







算法
牛客网编程题常见的编译错误:
(1)常常有逻辑是对的,但是打印时没有输出结果的情况
原因:一般是输入的测试数据有多组,但编写的程序中没有使用循环接收输入数据,直接收了一组测试数据造成的;
(2)对于二叉树等类似题型,提示堆栈溢出,递归或循环超出范围的情况
原因:一般是首次进入树序列时没有判断树的根节点是否为空;
算法描述问题:
答:描述算法的方法有多种,常用的有自然语言、结构化流程图、伪代码和PAD图等,其中最普遍的是流程图。
算法描述:
自然语言 也就是文字描述;
流程图 特定的表示算法的图形符号;
伪语言 包括程序设计语言的三大基本结构及自然语言的一种语言;
类语言 类似高级语言的语言,例如,类PASCAL、类C语言。
算法复杂度问题:
1)对数据进行压缩存储可以降低算法的空间复杂度;答:对于三个复杂度符号:可以简单的理解为θ是一个区间,O是上限(也就是最坏情况),Ω为下限(相当于最好情况),都是描述随输入量n的增长算法所花费的时间的增长情况。而一般情况下,我们都是使用o来表示复杂度(即最差的情况)。
时间复杂度计算方式:寻找算法中执行频度最高的那个语句,算出其执行次数F(n),去掉F(n)的系数可得到f(n),那么时间复杂度就是o(f(n)),其中n趋于无穷大。一般情况下,对于n趋于无穷大时,若频次始终是常数的,那么f(n)=1,所以时间复杂度为o(1);若频次是跟n为线性关系,那么f(n)=n,即时间复杂度为o(n);其他以此类推。
空间复杂度计算方式:类似于时间复杂度计算。
1、各种排序算法
答:常用的几种排序算法可参考:https://zhuanlan.zhihu.com/p/27232454不稳定排序:排序前后,相同元素相对位置关系发生改变;
教科书上的八种排序算法,按稳定排序和不稳定排序分类:
稳定排序:插冒归基
不稳定排序:快选堆希
注:基数排序的时间复杂度一般也可表示为O(r*n),当r较小时就近似为O(n);
如上表所示:
(1)冒泡、选择、直接插入排序统称为简单排序,时间复杂度均为O(n^2);
(2)希尔排序的时间复杂度与比较步长有关,一般可认为O(n^1.3);
(3)选择排序和堆排序的时间复杂度与初始序列排列顺序无关;
(4)空间复杂度有3个不是o(1),分别是快、归、基,其中快排又是相对较小的。
(5)比较排序的时间复杂度最多可以减少到O(nlogn),基数排序不是比较类排序,所以可以做到O(n);
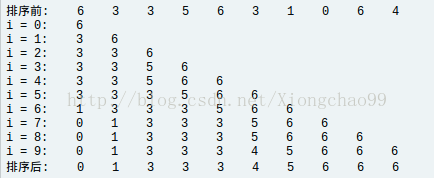
(1)直接插入排序
答:①就是对一段数据序列,从第一个开始像摸扑克牌时那样插入排序,如下图:
void insertion_sort(vector<int> &v) //插入排序算法
{
int temp = 0;
for (int i = 1; i < v.size(); i++)
{
if (v[i - 1] > v[i])
{
temp = v[i];
for (int j=i-1; j > =0 && v[j] > temp; j--)
{
v[j+1] = v[j];
}
v[j+1] = temp;
}
}
} ②直接插入排序的优化:在查找插入位置时使用二分查找法,因为前面都是有序序列,使用二分查找法速度更快;
(2)希尔排序
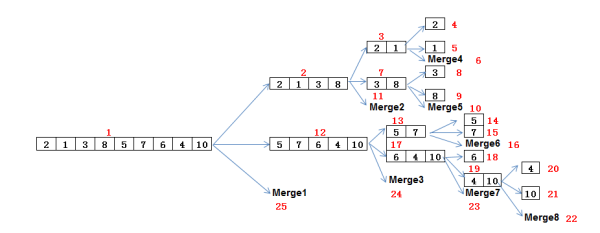
答:希尔(Shell)排序又称为缩小增量排序,它是一种插入排序。它是直接插入排序算法的一种威力加强版,即把原来的比较步长加大。排序如下例子: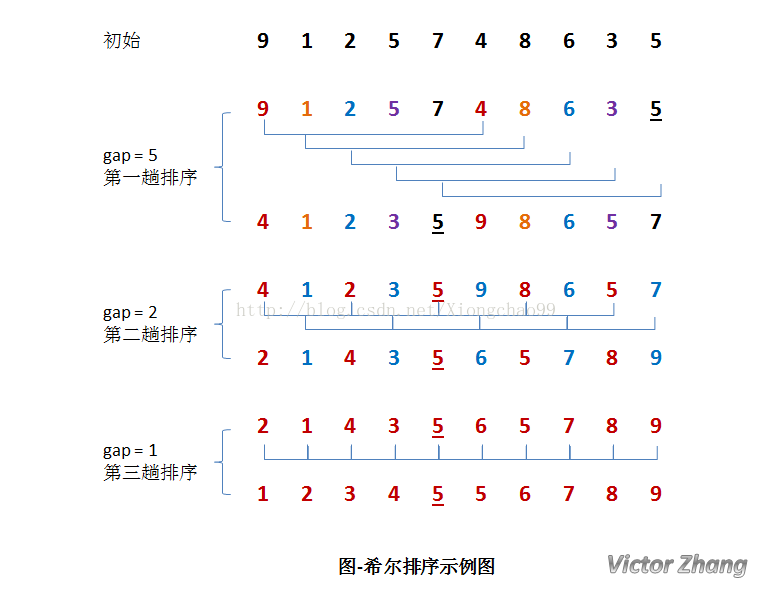
如上图,初始时,有一个大小为 10 的无序序列。
在第一趟排序中,我们不妨设 gap1 = N / 2 = 5,即相隔距离为 5 的元素组成一组,可以分为 5 组。
接下来,按照直接插入排序的方法对每个组进行排序。
在第二趟排序中,我们把上次的 gap 缩小一半,即 gap2 = gap1 / 2 = 2 (取整数)。这样每相隔距离为 2 的元素组成一组,可以分为 2 组。
按照直接插入排序的方法对每个组进行排序。
在第三趟排序中,再次把 gap 缩小一半,即gap3 = gap2 / 2 = 1。 这样相隔距离为 1 的元素组成一组,即只有一组。
按照直接插入排序的方法对每个组进行排序。此时,排序已经结束。
需要注意一下的是,图中有两个相等数值的元素 5 和 5 。我们可以清楚的看到,在排序过程中,两个元素位置交换了。
所以,希尔排序是不稳定的算法。时间复杂度:希尔排序的时间复杂度跟比较步长的选择有关,一般可以做到O(n^1.3);
代码实现:
void ShellInsert(vector<int> &v, int step)//比较希尔排序代码与简单插入排序代码的异同
{
int temp=0;
for(int i=step; i<v.size(); i++)
{
if(v[i]<v[i-step])
{
temp=v[i];
for(int j=i-step; j>=0 && v[j]>temp; j=j-step)
{
v[j+1]=v[j];
}
v[j+1]=temp;
}
}
}
void ShellSort(vector<int> v, vector<int> step)//最终排序
{
//按增量数组step依次对序列做希尔排序
for(int i=0; i<step.size(); i++)
{
ShellInsert(v, step[i]);
}
}
(3)冒泡排序
答:①冒泡排序是数据前后相邻数据比较,前比后大则两者交换,之后继续向后推进比较,一轮下来最大的数据会出现在序列最后。普通的冒泡排序时间复杂度始终是n^2。实现代码略;
②针对冒泡排序的改进,即某一趟冒泡排序后没有任何元素交换位置,则结束排序——设标志位。改进部分如下:
void(vector<int> v)
{
for(int i=0; i<v.size()-1;i++)
{
bool flag=false;
for(int j=0; j<v.size()-i;j++)
{
if(v[j] > v[j+1])
{
swap(v[j],v[j+1]);
flag=true;//有交换就将标志位置位
}
}
if(!flag)//若一趟结束都没有一次交换,表示序列已经有序
break;
}
}(4)快速排序
答:确定一个基数,先从后向前寻找一个比基数小的数(若没找到,就继续找),交换。然后转换比较方向,从前向后直到找到比基数大的,交换;再重复前面的过程。快排具体实现就是:从右找到第一个小于poviot(一般取序列中第一个数)的数,与之交换,同时left加1;然后再从左找到第一个大于poviot的数,与之交换,同时right减1;这样循环往复,直到与poviot比较的左右数据的下标相同(left=right)为止,此时poviot右边的数都大于左边,左边的数都大于右边。(注意:无论poviot被移到哪个位置,都是和它作比较)例如:取key=49
49 38 65 97 76 13 27 原始数组 k=49
27 38 65 97 76 13 49 l=0,r=6(从后向前)
2738 65 97 76 13 49 l=1,r=6(从前向后,未找到)
27 38 49 97 76 13 65 l=2,r=6(从前向后)
27 38 13 97 76 49 65 l=2,r=5(从后向前)
27 38 13 49 76 97 65 l=3,r=5(从前向后)
27 38 13 49 76 97 65 l=3,r=4(从后向前,未找到)
27 38 13 49 76 97 65 l=3,r=3(从后向前,未找到)
注意:快速排序中最快速情况是:每一趟排序的基准值(一般第一个数据)都可以在一趟排序完成后,将当前序列平均分为两个个数相等的序列。最差的情况是,每次选取的基准数据都是当前序列中最小或最大值,即当前序列是有序序列,此时其会退化为冒泡排序。简单总结:快排相比其他排序算法最具优势的情况是数值序列完全无序,最不具优势的情况是数值序列基本有序;
代码:
void quicksort(vector<int> &v,int left, int right)
{
if(left < right)//false则递归结束
{
int key=v[left];//基数赋值
int low = left;
int high = right;
while(low < high) //当low=high时,表示一轮分割结束
{
while(low < high && v[high] >= key)//v[low]为基数,从后向前与基数比较
{
high--;
}
swap(v[low],v[high]);
while(low < high && v[low] <= key)//v[high]为基数,从前向后与基数比较
{
low++;
}
swap(v[low],v[high]);
}
//分割后,对每一分段重复上述操作
