展需求,使得人们可以随时随地进行阅读从而获取知识,可以基于互联网构建在线阅读平台,满足移动在线阅读的诉求。
在此背景下,本文提出了基于机器学习的图书推荐系统,通过系统建设,可以为广大读者提供一个图书推荐平台,基于读者的个性化需求依据机器学习算法推荐图书,节省读者甄别图书的时间,更好服务广大读者。
1.2国内外研究现状
国外推荐算法的研究较早,基于协同过滤的算法,在国外有两个学术分支进行研究,一是基于物品进行推荐,二是基于用户进行推荐。在拥有用户对物品的偏好信息以及用户或物品本身的一些特征信息的基础上,推荐算法才能起到相应的效果。目前推荐系统中常见的推荐算法有:Gennaro的Memory Based Collaborative Filtering with Lucene[2]中的协同过滤算法,在Lops、Gemmis、Semeraro的Content-based Recommender Systems: State of the Art and Trends[M][3]和Pazzani、Billsus的Content-Based Recommendation Systems[C][4]中的基于内容的推荐算法,在Felfernig、Gula、Leitner的Persuasion in Knowledge-Based Recommendation[J]中的基于知识的推荐算法[5],在Moreau、Pivert、Smits的A Typicality-Based Recommendation Approach Leveraging Demographic Data[J]中的基于人口统计学算法[6],在Bendakir、Andre-Aisenstadt的Using Association Rules for Course Recommendation[J][7]和Cakir、Aras的A Recommendation Engine by Using Association Rules[J][8]中的基于关联规则的推荐算法。国外有很多知识分享平台、博客、电子书等阅读平台,比如谷歌博客、汤博乐等博客分享平台,可以在这些平台查看图书,平台也支持根据用户的个性而给用户推荐不同图书。
国内相关的研究也较多。随着推荐系统的应用越来越广泛,以上的推荐算法在应用与研究的过程中得到不断的改进,例如在于阳、于洪涛、黄瑞阳的基于熵优化近邻选择的协同过滤推荐算法中利用熵来优化协同过滤中的相似度计算并使用熵来展示评价信息,通过这两种方式来共同计算推荐权重,以此提高推荐效果[9];在方耀宁、郭云龙、扈红超、兰巨龙的一种基于Sigmoid函数的改进协同过滤推荐算法中利用 sigmoid 函数分别对物品以及用户进行建模,分别得到物品在用户中的平均评价以及用户对物品的喜好程度,再依据两者的贴近程度进行预测[10];在Gong的A Collaborative Filtering Recommendation Algorithm Based on User Clustering and Item Clustering中提出了先将物品以及用户进行聚类,缩小计算用户以及物品邻居的范围,从而减少用户以及物品之间相似度计算次数,能在一定程度上降低数据的稀疏性[11]。在线阅读相关的系统设计研究成果在学术界较少,主要研究集中在算法推荐中,但是在工业界却有很多在线阅读类的产品。国内的知识分享平台和图书阅读类系统有很多,比如知乎、博客园、CSDN等平台都给用户提供了知识阅读的平台,可以在这些系统中进行阅读。相关系统中基本都支持内容推荐,可以基于用户的个性化特征推荐对应图书或者内容。
1.3论文内容组织
第一章,主要是系统的背景,还有系统相关的理论的收集,即国内外文献综述。
第二章,主要是系统中设计的相关概念和技术的基本介绍,主要介绍系统在设计和开发中设计的技术问题。
第三章,是系统的需求分析,首先分析系统的可行性,包括经济可行性、技术可行性等;然后分析系统的功能性需求,最后分析系统的非功能性需求。
第四章,主要是系统的功能设计,包括数据库设计和功能设计,其中数据库设计又包括逻辑数据库设计和物理数据库设计。
第五章,是系统的实现部分,分模块对系统进行了实现,并对实现代码进行说明。
第六章,是系统的测试部分,对每个模块进行测试,编写测试用例并执行。
最后是论文的总结,包括对全文和系统的总结,以及未来工作的展望。
第2章 算法以及关键技术
2.1协同过滤算法
在网络普及的今天,在网络上面进行内容消费是十分普遍的,而互联网上的内容提供商为了给用户提供最佳的商品,过滤掉那些用户不想看到的商品,从而提升商品或者服务的推荐成功率,从而可以提升下单成功率。个性化推荐的过程从本质上来说,是给用户过滤掉那些无用信息,提升了用户过滤无效信息和无用信息的过滤效率。互联网的商家或者电商平台在进行用户推荐的时候,有两种方法,一种是基于商品本身的销量给用户推荐,这种方式可以给用户推荐最抢手和热门的商品,由于热销商品本上的销量很高,给用户推荐可以在一定程度上满足用户的需求;但是由于热销商品并未考虑用户个人的特点,因此,给用户推荐的商品无法挖掘用户自身的内在需求。于是有了第二种推荐方法,第二种就是个性化推荐算法,利用用户的个性化行为确定用户的个性化偏好,从而给用户推荐基于用户个性化偏好的商品,可以充分满足用户的个性化需求,提升推荐质量。协同过滤算法的特点归结起来有两点,一是协同,二是过滤,协同是指利用同类用户的特点一起协作进行推荐,过滤是指把无用的物品信息剔除掉,在实际中是基于距离进行过滤,把那些距离远的的物品信息剔除掉。
个性化推荐算法框架的基本思路是推荐算法根据用户的输入产生推荐结果,然后把推荐结果展示给用户,而为了提升推荐的质量,必须动态考虑用户的行为,通过用户的行为进一步提炼用户的个性化需求,将用户的个性化行为沉淀下来并作为个性化推荐算法的输入再次使用推荐算法引擎给用户推荐内容。个性化推荐的整体框架如图2-1所示。
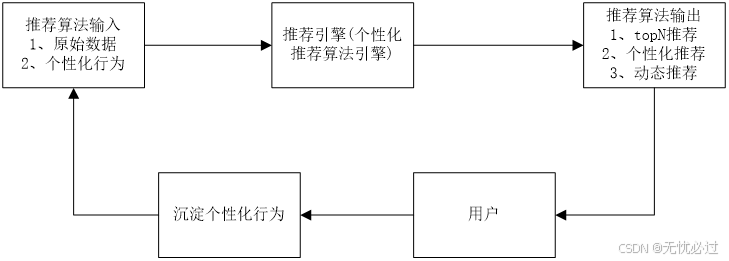
图2-1 个性化推荐框架
推荐算法的输入是指商品本身的固有属性,包括商品的名称、商品的价格、商品的销量等,根据原始商品信息可以进行推荐,这时候推荐主要是是基于商品本身进行推荐,未考虑用户的个性化需求,这一过程称之为冷启动。在给用户推荐完成之后,用户可以根据推荐内容自行对感兴趣的商品进行购买或者查看,也可以自行查找商品,这一过程会体现用户的偏好,这种偏好从用户的下单和点击来记录,将用户的个性化行为记录之后,可以根据个性化记录进行个性化行为的推演,从而确定用户的个性化行为,再利用个性化行为信息进一步进行推荐,这个时候推荐的时候,就可以充分使用已有的个性化数据来进行推荐,如此反复,不断通过用户的行为给用户推荐最适合的商品。
2.2前端开发技术
HTML和CSS是前端开发最常用的技术,HTML主要用来生成静态界面,也可以称之为界面模板,CSS则主要用来定义和规定界面的样式,也就是界面上各个部分的展现形式。在前端开发中,一般使用HTML和CSS来基本上确定界面的风格和形式,而使用JavaScript来生成交互设计和交互的体验,比如校验用户的输入,此外还可以使用JavaScript来调用后端服务,从而获取数据进行前端页面的渲染。HTML和CSS由于其使用简单,容易上手学习,而且被浏览器厂商支持,因此是前端开发中的基础知识和必备工具。任何其他前端框架和其他形式的技术也都以HTML和CSS为技术底座。
HTML当前主要有两个版本,一个是传统版本,一般称之为4,还有最新的HTML5版本,这个版本几乎被所有主流厂商接受,而已也适应于移动端开发,甚至在微信等其他技术体系内,仍然是采用基于HTML思想的WXML技术。HTML和CSS中的重要内容是盒模型,盒模型就是任何界面元素都是由一个盒子状的形式界面组成,这个界面一般是层层包裹,外层是外部留白称之为margin,然后是边界叫border,然后是内部留白为padding,最后是元素本身。基于这一基本思想,HTML又定义了很多常用的组件,包括按钮、表单、单选多选等基础组件,CSS则定义了这些基础组件的形式,比如排列形式、背景颜色、字体等,它们共同构成了丰富的前端界面,是一切前端的基础技术。
2.3系统的后端的开发技术
基于机器学习的后端可以基于经典模式MVC来实现,MVC是指视图、模型和控制三个层面的元素来组成系统框架,其主要思想是解耦,通过降低耦合度的方式来提升系统的灵活性和设计的分离性,从而可以达到这样几个目标,一是可以适应界面的动态变化,这样可以满足商业场景,因为现实世界总是不断在变化的,只有通过不断优化和美化的界面来引导和吸引用户,才容易获得商业上的成功,而前端视图的变化如果和后端的实现解耦就可以加速前端的变化速度,提升企业应变能力,提升竞争力;二是可以加强分工协作,现代企业的系统变得越来越复杂和零碎,虽然可以通过整体规划的思想使得系统在某些方面表示相对整体化一,但是由于系统复杂性的提升,一个项目还是需要很多人力的参与才能完成,小的项目需要4-8人,中等项目需要数十到上百人人,而大型项目则需要上百人乃至上千人才能完成,因此必须通过分工协作的方式来开发和运营系统,而MVC可以通过定义接口的方式使得前后端的分工明确,在定义好前后端接口规范和参数之后就可以使得前后端同时开工,并行开发,从而提升开发效率,缩短项目上线周期;第三,还可以通过控制层来控制前后端之间的斜街,而这种前后端的衔接也可能是会变动的,如果后台采用组件化的方式,就可以在控制层经过重新调整组件次序和重新组合组件而构建新的组件,这样可以加速前后端协作,提升产品适应性。
SpringMVC作为MVC的一种实现,是基于Java和Kotlin编程语言,而且官方推荐使用Kotlin语言,尽管目前国内外使用更多的项目仍然是Java项目。以Java语言为例,SpringMVC基于Java做了很多框架层面的工作,使得前后端的斜街和整个系统框架清晰、有序。前端一般可以任用流行的任意框架,而主要在Spring-MVC中配置前端视图解析器即可,而后端和前端的斜街则采用固定的Controller层进行处理,主要是基于Servlet来处理,基于封装好的HttpServletRequest和HttpServletResponse,此外还将模型嵌入到前后端的斜街组件中,使得前后端的开发模式相对规定,形成了MVC事实上的标准。
2.4关系型数据库
关系型数据库是基于二维表的一类数据库,有行和列组成,在实践中中,以第三范式为指导,在数据库的设计和开发过程中需要经历将现实世界中的模型先转换为概念模型,然后再基于概念模型生成物理模型,最终建库实现。
MySQL是一个基于关系型数据库实现的数据库,有着开源、稳定、易扩充、灵活等特点,适合关系型业务场景,本文的图书推荐平台适合使用关系型数据库进行数据存储。