quicksort(v,left,low-1);
quicksort(v,low+1,right);
}
}快排更多详情参考:http://blog.csdn.net/xiongchao99/article/details/74524807#t3
(5)选择排序
①每一次都遍历数据序列,从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在被排序序列第一个位置,直到全部待排序的数据元素排完(第一轮:用第一个数与后面数据比较,后面小就与之交换位置,继续用交换后的第一个和后续数据比较……,第二轮:用第二个数据和后面比较,类似第一轮方式,……,直到比较完所有数据)。 选择排序是不稳定的排序方法。总的比较次数N=(n-1)+(n-2)+...+1=n*(n-1)/2,与数据的初始排列顺序无关。实现代码略。
②除此之外还有树形选择排序,即锦标赛排序。如一个数据序列中找出最大的和第二大的数,用竞标赛思想解决最好:如有序列ABCDEFGH共8个数据的序列,找出最大和第二大的两个,需要比较的次数,见下图:

由图可知,找最大值用了7次比较,第二大值用了2次比较,共计用9次比较。
实现代码略;(6)堆排序
答:(1)堆排序是树形选择排序的改进型,其避免了后者较大的空间复杂度;注意:使用的最小/最大堆都是完全二叉树;
首先可以看到堆建好之后堆中第0个数据是堆中最小的数据。取出这个数据,再根据章节二中数据结构的堆删除方式,执行下堆的删除操作并进行堆恢复工作。这样堆中第0个数据又是堆中最小的数据,重复上述步骤直至堆中只有一个数据时就直接取出这个数据。
由于堆也是用数组模拟的,故堆化数组后,第一次将A[0]与A[n - 1]交换,再对A[0…n-2]重新恢复堆。第二次将A[0]与A[n – 2]交换,再对A[0…n - 3]重新恢复堆,重复这样的操作直到A[0]与A[1]交换。由于每次都是将最小的数据并入到后面排好序的数据序列前面,故操作完成后整个数组就有序了。注意使用最小堆排序后是递减数组,反之,最大堆排序后是递增数组。
堆顶删除后的排序也可见下例:
根据堆的删除规则,删除操作只能在堆顶进行,也就是删除0元素。
然后让最后一个节点放在堆顶,做向下调整工作,让剩下的数组依然满足最小堆。
删除0后用8填充0的位置,为[8,3,2,5,7,4,6]
然后8和其子节点3,2比较,结果2最小,将2和8交换,为:[2,3,8,5,7,4,6]
然后8的下标为2,其两个孩子节点下标分别为2*2+1=5,2*2+2=6
也就是4和6两个元素,经比较,4最小,将8与4交换,为[2,3,4,5,7,8,6]
这时候8已经没有孩子节点了,调整完成。
每次堆删除后的堆恢复时间复杂度为O(logn),堆排序总时间复杂度=O(nlogn);空间复杂度=O(1);
//注意:为了计算方便,默认数组从下标1开始,即数组v的首元素空着;
void HeapAdjust(vector<int> v, int start, int end)//start是待调整堆的堆顶元素下标,end即为待调整堆的最后一个元素下标
{
int top=v[start];
for(int j=2*start; j<=end; j=2*j)
{
if(j<end && v[j]<v[j+1])
j++;
if(top<v[j])
{
v[start]=v[j];
start=j;
}
else
break;
}
v[start]=top;
}
void HeapSort(vector<int> &v) //最终排序
{
//建堆(从下往上进行子堆调整即可实现)
for(int i=v.size()/2; i>0; i--) //i=v.size()/2是倒数第二层的最后一个非叶子节点
HeapAdjust(v, i, v.size()); //本来end应该是当前子堆的最后一个元素,但使用整堆的最后一个元素下标依然可以;
//取堆顶元素与堆末尾交换并调整剩下的前半部分堆元素
for(int j=v.size(); j>=1; j--)
{
swap(v[1], v[j]);
HeapAdjust(v, 1, j-1);
}
}
(2)除此之外,C++的STL中也有建堆和堆调整的函数可调用,有make_heap()。用STL函数实现堆排序具体方式如下:
①代码简写:
vector<int> v;
make_heap(v.begin(),v.end());//建堆
for(;;){
……//交换堆顶和堆尾
make_heap(v.begin(),v.end()-i);//堆调整(用建堆函数实现)
}②用pop_heap()/push_heap()可以实现堆顶删除调整和堆尾插入调整:
vector<int> v;
pop_heap(v.begin(),v.end());//先pop_heap,然后在容器中删除
v.pop_back();
v.push_back(temp);//先在容器中加入,再push_heap
push_heap(v.begin(),v.end());删除堆顶pop_heap实际并没有删除,只是将堆顶元素放到堆尾,然后对前面剩下的对元素进行堆调整。要实实在在的删除后面就还需要调用pop_back();
插入元素push_heap则要注意必须在push_back语句操作后面,否则无法实现堆调整。
(3)top K问题一般可以使用的算法有堆排序、快排、选择排序。
其中,堆排序用的比较多,因为对于大量数据,可实现NlogK的实现复杂度。其中,具体的可以逐个元素的对堆进行删除/插入,遍历完所有元素后得到的堆元素就是TOP K。
注意:最大的K个元素用最小堆(小根堆),相反最小的K个元素用最大堆(大根堆);
这里给出两种实现最大K个元素的代码:①make_heap调整堆:
vector<int> GetLeastNumbers_Solution(vector<int> input, int k){
int len=input.size();
if(len<=0||k<=0||k>len)
return vector<int>();
vector<int> v(input.begin(),input.begin()+k);//用测试数组前k个元素初始化堆数组
make_heap(v.begin(),v.end());//默认最大堆,要建立最小堆可以添加第三个参数greater<int>()
for(int i=k;i<input.size();i++){
if(input[i]>v[0]){ //逐个替换堆顶并调整
v.push_back(input[i]);
swap(v[0],v[k]);
v.pop_back();
make_heap(v.begin(),v.end());
}
}
return v;
}vector<int> GetLeastNumbers_Solution(vector<int> input, int k) {
int len=input.size();
if(len<=0||k<=0||k>len)
return vector<int>();
vector<int> v(input.begin(),input.begin()+k);
make_heap(v.begin(),v.end());
for(int i=k;i<input.size();i++){
if(input[i]<v[0]){
pop_heap(v.begin(),v.end());//先pop_heap,然后在容器中删除
v.pop_back();
v.push_back(input[i]);//先在容器中加入,再push_heap
push_heap(v.begin(),v.end());
}
}
sort(v.begin(),v.end());
return v;
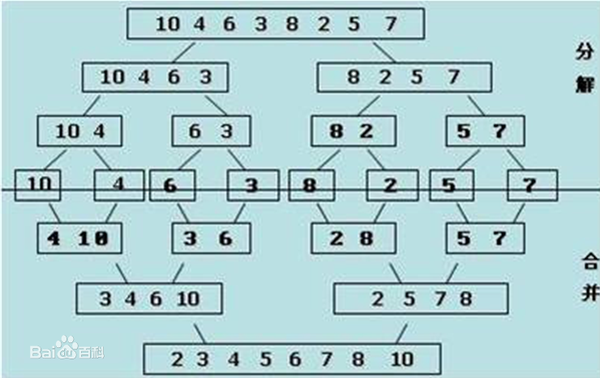
}(7)归并排序
答:n个元素k路归并排序的归并趟数:s=logk(n);常见的归并排序是2路归并排序,其时间复杂度=log(n),空间复杂度=O(n);//归并两个子序列
void Merge(vector<int> v1, vector<int> &v2, int start, int mid, int end) //用一个序列装两组数组,使用start、mid、end区分不同序列
{
//将分组v1[start,...., mid]与分组v1[mid+1, ... ,end]归并为一个数组序列
int i=start, j=mid+1,k=0;
while(i<= mid && j<=end )
{
if(v1[i]<v1[j])
v2[k++]=v1[i++];
else
v2[k++]=v1[j++];
}
if(i<=mid)
v2[k, ... ,end]=v1[i, ... ,mid]; //简要表示
else if(j<=end)
v2[k, ... ,end]=v1[j, ... ,end]; //简要表示
//将排好序的新序列v2覆盖到原序列v1中
v1[start, ..., end]=v2[0, ..., v2.size()-1]; //简要表示
}
//最终排序(先分割再归并,递归实现)
vector<int> v2; //创建辅助数组(最终长度为n)
void MergeSort(vector<int> &arr, int start,int end)
{
if(start<end)
{
int mid=(start+end)/2;
MergeSort(arr, start, mid); //递归生成左子节点(分割出左序列)
MergeSort(arr, mid+1, end); //递归生成右子节点(分割出右序列)
Merge(arr, v2, start, mid, end); //对树当前层上述两个序列进行归并
}
}void mergeSort(vector<int>& data, int start, int end) {
// 递归终止条件
if(start >= end) {
return 0;
}
// 递归
int mid = (start + end) / 2;
mergeSort(data, start, mid);
mergeSort(data, mid+1, end);
// 归并排序,并计算本次逆序对数
vector<int> copy(data); // 数组副本,用于归并排序
int foreIdx = mid;// 前半部分的指标
int backIdx = end;// 后半部分的指标
int counts = 0;// 记录本次逆序对数
int idxCopy = end;// 辅助数组的下标
while(foreIdx>=start && backIdx >= mid+1) {
if(data[foreIdx] > data[backIdx])
copy[idxCopy--] = data[foreIdx--];
else
copy[idxCopy--] = data[backIdx--];
}
while(foreIdx >= start) {
copy[idxCopy--] = data[foreIdx--];
}
while(backIdx >= mid+1) {
copy[idxCopy--] = data[backIdx--];
}
for(int i=start; i<=end; i++) {
data[i] = copy[i];
}
}
基数排序——时间复杂度O(d(k+n)),要求:d位数,每个数位有k个取值。一般情况下k和d较小,所以时间复杂度=O(n);
桶排序——时间复杂度O(n),要求:被排序数在某个范围内,范围过大的话桶的个数会过多;
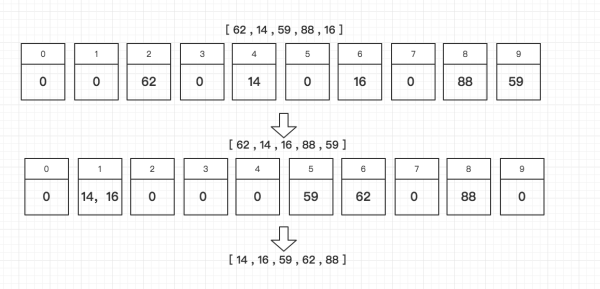
(8)基数排序
答:多关键字排序,举例说明:2°、再次入桶,不过这次以十位数的数字为关键字,进入相应的桶,同一桶内有序;
3°、再次按顺序取出,排序完成;
2、KMP算法
答:(1) KMP算法是字符串匹配算法,它由简单字符串匹配(BF)转化而来。其中,若串长为n,模式串长为m,则BF算法(普通匹配算法):时间复杂度O(m*n);空间复杂度O(1);
KMP算法:时间复杂度O(m+n);空间复杂度O(n);
KMP算法需要模式函数值数组next[m],用于辅助。
例如,在S=”abcabcabdabba”中查找T=”abcabd”,如果使用KMP匹配算法,当第一次搜索到S[5] 和T[5]不等后,S下标不是回溯到1,T下标也不是回溯到开始,而是根据T中T[5]==’d’的模式函数值(next[5]=2,为什么?后面讲),直接比较S[5] 和T[2]是否相等,因为相等,S和T的下标同时增加;因为又相等,S和T的下标又同时增加,最终在S中找到了T。如图:
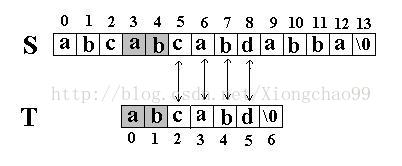
所以,KMP算法相比普通匹配算法最大的优点就是: 主字符串S的指针不需要回溯。
(2)next数组求取方法:
3、折半查找法(二分查找法)
答:要求:
1.必须采用顺序存储结构;
2.必须按关键字大小有序排列(不一定要升序)。
方法:取正中间进行比较,小则丢掉正中间被比较数大的一侧所有数据,继续采用二分查找比较小的一侧数据。查找中,偶数个数据取正中间靠近起始方向的数据比较,奇数个数据取正中间的。
时间复杂度:o(lgN)
4、蚂蚁爬行算法
答:n只蚂蚁以每秒1cm的速度在长为Lcm的竹竿上爬行。当蚂蚁看到竿子的端点时就会落下来。由于竿子太细,两只蚂蚁相遇时,它们不能交错通过,只能各自反方向爬行。对于每只蚂蚁,我们只知道它离竿子最左端的距离为xi,但不知道它当前的朝向。请计算所有蚂蚁落下竿子的最短时间和最长时间。
问题的要点:蚂蚁相遇后反方向爬行当做穿透对方继续爬行。故最大时间就是离某一端点最远的蚂蚁用时,最小时间则为离某端点最近的蚂蚁用时中的最大者。
5、汉诺塔(Hanoi塔)
问题:汉诺塔问题中有三根杆子A,B,C。A杆上有N个(N>1)穿孔圆盘,盘的尺寸由下到上依次变小。要求按下列规则将所有圆盘移至C杆:
①每次只能移动一个圆盘;
②每个杆上大盘不能叠在小盘上面;
③根据A上原有圆盘个数k,要完成A上所有圆盘移出至C需要移动次数为。
汉诺塔移动次数的公式:f(k+1)=2*f(k)+1;(其中,f⑴=1,f⑵=3,f⑶=7)
为什么呢?假设有4个圆盘,那么移动过程可以如下描述:
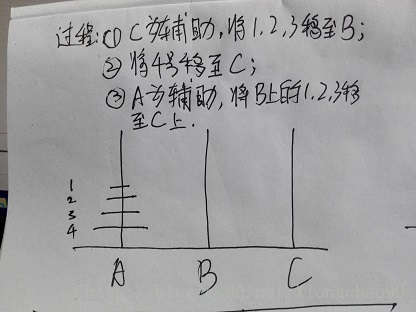
①中其中将1,2,3号移动到B,移动次数为f(3);
②中只是将最底下的圆盘移动到空杆C上,那么移动次数就是1;
③中将A作为辅助,移动B上的1,2,3号到C上,移动次数同①,仍然为f(3);
故总次数为:f(4)=2*f(3)+1;
以上移动流程具有普适性,可以推广到k=n,故可得公式:f(k+1)=2*f(k)+1。
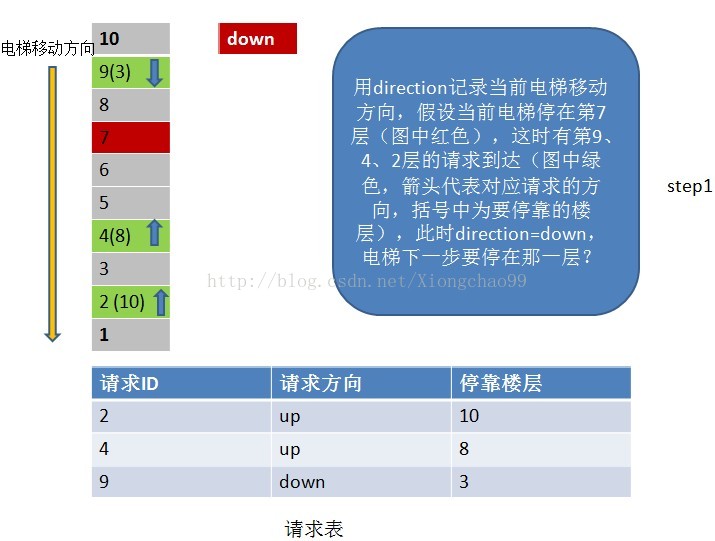
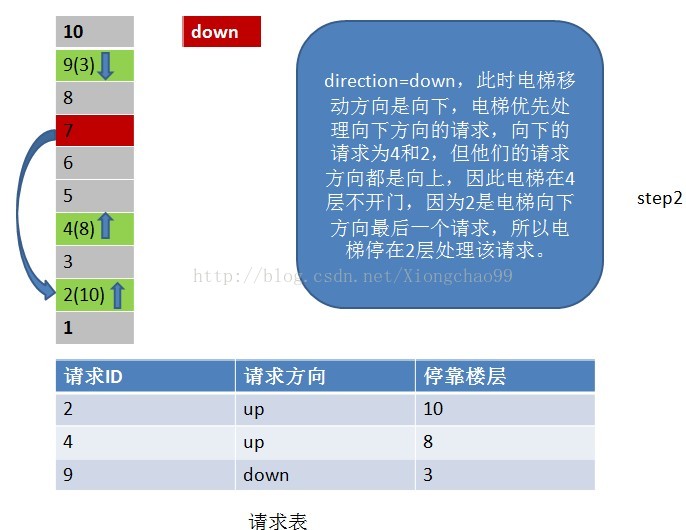
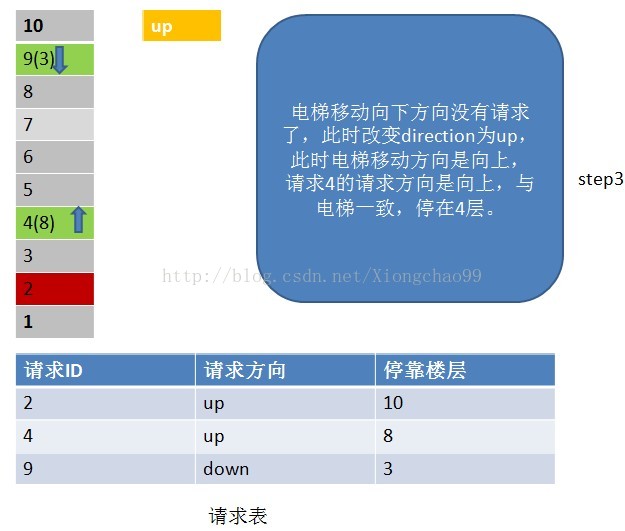
6、常见的电梯调度算法
答:电梯调度算法:
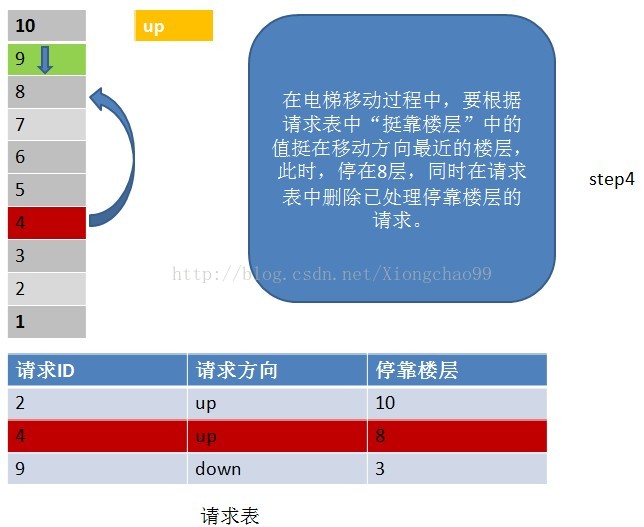
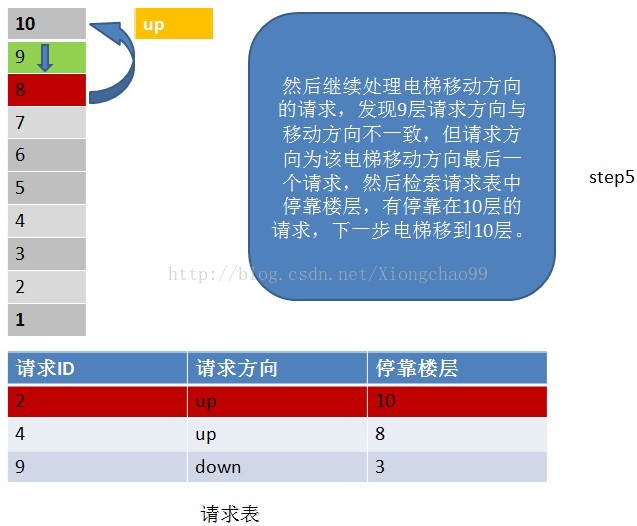
1)电梯有移动方向,各楼层的请求有请求方向,这里维护一个请求表(记录请求ID,请求方向,该请求的停靠楼层);
2)电梯按照一个方向移动,直到该方向没有请求,不会根据某一层的请求方向突然改变电梯的移动方向。但是注意:电梯在移动过程中只处理与“电梯移动方向”相同请求方向的请求。如电梯向下移动,只处理电梯下方楼层的请求,且该请求的方向也向下(停靠楼层请求无方向)。若请求楼层在向下方向,但请求方向不是向下,是不做处理的;
3)没完成一个请求,就从请求表中删除该请求记录;
4)若移动方向上已经没有请求(这个请求不仅包括请求表中的请求楼层,还包括停靠楼层),但电梯移动方向的反方向有请求,就把电梯移动方向置位为反方向;
实际上,电梯调度算法和一些操作系统调度算法如磁盘寻道是类似的。
请看下面例子:


7、动态规划(DP)问题
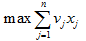
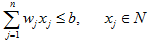
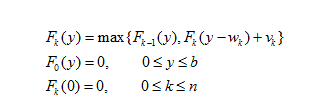
for(int i=1;i<=N;i++)
{
for(int j=1;j<=M;j++)
{
if(v[i]<=j)
{
dp[i][j] = dp[i-1][j-v[i]]+v[i]>dp[i-1][j] ? dp[i-1][j-v[i]]+v[i]:dp[i-1][j];
}
else
dp[i][j]=dp[i-1][j];
}
}for (int i=1; i<=N; i++)
for (int j=M; j>=1; j--)
{
if (weight[i]<=j)
{
f[j]=max(f[j],f[j-weight[i]]+value[i]); //被修改的f[j]这一轮循环后续部分就不会再用了,所以直接用一个数组即可
}
}
for (int i=1; i<=N; i++)
for (int j=1; j<=M; j++)
{
for(int k=1;k<K;k++)
{
if (k*weight[i]<=j)
{
f[i][j]=max(f[i-1][j],f[i-1][j-k*weight[i]]+k*value[i]);
}
else
break;
}
}
}

for (int i=1; i<=N; i++)
for (int j=M; j>=1; j--)
{
if (weight[i]<=j)
{