2.5本章小结
本章主要介绍了开发系统相关的知识,一是系统开发的软硬件资源,二是系统中开发使用的技术,相关的技术,首先介绍了系统中使用的机器学习算法中的协同过滤算法,然后介绍了开发技术,包括前端技术和后端技术。
第3章 需求分析
需求分析是需求分析对软件设计来说非常重要,是系统设计的初衷。当系统完成开发和测试工作之后,还需要将系统功能和需求分析进行核对,确保需求中的所有功能都得到完成。如果在需求分析过程中未能正确分析出系统用户的需求,那么就可能会导致程序开发进度就会收到影响,甚至直接导致项目无法进行。
3.1可行性分析
3.1.1经济可行性
可行性分析是指系统建设的可行性,即在当前的环境约束之下,在目前所拥有的的资源的情况下,系统是否可以建设或者投资,使得从衡量角度来讲其具有可行性。
经济方面,主要的投入包括软件和硬件投入。软件投入方面,系统设计过程中所需要的Java开发工具IDEA以及MySQL数据库是开源免费的,后端框架工具、jar包也可以找到免费的开源资源,并且向下兼容。开发成员可以通过网络免费资源自学Java编程技术,数据库数据通过调查收集可免费获得。本系统开发维护过程中的工作花销较低,不会产生超额的经济代价。硬件投入需要一台PC机,在开发之前,已经投入资金采购,按月折旧价格300计算,三个月毕设的时间花费为900元。系统的收入主要来源于广告,作为一个推荐系统来说,可以通过与图书销售商的合作,作为图书销售商的流量入口而获得广告费用和引流费用,经过前期的市场调研,第一年的广告收入预计在2万元左右,第一年即可收回成本,因此,系统具有经济可行性。
3.1.2技术可行性
技术可行性是指基于当前技术发展水平和建设者拥有的技术准备来进行开发系统的可行性。本系统的建设目标是建设一套图书推荐系统,推荐系统中最重要的技术当属推荐算法,本系统选用成熟的协同过滤算法来实现,可以满足给用户依据用户的个性化喜好推荐图书。系统的实现中需要分为前端和后端两部分来实现,其中,前端选用成熟的Bootstrap、Jquery等框架来完成。后端系统选用成熟的Spring体系开发,并基于Java语言开发。整个框架选用SpringBoot和SpringMVC进行开发,SpringMVC提供了基于MVC架构的Java语言实现版本,可以完成前后端分离,降低耦合度,可以灵活支撑应用系统开发。总之,系统中的核心技术协同过滤算法具有可行性,前后台开发技术也具有可行性,因此,系统具有技术可行性。
3.1.3操作可行性
操作方面,系统应该给用户提供简洁、大方、美观的界面。在给用户展示的系统中,可以让用户不会迷路,时刻可以根据导航找到自己想要进一步访问的位置,在系统中,还要给客户提供显眼的菜单选项,可以方便客户随时随地切换菜单,满足客户个性化需求。
3.2功能性需求
本系统的主要功能是给读者提供一个可以根据读者自己的喜好推荐图书的系统,在系统中,可以借助和利用协同过滤等机器学习相关的技术来满足读者的个性化推荐,系统会随着用户的使用频率的增加,使用时间和操作的增多,可以更准确地给用户推荐依据以往喜好推荐的新图书。系统功能性需求分解之后包括如下内容,一是用户管理,二是图书管理,三是图书会管理,四是分类个性化推荐,五是系统推荐引擎。
3.2.1 用户管理
系统中的用户分为两类,一个是管理角色,一个是普通用户角色,管理角色的主要作用是在系统中完成系统配置,可以配置图书,进行图书的上线和下线等,还可以对系统图书会进行管理。
3.2.2 图书管理
系统中的图书是系统中的核心数据,因此系统中的图书管理是非常重要的。图书管理的功能包括图书团里、图书上线和图书下线。系统管理员的图书管理首先需要新建新的图书,包括输入图书的出版社、作者等信息,图书上线首先要创建图书,然后再系统中上线图书,如果图书不再销售,或者不再有版权授权,就可以将图书下线。
3.2.3图书会管理
图书会管理是指在系统中建立一个图书的组织,在这个组织内容,可以交流某一个图书的相关内容、对图书进行评价和分享,可以充分体会图书带来的阅读享受。
3.2.4 分类推荐
在读读者调研过程中,读者表达了希望可以按照分类展示的方式展示图书,这样便于他们按照某一个类别选择图书,缩小了图书搜索范围,可以提升甄别速度。在系统实现的过程中,会根据用户的阅读习惯和偏好进行推荐,这加上可以给图书进行分类,就可以更精确地给用户展示图书分类。
3.2.5 推荐引擎
系统中需要根据基于机器学习的推荐算法给用户推荐图书,在推荐的过程中,需要基于某一种具体的算法,利用这个算法根据用户的行为、习惯和偏好推荐图书,这样可以大幅提升用户过滤图书的效率,可以为用户的甄别节省时间,提升图书甄别效率。
基于协同过滤的算法是经典的一类推荐算法,其可以分为按照人分类推荐和按照物分类推荐,基于同类事物比较接近,同类人群比较类似的方法,基于人或者物之间的距离进行物品推荐。体现“物以类聚、人以群分”和“近朱者赤、近墨者黑”的中国经典哲学思想。
3.3非功能性需求分析
3.3.1性能需求
互联网时代,体验很重要,在一个商业环境中如果用户的操作体验时延很长,就很难对这个用户产生吸引力,从而导致用户失去耐心。但鉴于本文是课程设计,因此性能指标相对宽松,查询类事务可以1秒内完成,交易类事务可以2秒内完成即可。比如,在用户登录之后,在系统中可以展示图书信息,这个信息的展示需要在1秒内完成,而如果是新增一个图书,则需要录入图书信息,然后新增,这个过程需要在2秒内完成。