f[j]=max(f[j],f[j-weight[i]]+value[i]);
}
} 8、英语句子按单词为单位逆序
9、根据3条边求三角形面积——海伦公式
area=sqrt(s*(s-m_a)*(s-m_b)*(s-m_c));
if((m_a+m_b>m_c) && (m_a+m_c>m_b) && (m_b+m_c>m_a)) //这个判断一定需要有
{
double s=(m_a+m_b+m_c)/2; //算法主要部分
double area=sqrt(s*(s-m_a)*(s-m_b)*(s-m_c));
} 10、回文序列相关问题
int maxLen2(string str)
{
string s;
//添加辅助符#
s.push_back('#');
for(int k=0;k<str.size();k++){
s.push_back(str[k]);
s.push_back('#');
}
cout<<s<<endl;
//依次把每个字符作为对称中心进行最长回文判断
int len = s.size();
int maxlen=0;
for (int i = 1; i < len-1; i++) //s的首尾都是#,不属于原字符串,可不计算
{
int count=1;
while(i-count>=0&&i+count<=len-1 && s[i-count]==s[i+count]){
count++;
}
if(maxlen<count-1)
maxlen=count-1;
}
return maxlen;
}

int maxLen3(string str)
{
string s;
//添加辅助符#
s.push_back('#');
for(int k=0;k<str.size();k++){
s.push_back(str[k]);
s.push_back('#');
}
cout<<s<<endl;
//依次把每个字符作为对称中心进行最长回文判断
int len = s.size();
//以下为相比野蛮改进法新增的参数
int *p = new int[len]; //辅助数组(记录每个点为对称轴的回文长度)
p[0] = 1;
int mx =0, pi=0;//边界和对称中心
for(int i=1;i<len-1;i++) //s的首尾都是#,不属于原字符串,可不计算
{
if(mx>i)
{
p[i]=min(mx-i+1,p[2*pi-i]);//核心
}else{
p[i]=1;
}
while(i-p[i]>=0&&i+p[i]<=len-1 && s[i-p[i]]==s[i+p[i]]){
p[i]++;
}
if(i+p[i]-1 > mx){
mx = i+p[i]-1;
pi = i;
}
}
//最大回文字符串长度
int maxlen = 0;
for(int i=1;i<len-1;i++)
{
if(p[i]>maxlen)
{
maxlen = p[i];
}
}
delete []p;
return maxlen-1;
}定义LCS(i,j)=LCS(a1a2……ai,b1b2……bj),其中0≤i≤N,0≤j≤M.
对于1≤i≤N,1≤j≤M,有公式:
若ai=bj,则LCS(i,j)=LCS(i-1,j-1)+1;
若ai≠bj,则LCS(i,j)=Max(LCS(i-1,j-1),LCS(i-1,j),LCS(i,j-1));
#include<iostream>
#include<vector>
#include<string>
#include<algorithm>
using namespace std;
int maxLen(string s1, string s2){
int length1 = s1.size();
int length2 = s2.size();
vector<vector<int> > MaxLen(length1+1,vector<int>(length2+1)); //也可以用指针来定义二维动态数组
for (int i = 1; i <= length1; ++i)
{
for (int j = 1; j <= length2; ++j)
{
if (s1[i-1] == s2[j-1]){
MaxLen[i][j] = MaxLen[i-1][j - 1] + 1;
}
else{
MaxLen[i][j] = max(MaxLen[i - 1][j], MaxLen[i][j - 1]);
}
}
}
return MaxLen[length1][length2];
}
int main(){
string str;
while(cin>>str){
string str0=str;
reverse(str.begin(),str.end());
cout<<maxLen(str0,str)<<endl;
}
}
11、素数统计
答:有两种方法:筛选法和开根号法;筛选法:从小到大筛去一个已知素数的所有倍数。依次删除可被2整除,3整除……的数字,剩下的则为素数 。
筛选法是原理:所有非素数都是素数的乘积构成的;
void getPrime0(int n){
int i,j;
bool m;
for(i = 1; i <= n; i ++){
m = true;
for(j = 2; j < i; j ++){
if(i % j == 0){
m = false;
break;
}
}
if(m){
cout << i << " ";
}
}
cout << endl;
}bool prime(int x)
{
int y;
for(y=2;y<=sqrt(x);y++)
if (x%y==0)
return false;
return true;
}12、小明走台阶问题——一个楼梯有n级,小明一次最多跨3级,问小明走完台阶有多少种走法?
首先,假设走法总数为f(n),那么f(1)=1,f(2)=2,f(3)=4;
注意:这是一次最多跨三级,如果只能跨两级就需要做相应改变。
f(1)=1
f(2)=2
f(3)=4
f(4)=7
f(5)=2*7-f(1)=13
f(6)=2*13-f(2)=24
f(7)=2*24-f(3)=44
f(8)=88-f(4)=81
f(9)=2*81-f(5)=149
f(10)=298-f(6)=274
f(11)=548-f(7)=504
f(12)=1008-f(8)=927
f(13)=1854-f(9)=1854-149=1705
f(14)=3410-f(10)=3410-274=3136
f(15)=6272-f(11)=6272-504=5768
……
int climbStairs(int n){
vector<int> v;
v.push_back(1);
v.push_back(1);
for(int i = 2; i <= n; i++){
v.push_back(v[i - 1] + v[i - 2]);
}
return v[n];
}13、给定n个数的进栈序列,求出栈序列有多少种类型——卡特兰数
答:n个数有多少种出栈序列,用卡特兰数求:
f(n)=f(0)f(n-1)+f(1)f(n-2)+f(2)f(n-3)+……+f(n-2)f(1)+f(n-1)f(0);其中,f(0)=f(1)=1;
所以,如果有一入栈序列为e1,e2,e3,e4,e5,那么出栈序列就有f(5)=42种。
14、快慢指针——判断循环链表及其他
答:快慢指针中的快慢指的是移动的步长,即每次向前移动速度的快慢。例如可以让快指针每次沿链表向前移动2,慢指针每次向前移动1次。
(1)快慢指针可以用于判断单循环链表:让快慢指针从链表头开始遍历,快指针向前移动两个位置,慢指针向前移动一个位置:
1)如果快指针到达NULL,说明链表以NULL为结尾,不是循环链表;
2)如果 快指针追上慢指针,即快指针=慢指针,则表示出现了循环。
3)为什么慢指针步长为1的话,快指针步长就为2:因为只有fastStep-slowStep=1,才能实现快慢指针一定相遇,而不是快指针越过慢指针。
代码实现如下:
int isExitsLoop(LinkList* L) {
LinkList *fast, *slow;
fast = slow = L;
while (fast!=NULL && fast->next!=NULL)
{
slow = slow->next;
fast = fast->next->next;
if (slow == fast)
{
break;
}
}
return ((fast == NULL) || (fast->next == NULL));
}快慢指针用于判断有无环,有时候还要判断环的入口位置(尤其是单链表局部环入口),这种情况参考另一博文:http://blog.csdn.net/xiongchao99/article/details/74524807#t15
(2)快慢指针获取链表中间节点