3.3.2安全性需求
对于该系统来说,数据就是最大的资产,如果一旦被丢失了或者是被恶意的篡改、损坏了,这将会造成不可挽回的损失。所以,加强对读者的信息保护至关重要,否则,如果造成读者信息泄露,一方面会造成系统运营重大故障,还会导致读者的投诉。另一方面,还需要备份系统数据,以免发生数据丢失的问题,数据备份一般包括定期备份和不定期备份,定期是指以一定的周期备份数据,可以作为日常运营的常规性操作保持,可以确保系统的数据不会丢失,及时丢失之后也可以恢复到某一个状态点的数据,还有一种是不定期备份,可以作为定期备份的一种补充手段进行备份。
3.4本章小结
本章分为两大部分,第一部分是系统的可行性研究,包括经济可行性、技术可行性和操作可行性等;第二部分是系统的需求分析,包括功能性需求分析和非功能需求分析,其中功能需求分析包括用户管理、图书管理、图书会管理、分类推荐和推荐引擎等;非功能性需求包括性能需求和安全性需求。
第4章 系统总体设计
系统设计是系统实现的前提,是需求分析的后续,系统设计基于需分析结果,产生系统实现的整体框架和流程,给系统实现提供蓝图。系统设计包括功能设计、性能设计、架构设计和数据库设计等,其中最重要的是系统功能设计和数据库设计。
4.1系统功能架构
系统功能主要有用户管理、图书管理、读书会管理、分类推荐和推荐引擎等。系统的最上层是展示层,这个层主要是用户使用的终端,比如个人电脑、平板灯;下面是通讯层,这一层主要是通信协议,包括HTTP协议等;下面是系统的功能服务层,这里包括了系统的所有功能,以及系统使用的框架和技术,比如SSM技术等;最下面是系统的基础设施,包括数据库和磁盘等硬件设施。系统的整体功能架构图如图4-1所示。
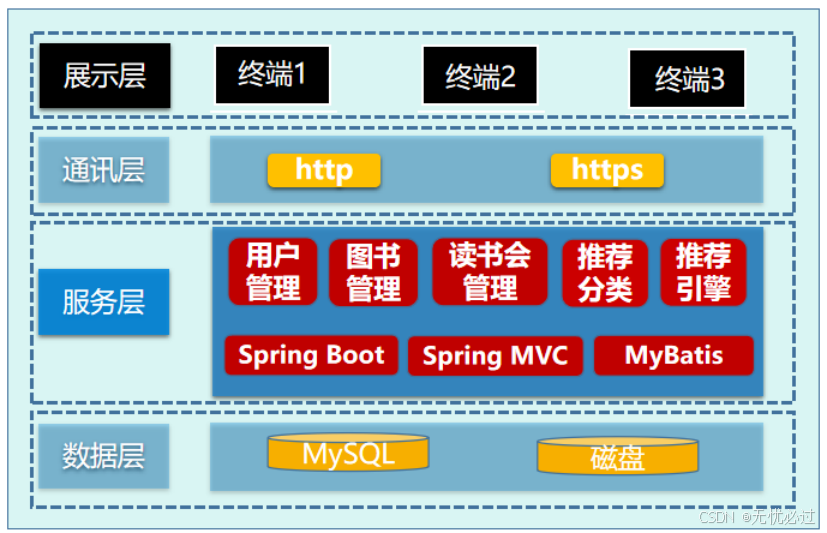
图4-1 功能架构图
4.2系统部署设计
系统的部署设计思路如下,先从互联网接入,互联网接入一般可以选择三大运营商,至少需要两个接入商,这样可以确保万一一条线路故障,可以及时切换到两一个线路。待接入互联网之后,需要在服务器一端设置防火墙、交换机和路由器等网络设备,然后通过以太网将服务器连接起来,也可以通过光纤将存储和服务器连接,如果没有单独的存储设备,则无需将存储和服务器连接。服务器一般有后台服务器、前台服务器和数据库服务器等。通过互联网将服务提供之后,用户可以通过互联网连接到服务器端,客户端支持的有各种终端设备,这些终端设备需要通过互联网或者局域网等方式接入,并和服务端进行连接。
系统部署图如图4-2所示。
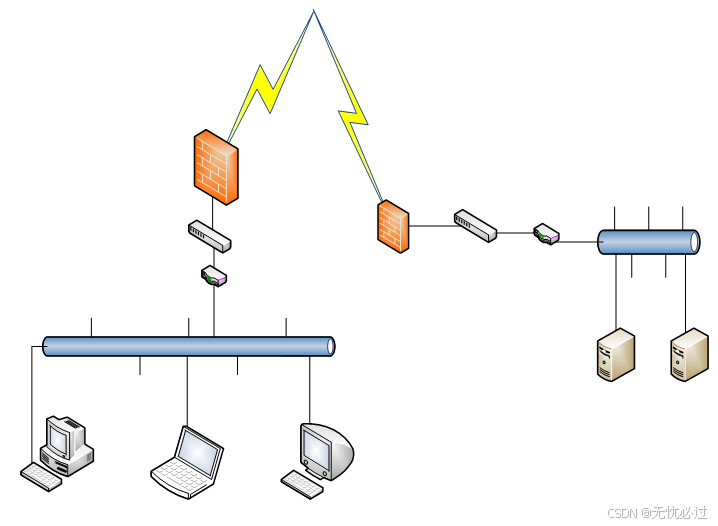
图4-2 系统部署图
4.3数据库设计
系统中的数据库设计是指根据实际的业务场景设计的数据库,数据库中需要设定一些表,并要设定表之间的关系,利用关系型数据库来进行分析。关系型数据库中一般是将所有的表采用二维表的形式去存储,一个表是由行和列组成的,行一般是指一条记录,而列就是指具体的字段。在对系统中的业务分析的过程中,确定了的系统中要创建的表包括读者表、管理员表、喜好表等、图书表、图书浏览表、读书会表等。其中读者表中记录的是读者信息,读者是系统中的重要用户,他们操作系统,查看图书;管理员表中记录的是管理员信息,他们是系统的配置者和管理者;图书表中记录的是所有的图书信息,这些信息由管理员录入,并推荐给普通读者;图书浏览表中的记录是读者浏览图书的记录,用这些信息来作为用户喜好的依据,使用算法给用户推荐;读书会表中记录的是读者发起的读书会信息,一个读书会可以有多个成员,以松散的方式形成了对一本书的爱好者进行组织;喜好表记录的是用户对某一个读书的喜好程度。
实体之间的管理包括如下一些关系,首先上述表在每个表中都需要设置一个主键以唯一区分这个表,然后表与表之间尽量通过这些主键进行管理。比如,图书表、读者表和图书浏览表有对应关系,图书浏览中引用图书表中的主键和读者表中的主键,代表某个读者阅读了某些书籍。
实体以及它们之间的关系如图4-3所示。
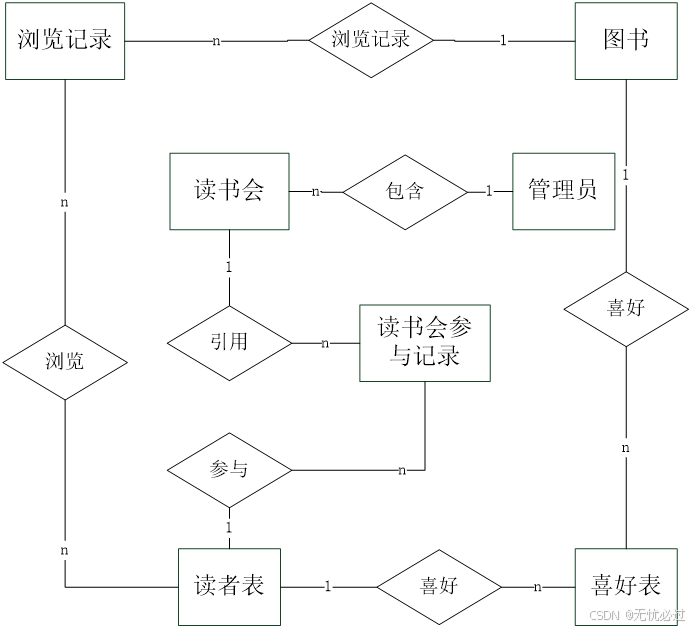
图4-3 一级实体ER图
读者表对应的实体表示如图4-4所示。
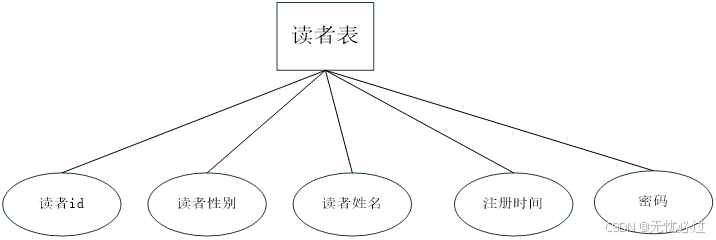
图4-4 读者表实体图
图书包括的信息有图书名称、出版社等信息,图书的实体表示如图4-5所示。
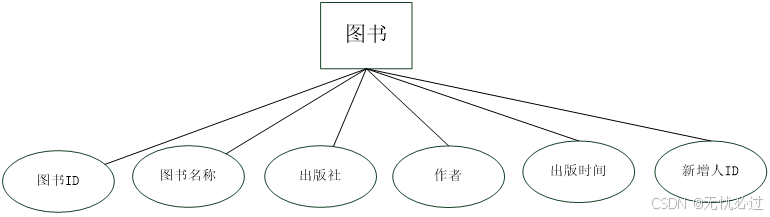
图4-5 图书实体表
读书会包括的信息包括读书会名称、成立时间等信息,读书会的实体表示如图4-6所示。
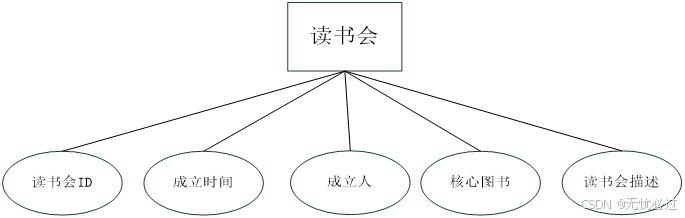
图4-6 读书会实体表示
喜好表中记录的信息包括用户和图书之间的关系,喜好的表示如图4-7所示。
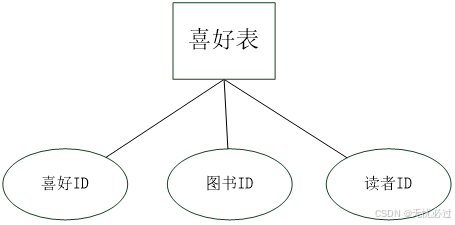
图4-7 喜好表
浏览记录中记录了用户和图书的浏览关系,是喜好表的来源,浏览记录表示如图4-8所示。
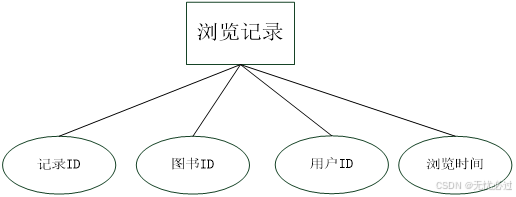
图4-8 浏览记录
整个系统的数据库表实体关系图表示如图4-9所示。
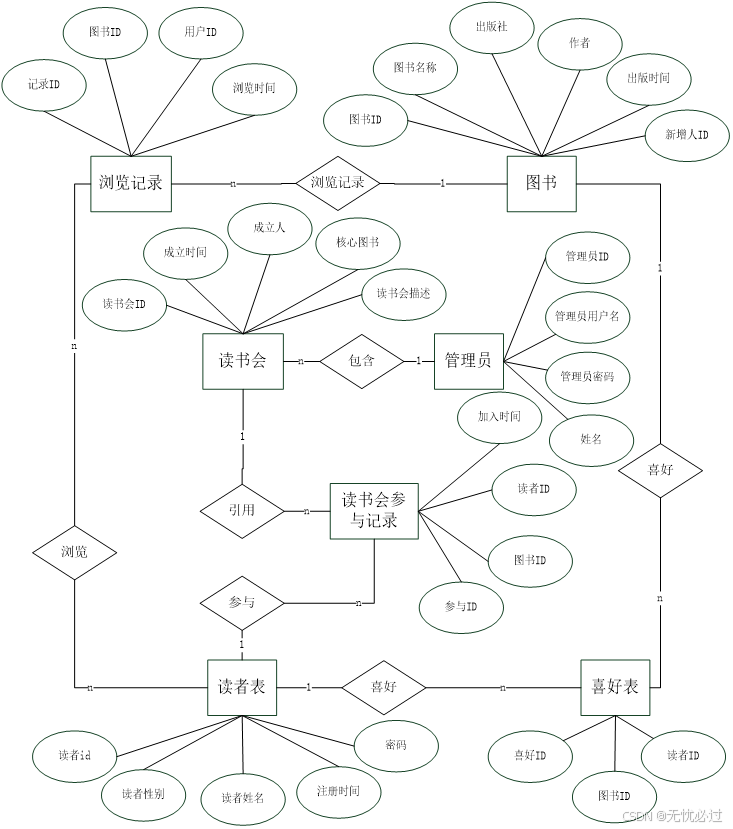
图4-9 数据库E-R图