使用快慢指针同时出发,当快指针到达终结点时慢指针刚好到达中间节点。
15、寻找二叉树中两个节点的最近祖先节点
答:1)若二叉树是二叉排序树(或叫做二叉查找树、二叉搜索树):
直接前序遍历,找到一个节点m,满足n1<m<n2,其中n1、n2是给定的两个节点。
2)若为普通二叉树:
①树节点结构体中给定父节点指针
如:
struct node{
Node * left;
Node * right;
Node * parent;
}
则算法思想:首先给出p的父节点p->parent,然后将q的所有父节点依次和p->parent作比较,如果发现两个节点相等,则该节点就是
最近公共祖先,直接将其返回。如果没找到相等节点,则将q的所有父节点依次和p->parent->parent作比较,直到p->parent==root。
程序实现如下:
Node * NearestCommonAncestor(Node * root,Node * p,Node * q)
{
Node * temp;
while(p!=NULL)
{
p=p->parent;
temp=q;
while(temp!=NULL)
{
if(p==temp->parent)
return p;
temp=temp->parent;
}
}
} ②若未给定父节点指针
算法思想:如果一个节点的左子树包含p,q中的一个节点,右子树包含另一个,则这个节点就是p,q的最近公共祖先。
程序实现:
/*查找a,b的最近公共祖先,root为根节点,out为最近公共祖先的指针地址*/
int FindNCA(Node* root, Node* a, Node* b, Node** out)
{
if( root == null )
{
return 0;
}
if( root == a || root == b )
{
return 1;
}
int iLeft = FindNCA(root->left, a, b, out);
if( iLeft == 2 )
{
return 2;
}
int iRight = FindNCA(root->right, a, b, out);
if( iRight == 2 )
{
return 2;
}
if( iLeft + iRight == 2 )
{
*out = root;
}
return iLeft + iRight;
}
16、双栈排序
答:例如,实现栈数据的升序排列,即栈顶数据最大。
思路:利用一个辅助栈,每次比较排序栈和辅助栈的顶元素,如果排序栈较小直接压入辅助栈,并弹出排序栈,否则将辅助栈的元素弹出并压在排序栈栈顶元素的后面。如此反复,直到排序栈没有元素了,之后将辅助栈的元素全部导入排序栈,就完成排序。
程序实现:
class TwoStacks {
public:
vector<int> twoStacksSort(vector<int> numbers) {
stack<int> mystack,help;
for(auto i=numbers.end()-1;i>=numbers.begin();--i)
mystack.push(*i);
while(!mystack.empty())
{
if(help.empty()){
help.push(mystack.top());
mystack.pop();
}
else if(mystack.top()<=help.top())
{
help.push(mystack.top());
mystack.pop();
}
else
{
int temp=mystack.top();
mystack.pop();
mystack.push(help.top());
mystack.push(temp);
help.pop();
}
}
while(!help.empty())
{
mystack.push(help.top());
help.pop();
}
for(auto &c:numbers)
{
c=mystack.top();
mystack.pop();
}
return numbers;
}
};
17、判断一个二叉树结构是否为另一个二叉树的子结构
答:一般算法分为两个步骤:
(1)第一步在树A中找到和B的根节点的值一样的结点R;
(2)第二步再判断树A中以R为根结点的子树是不是包含和树B一样的结构。
C++实现代码如下:
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
bool HasSubtree(TreeNode* pRoot1, TreeNode* pRoot2)
{
bool flag=false;
if(pRoot1!=NULL && pRoot2!=NULL)
{
if(pRoot1->val==pRoot2->val) //判断根节点,相等就继续判断其他节点是否相等
flag=Match(pRoot1,pRoot2);
if(!flag) //否则判断左儿子节点是否与子结构根节点相等
flag=HasSubtree(pRoot1->left,pRoot2);
if(!flag) //还不等,则判断右儿子节点是否与子结构根节点相等
flag=HasSubtree(pRoot1->right,pRoot2);
}
return flag;
}
bool Match(TreeNode* root1,TreeNode* root2){
if(root1 == NULL && root2 != NULL) return false;
if(root2 == NULL) return true;
if(root1->val != root2->val) return false;
//if(root1->val == root2->val)
return Match(root1->left, root2->left)&&Match(root1->right, root2->right);
}
};
18、DFS
答:以二叉树为例(就是二叉树的先根遍历),其他树或图的DFS在此基础上进行改进。实现代码如下:
①递归方式十分简单:
void preorder(TreeNode root){
if(root){
cout<<root->data<<' ';
preorder(root->lchild);
preorder(root->rchild);
}
} ②非递归方式:需要使用栈作为辅助,两个循环实现;
while(t || s.empty!=True){
while(t){ //只要结点不为空就应该入栈保存,与其左右结点无关
cout<<t->data<<' ';
push(&s,t);
t= t->lchild;
}
t=pop(&s);
t=t->rchild;
}
19、BFS——队列辅助
答:以二叉树为例(就是二叉树按层遍历),其他树或图的BFS在此基础上进行改进。使用队列queue实现,每当从队列头部弹出一个节点,就将该节点的子节点按先左后右的方式压入队尾;实现代码如下:
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
vector<int> PrintFromTopToBottom(TreeNode* root) {
vector<int> v;
queue<TreeNode*> q;
if(root==NULL)
return v;
q.push(root);
while(q.size()>0){
int data=q.front()->val;
v.push_back(data);
if(q.front()->left!=NULL)
q.push(q.front()->left);
if(q.front()->right!=NULL)
q.push(q.front()->right);
q.pop();
}
return v;
}
};
20、贪心算法
1.建立数学模型来描述问题。
2.把求解的问题分成若干个子问题。
3.对每一子问题求解,得到子问题的局部最优解。
4.把子问题的解局部最优解合成原来解问题的一个解。
贪心策略适用的前提是:局部最优策略能导致产生全局最优解。
实际上,贪心算法适用的情况很少。一般,对一个问题分析是否适用于贪心算法,可以先选择该问题下的几个实际数据进行分析,就可做出判断。
如下:
while (能朝给定总目标前进一步)
{
利用可行的决策,求出可行解的一个解元素;
}
由所有解元素组合成问题的一个可行解;
例如:n=3时,3个整数13,312,343,连成的最大整数为34331213。
又如:n=4时,4个整数7,13,4,246,连成的最大整数为7424613。
21、比较钻石重量(笔试编程题)
给定两颗钻石的编号g1,g2,编号从1开始,同时给定关系数组vector,其中元素为一些二元组,第一个元素为一次比较中较重的钻石的编号,第二个元素为较轻的钻石的编号。最后给定之前的比较次数n。请返回这两颗钻石的关系,若g1更重返回1,g2更重返回-1,无法判断返回0。输入数据保证合法,不会有矛盾情况出现。