ER图中设计的核心表如下所述。
读者表用来存放读者信息,读者是通过注册进入系统的,读者信息包括读者ID、读者姓名、读者密码等。读者表的详细信息如表4-10所示。
表4-10 读者表
图书表保存所有和图书相关的信息,是系统的核心数据。图书包括的字段有序列、名称、出版社或者版权机构、介绍等信息。图书表的具体内容如表4-11所示。
表4-11 图书表
| 序号 | 字段名称 | 数据类型 | 是否主键 | 是否为空 | 说明 |
|---|---|---|---|---|---|
| 1 | id | Int(11) | 是 | 否 | 自增,序列号 |
| 2 | user | Varchar(255) | 否 | 用户标识 | |
| 3 | type | Varchar(255) | 否 | 用户类型 | |
| 4 | name | Varchar(255) | 否 | 用户姓名 | |
| 5 | password | Varchar(255) | 否 | 用户密码 | |
| 6 | Tel | Varchar(255) | 是 | 联系方式 |
图书喜好表保存了读者对哪些图书有阅读倾向的记录,如果一个读者喜好某一个图书,则将这个读者和图书的关联关系也存储下来。图书喜好表中的关联这图书表和读者表。喜好表信息如表4-12所示。
表4-12 图书喜好表
| 序号 | 字段名称 | 数据类型 | 是否主键 | 是否为空 | 说明 |
|---|---|---|---|---|---|
| 1 | id | Int(11) | 是 | 否 | 自增,序列号 |
| 2 | userId | Varchar(255) | 否 | 用户ID | |
| 3 | NovelId | Varchar(255) | 否 | 图书ID |
读书会表中记录的是读书会的信息,每一个读书会是有一个用户根据某一个图书来创建的,一个读书会中会有一个书籍,这个书籍就是大家讨论的核心。比如爱好《红楼梦》的读者可以成立一个阅读的读书会,在读书会中可以讨论这本书的心得、感受,并将自己的想法和其他书友分享,这种书籍一般需要有一定深度,如果书籍本身的内容简单,则没有多大意义成立一个关于这种书籍的读书会。读书会信息如表4-13所示。
表4-13 读书会表
| 序号 | 字段名称 | 数据类型 | 是否主键 | 是否为空 | 说明 |
|---|---|---|---|---|---|
| 1 | id | Int(11) | 是 | 否 | 自增,序列号 |
| 2 | PartyName | Varchar(255) | 否 | 读书会名称 | |
| 3 | partyDesc | Varchar(255) | 否 | 读书会描述 | |
| 4 | BookId | Varchar(255) | 否 | 读书会书籍 |
4.4系统功能设计
4.4.1用户管理
系统中,读者要使用系统,必须先进行注册,然后才能成为系统中的用户。用户注册需要输入用户名密码等信息,如果用户名不存在就可以正常注册了,否则需要更换用户名。用户的注册流程图如图4-14所示。
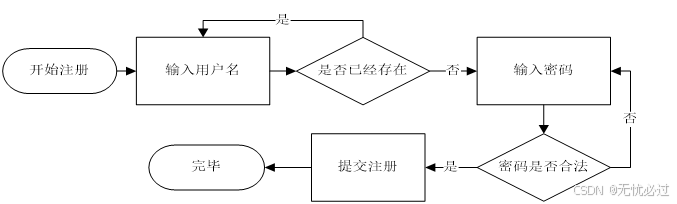
图4-14 用户注册流程
用户登录流程是:首先需要去输入一个用户名和正确的密码格式,系统它会对输入的用户名以及密码去进行校验,如果校验可以通过了,就可以正常的登录,否则就会给用户一个提示,不能正常登录,系统会将用户弹到登录界面,提示用户再次登录。
用户的登录流程图如图4-15所示。
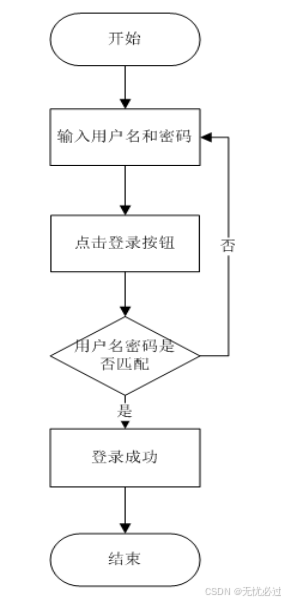
图4-15 用户登录流程
4.4.2图书管理
图书管理的过程是管理员登录,然后输入一个图书的相关信息,包括出版社、作者、书名等信息,如果确认要上架,选择上架操作,如果要下架的时候,操作下架。图书管理的过程如图4-16所示。
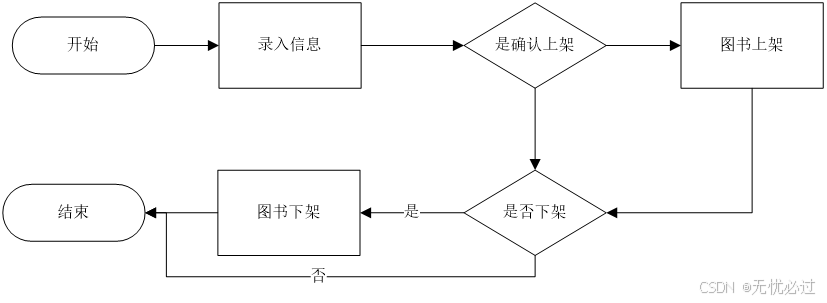
图4-16 图书管理
4.4.3读书会管理
读书会管理的流程是先由用户创建一个读书会,在创建之后,就可以让其他读者加入这个读书会了,加入之后就可以通过线下方式联系读书会会长,参与读书会的活动。
读书会管理的流程如图4-17所示。
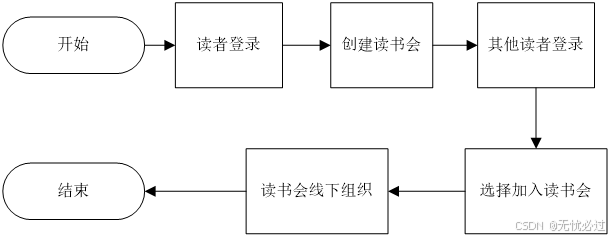
图4-17 读书会管理流程
4.4.4分类推荐
分类推荐的功能可以细分为两个功能,一是分类,二是推荐。分类功能可以根据一些统一规则分类,比如可以将图书分为历史图书、人文图书、科技图书和其他图书等。推荐是根据用户的喜好进行推荐,这里需要两个步骤来完成,一是记录用户的喜好,这可以通过记录用户的点击历史来完成,二是根据用户的喜好来给用户进行推荐,这需要使用推荐算法进行推荐,推荐算法设计是系统的核心,因此单列一节在4.4.5中介绍。记录读者浏览历史的流程如图4-18所示。
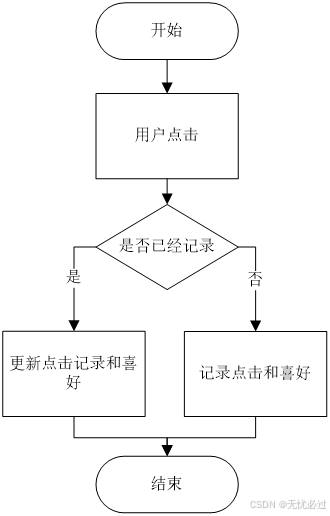
图4-18 读者点击记录
4.4.5推荐引擎