测试样例:2,3,[[1,2],[2,4],[1,3],[4,3]],4
返回:1
int cmp(int g1, int g2, int records[][2], int n)
{
// write code here
vector<int> max, min;
//先直接根据含有g1的比较组,将大于g1的值添加到数组max,小于g1的值添加到数组min
for (int i = 0; i < n; i++)
{
if (records[i][0] == g1)
{
min.push_back(records[i][1]);
}
if (records[i][1] == g1)
{
max.push_back(records[i][0]);
}
}
//然后根据重量大小关系的传递性,循环比较,向max中添加比max已有元素还大的值,向min中
//添加比min已有元素还小的值
int count = 0;
while (count < n) //为什么要比较n轮:最坏的情况是每轮只有比较序列中最后一对某元素被添加,故
{ //需要n轮才可以保证添加完整性
count++;
for (int i = 0; i < n; i++)
{
if (records[i][0] != g1 && records[i][1] != g1)
{
if (find(min.begin(),min.end(),records[i][0])!=min.end()) //原有min数组中发现当前数值对较大者
min.push_back(records[i][1]);
if (find(max.begin(),max.end(),records[i][1])!=max.end()) //原有max数组中发现当前数值对较小者
max.push_back(records[i][0]);
}
}
}
if (find(max.begin(),max.end(),g2)!=max.end() && find(min.begin(),min.end(),g2)==min.end())
return -1;
else if (find(max.begin(),max.end(),g2)==max.end() && find(min.begin(),min.end(),g2)!=min.end())
return 1;
else
return 0;
}22、任意进制之间互相转换
将一个处于Integer类型取值范围内的整数从指定源进制转换为指定目标进制; 可指定的进制值范围为[2,62];
每个数字位的可取值范围为[0-9a-zA-Z]; 输出字符串的每一个都须为有效值;反例:"012"的百位字符即为无效值。 实现时无需考虑非法输入。
输入描述:
输入为:
源进制 目标进制 待转换的整数值
例子:8 16 12345670
输出描述:
整数转换为目标进制后得到的值
输入例子:
8 16 12345670
输出例子:
29cbb8
#include<iostream>
#include<string>
using namespace std;
int main(){
int source,target=0;
string str;
while(cin>>source>>target>>str){
int DecNum=0;
//区分正负数
int i=0;
if(str[0]=='-')
i=1;
else
i=0;
//转化为10进制
while(i<str.size()){
int num=0;
DecNum=DecNum*source;
if(str[i]<='9')
num=str[i]-'0';
else if(str[i]>='a' && str[i]<='z')
num=str[i]-'a'+10;
else if(str[i]>='A' && str[i]<='Z')
num=str[i]-'A'+36;
DecNum+=num;
i++;
}
//10进制转化为目标进制
string tStr;
while(DecNum>0){
string temStr;
int num=DecNum%target;
if(num<=9)
temStr=std::to_string(static_cast<long long>(num)); //VS2010未实现int转化为string
else if(num>=10 && num<=35)
temStr='a'+num-10;
else if(num>=36 && num<=61)
temStr='A'+num-36;
tStr=temStr+tStr;
DecNum=DecNum/target;
}
if(str[0]=='-')
tStr="-"+tStr;
cout<<tStr<<endl;
}
}23、链表反转
ListNode* ReverseList(ListNode* pHead) {
ListNode *p,*q,*r;
if(pHead==NULL || pHead->next==NULL){
return pHead;
}else{
p=pHead;
q=p->next;
pHead->next=NULL;
while(q!=NULL){
r=q->next;
q->next=p;
p=q;
q=r;
}
return p;
}
}24、统计二进制中有多少个1
int Count1(unsigned int v)
{
int num = 0;
while(v)
{
if(v % 2 == 1)
{
num++;
}
v = v/2;
}
return num;
}int Count2(unsigned int v)
{
unsigned int num = 0;
while(v)
{
num += v & 0x01;
v >>= 1;
}
return num;
}int Count3(unsigned int v)
{
int num = 0;
while(v)
{
v &= (v-1);
num++;
}
return num;
}25、复杂链表复制
struct RandomListNode {
int label;
struct RandomListNode *next, *random;
RandomListNode(int x) :
label(x), next(NULL), random(NULL){
}
};链接:https://www.nowcoder.com/questionTerminal/f836b2c43afc4b35ad6adc41ec941dba
来源:牛客网
RandomListNode* Clone(RandomListNode* pHead)
{
if(!pHead) return NULL;
RandomListNode *currNode = pHead;
while(currNode){
RandomListNode *node = new RandomListNode(currNode->label);
node->next = currNode->next;
currNode->next = node;
currNode = node->next;
}
currNode = pHead;
while(currNode){
RandomListNode *node = currNode->next;
if(currNode->random){
node->random = currNode->random->next;
}
currNode = node->next;
}
//拆分
RandomListNode *pCloneHead = pHead->next;
RandomListNode *tmp;
currNode = pHead;
while(currNode->next){
tmp = currNode->next;
currNode->next =tmp->next;
currNode = tmp;
}
return pCloneHead;
}26、两个有序链表合并
while(i<a.size() && j<b.size()){
if(a[i]>=b[j]){
v.push_back(a[i]);
i++;
}
else{
v.push_back(b[j]);
j++;
}
}
if(i<a.size()){
……
}
else if(b.size()){
……
}/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* Merge(ListNode* pHead1, ListNode* pHead2)
{
if(pHead1==NULL){
return pHead2;
}else if(pHead2==NULL){
return pHead1;
}
ListNode* pHead;