个性化推荐算法中,有很过推荐算法,比如关联规则算法推荐和协同过滤推荐。关联规则是使用购买商品的置信度等指标给用户进行推荐,主要使用的购买商品的概率进行推荐。而协同过滤算法是基于用户或者商品的特点给用户进行推荐。协同过滤推荐算法很好体现了现实生活中的两个原则,一是人以群分,二是物以类聚。一般有两种基本思路正好对应这两种方法,一是使用用户的行为进行推荐,需要计算用户之间的距离,第二是使用商品之间的关系进行推荐,需要计算商品之间的关系。而对于用户或者商品之间距离的计算,有两种方式,一种是基于远近的距离计算方式,这通常通过使用明氏距离及其变体来计算,另一种是基于方向的计算方式,这一班使用余弦计算方式来计算。
在阅读图书的经历中,一般看某一种图书的人,会更喜欢同类图书。这就是说明在图书推荐中可以依赖于图书之间的距离进行推荐。协同过滤的推荐算法的基本步骤如下。
首先,获取所有用户的信息,同时获取所用用户对图书的推荐程度,可以使用推荐和不推荐二分类法进行表示。
然后,根据用户对图书的推荐程度,生成每一个用户的共现矩阵,共现矩阵是指第i个图书和第j个图书被推荐的相似程度。通过将所有用户对第i个图书和第j个图书的推荐进行关联,从而可以获得共现矩阵。共现矩阵的计算是通过计算当前矩阵来实现的,先计算当前矩阵,然后将当前矩阵进行矩阵相加就获得了共现矩阵。计算的过程是先循环所有用户,计算每一个用户的当前矩阵,每一个用户的当前矩阵中的每一个值得表示如式4-1所示。

式4-1
而共现矩阵中的bij代表的是将所有用户的当前矩阵相加,数学表示式子如4-2式所示。
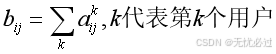
式4-2
接着,拿出要推荐用户的偏好图书,逐一循环这些图书,根据共现矩阵来计算每一个图书的距离最近的那些图书,然后根据一定规则对这些图书排序,就生成了推荐列表。
最后,将这些排好序的图书,取出前N个来进行推荐。
整个协同过滤算法设计流程图分为两步,第一步是生成贡献矩阵,流程图如图4-19所示。
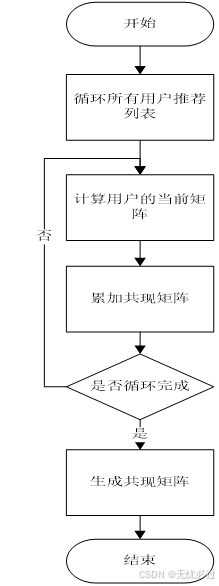
图4-19 共现矩阵生成流程
第二步是根据生成的共现矩阵,结合用户的个性化偏好,生成基于单个用户的推荐列表,并取出topN推荐。个性化推荐的流程如图4-20所示。

图4-20 个性化推荐流程
基于协同过滤的个性化推荐算法的步骤综合起来,可以形成如表4-1所示的算法步骤。
表4-1 协同过滤算法步骤
| 步 骤 | 操 作 |
|---|---|
| 1 | 清空共现矩阵; |
| 2 | 循环所有用户,取出每一个读者喜好的图书,然后循环这些图书,生成共现矩阵,生成的规则就是依据阅读i的人同时阅读j的人数进行计数,如果有人同时浏览i和j,就说明第i行第j列的共现矩阵值自增; |
| 3 | 取出当前读者阅读或者预览的的图书或者图书;根据图书生成这个图书和其他图书的距离,采用余弦公式计算wij=Nij/sqrt(Ni*Nj),将生成的图书都放入一个推荐列表,然后按照权值和喜好程度排序(权值为第一次序,喜好程度为第二次序) |
| 4 | 输出TopN的推荐列表 |
首先清空共现矩阵,然后生成物品的共现矩阵,对应伪码如下。
for(循环所有用户信息){
if(user.getUid()==uid) continue; //当前用户则跳过
likeLists = likedao.findLikesByUser(user.getUid()); //当前用户的喜欢列表
for(循环所有图书)
for(循环所有图书)
curMatrix[i][j] = 0; //清空矩阵
for(int i = 0; i < likeLists.size(); i++){
int pid1 = likeLists.get(i).getPid();
++N[pid1];
for(int j = i+1; j < likeLists.size(); j++){
int pid2 = likeLists.get(j).getPid();
++curMatrix[pid1][pid2];
++curMatrix[pid2][pid1]; //两两加一
}
}
//累加所有矩阵, 得到共现矩阵
for(int i = 0; i < papers.size(); i++){
for(int j = 0; j < papers.size(); j++){
int pid1 = papers.get(i).getPid(),
pid2 = papers.get(j).getPid();
comMatrix[pid1][pid2] += curMatrix[pid1][pid2];
comMatrix[pid1][pid2] += curMatrix[pid1][pid2];
}
}
}
推荐相关的伪代码如下所示:
for(Like like: likeLists){
int Nij = 0; //既喜欢i又喜欢j的人数
double Wij; //相似度
Paper tmp; //当前的图书
int i = like.getPid();
for(Paper paper: papers){
if(like.getPid() == paper.getPid()) continue;
int j = paper.getPid();
Nij = comMatrix[i][j];
Wij = (double)Nij/Math.sqrt(N[i]*N[j]); //计算余弦相似度
tmp = paperdao.findPaperById(paper.getPid());
tmp.setW(Wij);
if(used[tmp.getPid()]) continue;
preList.add(tmp);
used[tmp.getPid()] = true;
}
}
4.5本章小结
本章主要的工作有两个,一是数据库设计,数据库设计中首先区分了实体,然后描述了实体之间的关系,而后利用实体关系图对数据库逻辑关系进行了设计,最后对数据库的物理表进行了设计。二是对系统功能进行了设计,包括功能设计和推荐算法设计,功能设计包括用户管理、图书管理、读书会管理、分类推荐等,算法设计包括推荐引擎模块,在这一模块详细描述了推荐算法。
第5章系统详细设计
5.1系统总体类图设计
系统采用基于三层调用进行逻辑设计,第一层是业务控制层,主要负责前台和后台的交互和映射关系,即一个url如何匹配到一个后台的业务层,主要通过匹配Servlet实现;第二层是业务逻辑层,主要进行业务的流程,执行对应的业务流程,由第一层调用,业务逻辑层的设计基于组件复用原则,尽量设计高内聚的组件供上层调用;第三层是数据库连接层,主要封装了底层数据库的连接SQL,用户和数据库交互,这一层由上层第二层调用。
系统的类图按照子模块进行设计,整体类图包括用户管理、图书管理、读书会管理、分类推荐、推荐引擎各个子模块实现。整体类图如图5-1所示。
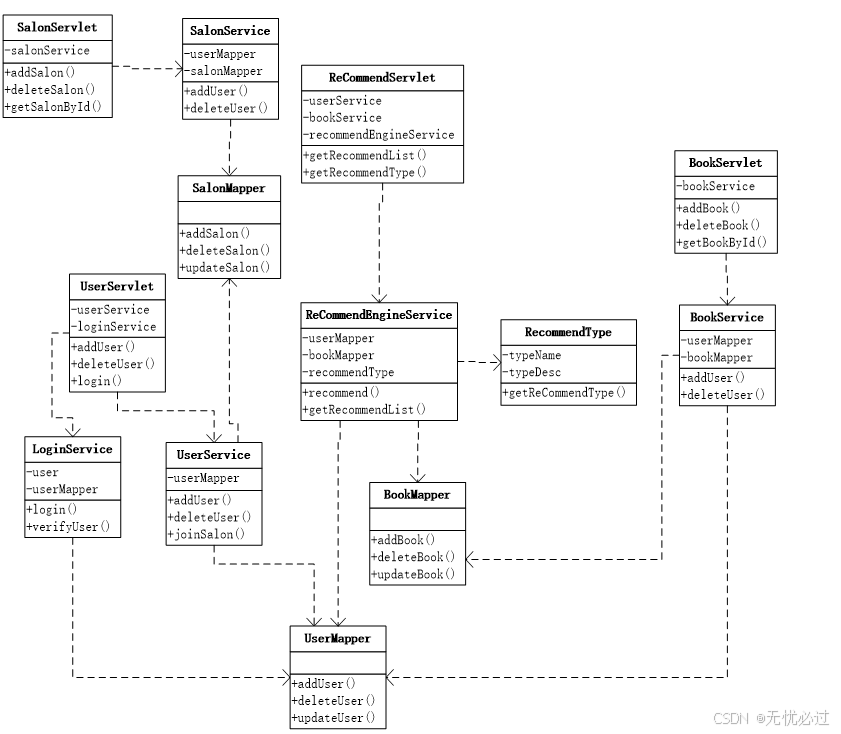
图5-1 系统整体类图
5.2分模块详细设计
5.2.1用户管理
用户管理的主要逻辑有两方面内容,一是用户的注册和删除,也即用户的新增和删除问题,还有用户的信息修改,二是用户的登录问题,登录包括用户的认证和校验问题。因此,用户管理的类分为UserManager类和UserLogin类,分布是用户的注册删除和用户的认证管理。具体类描述如图5-2所示。

图5-2 用户类设计
5.2.2图书管理
图书管理的主要功能包括有图书的新增、修改和删除等,操作的基本逻辑是分三层进行调用。图书馆里中的Service层需要调用用户的数据库操作和图书的数据库操作。图书管理的类图设计如图5-3所示。
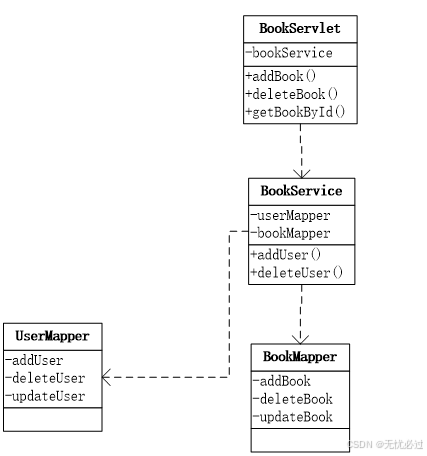
图5-3 图书管理类图
5.2.3读书会管理
读书会管理的内容包括如下一些基本功能,一是对读书会本身的管理,包括读书会的新增、删除等;二是一个用户可以加入读书会,因此,在用户管理中还需要增加加入读书会的操作。读书会管理的类仍然是按照三层设计,但是需要调用用户和读书会的Service层和Mapper层。读书会管理的类图如图5-4所示。

图5-4 读书会管理
5.2.4分类推荐
分类推荐的基本功能是根据推荐引擎的信息获取用户的推荐信息,然后在每一个分类中展示该类型的推荐信息。分类推荐的信息类指责主要是查询,通过调用推荐引擎中的推荐结果进行推荐。分类推荐的类需要和推进引擎类进行交互,对应的分类推荐的类图如图5-5所示。

图5-5 分类推荐类图
5.2.5推荐引擎
推荐引擎是系统中的核心功能,推荐引擎需要调用图书信息、用户信息等,然后根据图书和用户的信息生成推荐数据,最终产生推荐列表。推荐引擎的类图如图5-6所示。
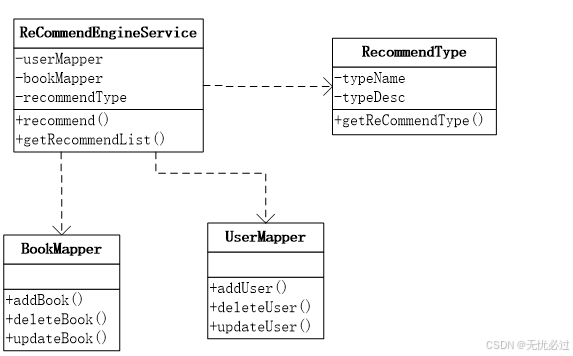
图5-6 推荐引擎类图
5.3本章小结
本章主要进行了系统的详细设计,包括系统的总体类设计和分模块的设计,分模块的设计包括用户管理模块的类设计、图书管理模块的类设计、读书会的类设计、分类推荐和推荐引擎等的类设计等。
第6章 系统的实现与测试
6.1系统实现
6.1.1用户管理
网页搭建在本机环境,后端主页面的网址是:http://localhost:8080/,打开页面,点击注册之后就进入了注册界面。
注册界面如图6-1所示:
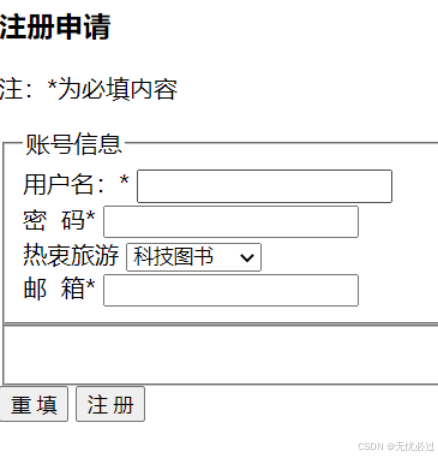
图6-1 注册界面
6.1.2图书管理
图书管理的功能包括图书上架和下架,上架的操作先要输入图书信息,然后上架。图书上架的操作如图5-3所示。
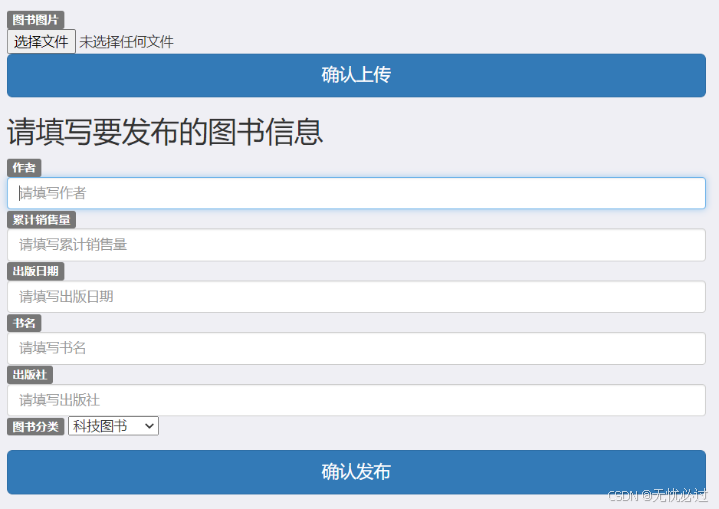
图5-3 图书上架界面
图书下架的操作是先选择要下架的图书,如果确认这本图书需要下架,则点击下架。下架的操作如图5-4所示。

图5-4 图书下架管理
图书上架和下架管理比较类似,图书上架是先录入图书信息,然后进行上架操作。
6.1.3读书会管理
读书会的管理有这么几个功能,一是读者创建一个读书会,二是其他读者加入这个读书会,三是管理员可以对违规读书会进行注销。
创建读书会的界面如图5-5所示。

图5-5 新建读书会
新成立读书会之后,其他读者可以加入到读书会中来,加入的界面操作如图5-6所示。
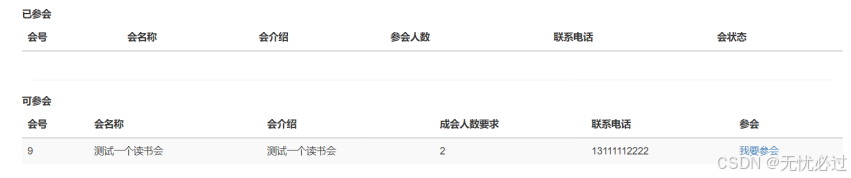
图5-6 加入读书会界面
成立了读书会之后,系统管理员就可以管理读书会,系统管理员管理的界面如图5-7所示。
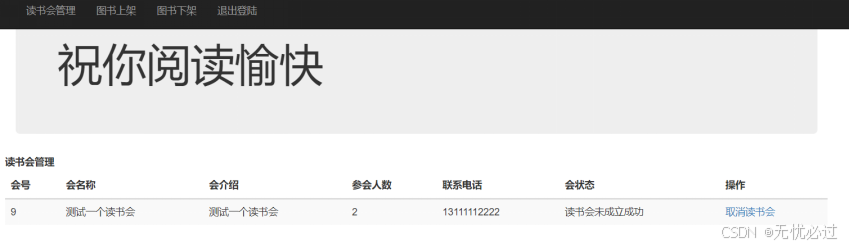
图5-7 读书会取消操作
读书会管理中的逻辑与图书管理逻辑有相似之处,都是通过展示信息,然后选择某一条数据进行操作,此次不再赘述。
6.1.4分类推荐
分类推荐是指根据图书的分类展示图书信息并进行推荐,分类的信息展示如首页所示。分类展示界面中在系统上方设置图书分类导航,方便读者点选,然后展示轮播图,增加系统的界面美化度。分类展示界面如图5-8所示。