vector<ListNode*> v;
int len=0;
while(pHead1!=NULL && pHead2!=NULL){
if(pHead1->val<=pHead2->val){
v.push_back(pHead1);
pHead1=pHead1->next;
}else{
v.push_back(pHead2);
pHead2=pHead2->next;
}
len=v.size();
if(len>=2){
v[len-2]->next=v[len-1];
}
}
if(pHead1!=NULL){
v[len-1]->next=pHead1;
}else if(pHead2!=NULL)
v[len-1]->next=pHead2;
pHead=v[0];
return pHead;
}
};ListNode* Merge(ListNode* pHead1, ListNode* pHead2)
{
if(pHead1==NULL)
return pHead2;
else if(pHead2==NULL)
return pHead1;
if(pHead1->val <= pHead2->val){
pHead1->next=Merge(pHead1->next,pHead2);
return pHead1;
}else{
pHead2->next=Merge(pHead1,pHead2->next);
return pHead2;
}
}27、字符串全排列
vector<string> Permutation(string str){
vector<string> v;
if(str=="")
return v;
sort(str.begin(), str.end());//必须先递增排序,使得str是最小一种排序
do
{
v.push_back(str);
}
while (next_permutation(str.begin(), str.end()));//每一次循环返回true表示找到了比str大的字符串
return v;
}prev_permutation:
bool cmp(const char a,const char b){
return a>b;
}
vector<string> Permutation(string str){
vector<string> v;
if(str=="")
return v;
sort(str.begin(), str.end(),cmp);//此处不同
do
{
v.push_back(str);
}
while (prev_permutation(str.begin(), str.end()));
return v;
}1,从尾部往前找第一个P(i-1) < P(i)的位置
4 6 <- 9 <- 8 <- 7 <- 5 <- 2 <- 1
最终找到6是第一个变小的数字,记录下6的位置i-1
2,从i位置往后找到最后一个大于6的数
4 6 -> 9 -> 8 -> 7 5 2 1
最终找到7的位置,记录位置为m
3,交换位置i-1和m的值
4 7 9 8 6 5 2 1
4,倒序i位置后的所有数据
4 7 1 2 5 6 8 9
则347125689为346987521的下一个排列;
vector<string> permutation(string str)
{
vector<string> v;
if(str.empty())
return v;
int length=str.size();
int fromIndex, changeIndex;
sort(str.begin(), str.end()); //先升序排列,获取最小的字符串组合
do
{
//保存当前获得的一种全排列组合
v.push_back(str);
fromIndex = length - 1;
//(1)向前查找第一个由大变小的元素位置
while (fromIndex > 0 && str[fromIndex] <= str[fromIndex - 1])
--fromIndex;
changeIndex = fromIndex;
if (fromIndex == 0)
break;
//(2)向后查找最后一个大于words[fromIndex-1]的元素
while (changeIndex + 1< length && str[changeIndex + 1] >= str[fromIndex - 1])
++changeIndex;
//(3)交换两个值
swap(str[fromIndex - 1], str[changeIndex]);
//(4)对后面的所有值进行反向处理
reverse(str.begin()+fromIndex, str.end());
}
while (true);
return v;
}1,for循环将每个位置的数据交换到第一位
swap(1,1~5);
2,按相同的方式全排列剩余的位;
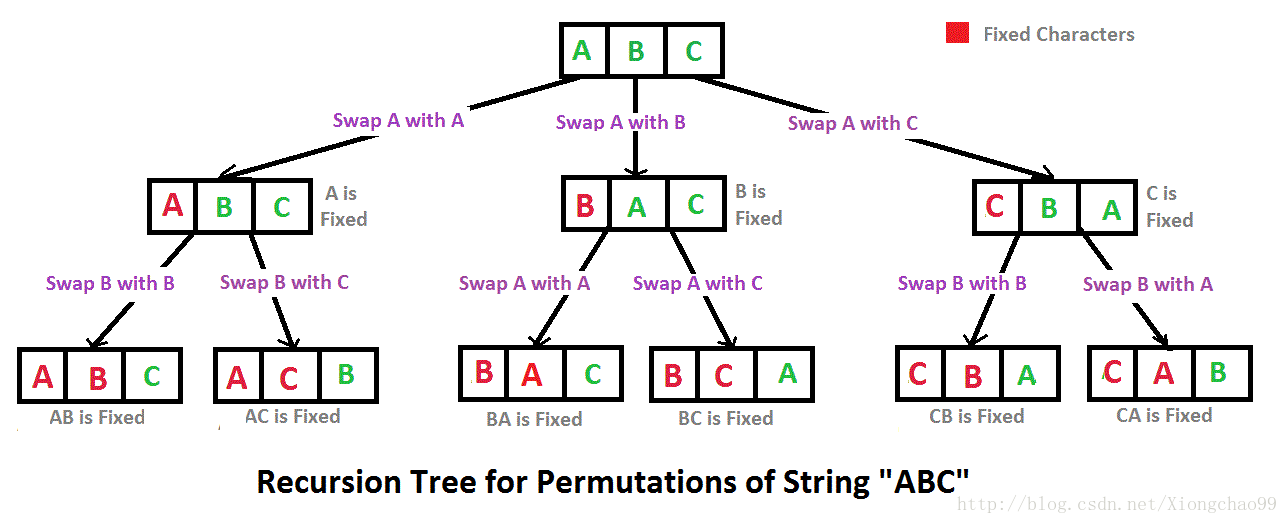
void PermutationHelp(vector<string> &ans, int k, string str) //遍历第k位的所有可能
{
if(k == str.size() - 1)
ans.push_back(str);
for(int i = k; i < str.size(); i++)
{
if(i != k && str[k] == str[i])
continue;
swap(str[i], str[k]);
PermutationHelp(ans, k + 1, str);
}
}
vector<string> Permutation(string str) {
sort(str.begin(), str.end());
vector<string> ans;
PermutationHelp(ans, 0, str);
return ans;
}28、单链表的反转算法
答:思想:创建3个指针,分别指向上一个节点、当前节点、下一个节点,遍历整个链表的同时,将正在访问的节点指向上一个节点,当遍历结束后,就同时完成了链表的反转。
实现代码:
ListNode* ReverseList(ListNode* pHead) {
ListNode *p,*q,*r;
if(pHead==NULL || pHead->next==NULL){
return pHead;
}else{
p=pHead;
q=p->next;
pHead->next=NULL;
while(q!=NULL){
r=q->next;
q->next=p;
p=q;
q=r;
}
return p;
}
}29、栈作为辅助结构的经典算法

②当前要进栈元素>stackMin栈顶元素时,stackMin栈把当前stackMin的栈顶元素再压入一遍;
int popBottom(Stack<Integer> stack){
int result = stack.pop();
if(stack.isEmpty()){//弹出一个栈顶元素后,栈为空了,表示该元素就是栈底元素
return result;
}else{
int last = popBottom(stack);
stack.push(result);//注意!!!这里是把前面拿到的元素压入,这样栈底元素才不会再次压入到栈中
return last;
}
} 30、队列作为辅助结构的经典算法
31、将二叉搜索树转化为双向链表,不允许创建新节点和其他数据结构辅助
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};
TreeNode* Tree2List(TreeNode* pRootOfTree){
TreeNode *Node;
if(pRootOfTree->left==NULL && pRootOfTree->right==NULL)//叶子就返回,否则继续下面的递归
return pRootOfTree;
//思想:无论左右子树,都返回子树中最大的节点(左子树最大节点是左子树根,右子树最大节点是右子树最靠右的节点)
if(pRootOfTree->left!=NULL)
{
Node=Tree2List(pRootOfTree->left);
pRootOfTree->left=Node; //将当前节点链接在左子树最大节点右边
Node->right=pRootOfTree;
Node=pRootOfTree; //(1)返回当前树的最大节点(当前树的根节点)
}
if(pRootOfTree->right!=NULL)
{
Node=Tree2List(pRootOfTree->right);//(2)子树返回值(最大节点)
TreeNode *temNode=Node;
while(temNode->left!=NULL)//获取右子树最小节点
temNode=temNode->left;
pRootOfTree->right=temNode;//将当前节点链接在右子树最小节点的左边
temNode->left=pRootOfTree;
}
return Node; //最后返回当前树的最大节点(无右子树就返回根节点(1),有右子树就返回右子树最大节点(2))
}
TreeNode* Convert(TreeNode* pRootOfTree)
{
if(pRootOfTree==NULL)
return NULL;
TreeNode* node=Tree2List(pRootOfTree);
while(node->left!=NULL) //要求返回最左边第一个节点,所以作如下操作
node=node->left;
return node;
}32、整数中1出现的次数
(2)当m表示百位,且百位对应的数为1,如n=31156,m=100,则a=311,b=56,此时百位对应的就是1,则共有a/10(不加1,即最高两位0-30)次是包含100个连续点。当最高两位为31(即a=311),本次只对应局部点00~56,共b+1次,所有点加起来共有(a%10*100)+(b+1),这些点百位对应为1;
(3)当m表示百位,且百位对应的数为0,如n=31056,m=100,则a=310,b=56,此时百位为1的次数有a/10=31(不加1,最高两位0~30);
int NumberOf1Between1AndN_Solution(int n)
{
int ones = 0;
for (int m = 1; m <= n; m *= 10) {
int a = n/m, b = n%m;
ones += (a + 8) / 10 * m + (a % 10 == 1) * (b + 1);
}
return ones;
}33、把数组元素连接成最小的数值
static bool cmp(int a,int b){
string A="";
string B="";
A=A+to_string((long long)a);
A=A+to_string((long long)b);
B=B+to_string((long long)b);
B=B+to_string((long long)a);
return A<B;
}
string PrintMinNumber(vector<int> numbers) {
sort(numbers.begin(),numbers.end(),cmp);
string resStr;
for(int k=0;k<numbers.size();k++){
resStr+=to_string((long long)numbers[k]);
}
return resStr;
}34、获取第n个丑数
int GetUglyNumber_Solution(int index) {
vector<int> res(index);
res[0] = 1;
int t2 = 0, t3 = 0, t5 = 0, i;
for (i = 1; i < index; ++i)
{
res[i] = min(res[t2] * 2, min(res[t3] * 3, res[t5] * 5));
if (res[i] == res[t2] * 2)t2++;
if (res[i] == res[t3] * 3)t3++;
if (res[i] == res[t5] * 5)t5++;
}
return res[index - 1];
}35、逆序对
int mergeSort(vector<int>& data, int start, int end) {
// 递归终止条件
if(start >= end) {
return 0;
}
// 递归
int mid = (start + end) / 2;
int leftCounts = mergeSort(data, start, mid);
int rightCounts = mergeSort(data, mid+1, end);
// 归并排序,并计算本次逆序对数
vector<int> copy(data); // 数组副本,用于归并排序
int foreIdx = mid;// 前半部分的指标
int backIdx = end;// 后半部分的指标
int counts = 0;// 记录本次逆序对数
int idxCopy = end;// 辅助数组的下标
while(foreIdx>=start && backIdx >= mid+1) {
if(data[foreIdx] > data[backIdx]) {
copy[idxCopy--] = data[foreIdx--];
counts += backIdx - mid;
} else {
copy[idxCopy--] = data[backIdx--];
}
}
while(foreIdx >= start) {
copy[idxCopy--] = data[foreIdx--];
}
while(backIdx >= mid+1) {
copy[idxCopy--] = data[backIdx--];
}
for(int i=start; i<=end; i++) {
data[i] = copy[i];
}
return (leftCounts+rightCounts+counts);
} vector<int> maxInWindows(const vector<int>& a, int k){
vector<int> res;
deque<int> d;
for(int i = 0; i < a.size(); ++i){
while(d.size()>0 && a[d.back()] <= a[i])
d.pop_back();
if(d.size()>0 && i - d.front() + 1 > k)
d.pop_front();
d.push_back(i);
if(k>0 && i+1 >= k)
res.push_back(a[d.front()]);
}
return res;
}37、数据流中的中位数
priority_queue<int> qmax;
priority_queue<int,vector<int>,greater<int>> qmin;
void Insert(int num){
if(qmin.size()>0 && num>qmin.top())
qmin.push(num);
else
qmax.push(num);
if(qmax.size()>= qmin.size()+2){
qmin.push(qmax.top());
qmax.pop();
}else if(qmin.size()>= qmax.size()+2){
qmax.push(qmin.top());
qmin.pop();
}
}
double GetMedian(){
if(qmax.size()==qmin.size())
return (qmax.top()+qmin.top())/2.0;
else
return qmax.size()>qmin.size()? qmax.top():qmin.top();
}38、快速幂
double Power(double base, int exponent) {
if(exponent==0)
return 1;
if(base==0)
return 0;
double result=1;
if(exponent>0){
result=Power(base*base,exponent/2);//每一次递归调用函数,base的值就变为上一层base的2次方
if(exponent%2!=0)
result=result*base;
}
else if(exponent<0){//考虑正负次幂,将负数次幂变为正数次幂计算
base=1/base;
exponent=-1*exponent;
result=Power(base,exponent);
}
return result;
}
39、中兴笔试——加密方法
unsigned long long GetBigMod(int x,int n,int mod){
if(n==0)
return 1;
int p=mod;
unsigned long long tmp=GetBigMod(x*x%p,n/2,p);
if(n%2!=0)
tmp=tmp*x%p;
return tmp;
}
int GetJiami(int x,int n,int m){
int p1=10,p2=1000000007;
return GetBigMod(GetBigMod(x,n,p1),m,p2);
}














 332
332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