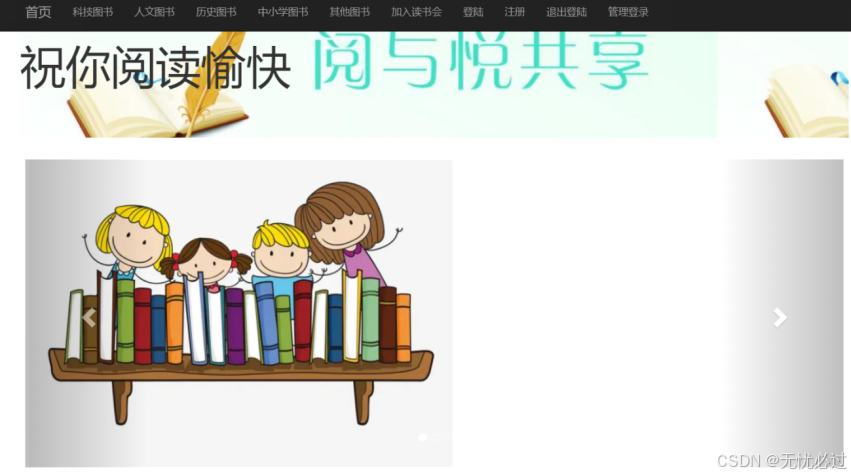
图5-6 分类展示界面
分类展示的界面在系统中使用基础组件的思想来构建,构建完成之后可以在多个页面共享。
6.1.5推荐引擎
推荐算法是系统中的重要功能,根据算法设计思路,最终对算法进行了实现,实现中使用Java编程,整体思路是两个步骤实现,第一个步骤是新建两个二维数组保存共现矩阵和当前矩阵,然后循环所有用户和所有偏好信息,最终通过当前矩阵生成共现矩阵。第二个步骤是进行预测,根据某一个用户的点击行为进行推荐,点击行为产生偏好信息,系统根据偏好信息和共现矩阵计算距离,最后推荐topN数据为推荐列表。推荐算法中,最最重要的功能是根据共现矩阵生成推荐列表。
6.2系统测试
系统测试的目的就是让系统运行流畅,保证系统没有错误或者及时发现错误并加以改正。该系统可以实现购物所需的大量功能,一个合格的系统需要运行平稳,流畅,具有开放性,易扩展,可以让顾客使用起来操作简单。要做到这些需要我们多次测试,认真分析才能完成,所以系统测试是软件开发的重要过程。
本系统的测试,主要进行功能测试,即测试系统是否满足了需求中提出的各项要求,完成了系统的所有功能。
6.2.1系统测试的概念
系统测试一般有黑盒测试和白盒测试,白盒测试一般是程序员在开发中进行的测试,也可以是测试人员尤其是内部测试人员进行的测试,可以进行覆盖测试和条件测试等多种白盒测试,以确保系统的完备性、健壮性等。而功能测试一般使用黑盒测试的方法,即测试过程中不关注系统的实现细节,仅仅测试系统是否完成了功能即可。
6.2.2单元测试
单元测试是指在开发过程中得测试,开发完毕,需要对各个子功能和模块进行测试。单元测试之前先进行代码走查和代码审查,走查一般由开发者自己完成,而代码审查由他人完成,在开发过程中采取自己进行代码走查,和其他同学交叉进行审查得方式进行。单元测设计了每一个环节,限于篇幅,摘录核心功能测试。
系统中的用户管理的单元测试的测试结果如图6-1所示。
表6-1 用户管理的单元测试
| 模块功能 | 测试过程 |
|---|---|
| 用户新增 | 测试步骤 |
| 预期 | 数据库新增了记录 |
| 结果 | 数据库新增了一条记录 |
| 结论 | 测试通过 |
| 用户登录 | 测试步骤 |
| 预期 | 验证通过 |
| 结果 | 验证通过 |
| 结论 | 测试通过 |
系统中的图书管理的单元测试的测试结果如图6-2所示。
表6-2 图书管理的单元测试
| 模块功能 | 测试过程 |
|---|---|
| 新增图书 | 测试步骤 |
| 预期 | 数据库新增了记录 |
| 结果 | 数据库新增了一条记录 |
| 结论 | 测试通过 |
| 图书删除 | 测试步骤 |
| 预期 | 数据库图书信息被删除 |
| 结果 | 数据库图书信息被删除 |
| 结论 | 测试通过 |
6.2.3系统其他测试
略
6.3本章小结
本章内容包括系统的实现和测试。第一部分是系统的实现过程,主要完成了用户管理、图书管理、读书会管理、分类推荐和推荐引擎等模块,并展示部分前端代码和后端代码,完成了系统的各个子模块的开发工作。
第二部分介绍了系统测试的基本概念,介绍了测试的基本理论,包括黑盒测试和白盒测试等,然后针对系统中的主要功能设置了测试用例,通过执行测试用例,验证了系统的可用性,经过测试,验证了系统达到了建设之初的目标。
7总结与展望
7.1总结
本文设计了基于机器学习算法的图书推荐系统,可以基于协同过滤算法给读者推荐图书。系统的设计分为两个角色,一个是管理员,一个是普通读者,管理员的功能有图书管理、读书会管理等,读者的功能包括浏览图书信息、注册、登录、阅读图书的试读部分(可以通过图书图片上传)、成立读书会和加入读书会等功能。整个推荐系统是基于机器学习中的协同过滤算法驱动,协同过滤算法设计的思路为首先根据用户的点击行为沉淀读者的浏览信息,从而确定用户的喜好信息;然后根据用户的喜好生成共现矩阵,体现了图书之间的固有特点;最后根据这些固有属性计算图书与图书之间的距离,并根据某一个读者喜好的图书计算与改图书距离最近的那些图书,并推荐之。
系统在实现中,在前端使用基于JSP、CSS、Javascript等技术实现,在后端使用基于Java编程语言的框架,使用SpringMVC框架进行开发,这个开发过程可以复用框架的基本组件,提升了开发效率。
7.2展望
尽管在建设过程中,进行了深入调研,在设计和开发过程中也基于软件工程的思想和方法,利用工程化方法开发系统,并最终完成了系统的建设工作。在推荐中,使用较为成熟的基于物品的协同过滤算法。但仍然有很多需要进行改进的地方。
一是在过滤算法上还有待进一步提升。目前基于深度神经网络的推荐系统和基于图神经网络的推荐算法在推荐的成功率上有进一步的表现,后续可以基于深度学习和图神经网络等较为先进的神经网络给客户提供更为准确的推荐,提升成交率。
二是系统界面不够美观,后续可以进一步做这方面的工作。系统通过进一步美化和丰富有望可以商用,以提升对提升大家对图书的甄别速度。


















 1135
1135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











