









详情请参考博客: Top 50 matplotlib Visualizations;Matplotlib Examples
因编译更新问题,本文将稍作更改,以便能够顺利运行。
1 Waffle Chart
华夫格图可以使用 pywaffle 包创建,用于显示较大群体中群体的组成。
新建文件Waffle Chart.py:
import pandas as pd
import matplotlib.pyplot as plt
from pywaffle import Waffle
plt.rcParams["figure.figsize"] = [7.00, 3.50]
plt.rcParams["figure.autolayout"] = True
data = {'books': ['physics', 'chemistry', 'math', 'english', 'hindi'],
'price': [80, 87, 89, 56, 39]
}
df = pd.DataFrame(data)
fig = plt.figure(
FigureClass=Waffle,
rows=5,
values=df.price,
labels=list(df.books)
)
plt.show()
运行结果为:
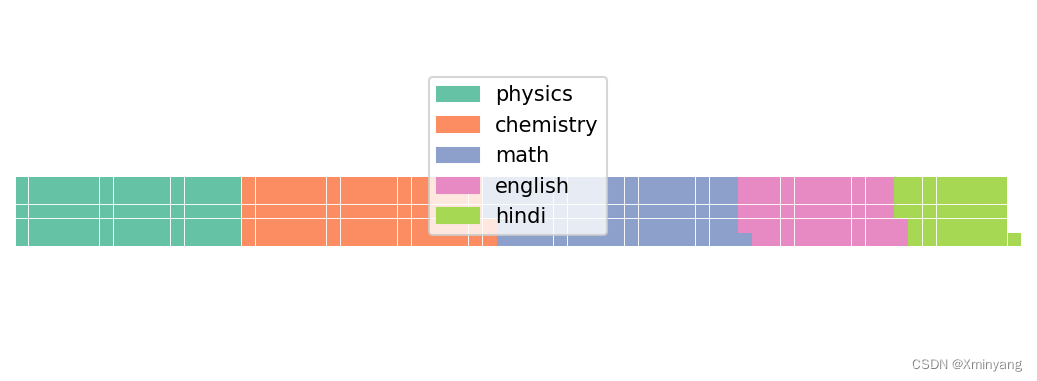
Reference code: 如何在Python Matplotlib中创建华夫格图(Waffle Chart)
2 Pie Chart
饼状图是显示组组成的经典方法。但是,现在通常不建议使用,因为饼部分的面积有时会产生误导。因此,如果您要使用饼状图,强烈建议明确写下饼状图每个部分的百分比或数字。
新建文件Pie Chart.py:
# Import Setup
from Setup import pd
from Setup import plt
# Import
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('class').size()
# Make the plot with pandas
df.plot(kind='pie', subplots=True, figsize=(8, 8))
plt.title("Pie Chart of Vehicle Class - Bad")
plt.ylabel("")
plt.show()
运行结果为:
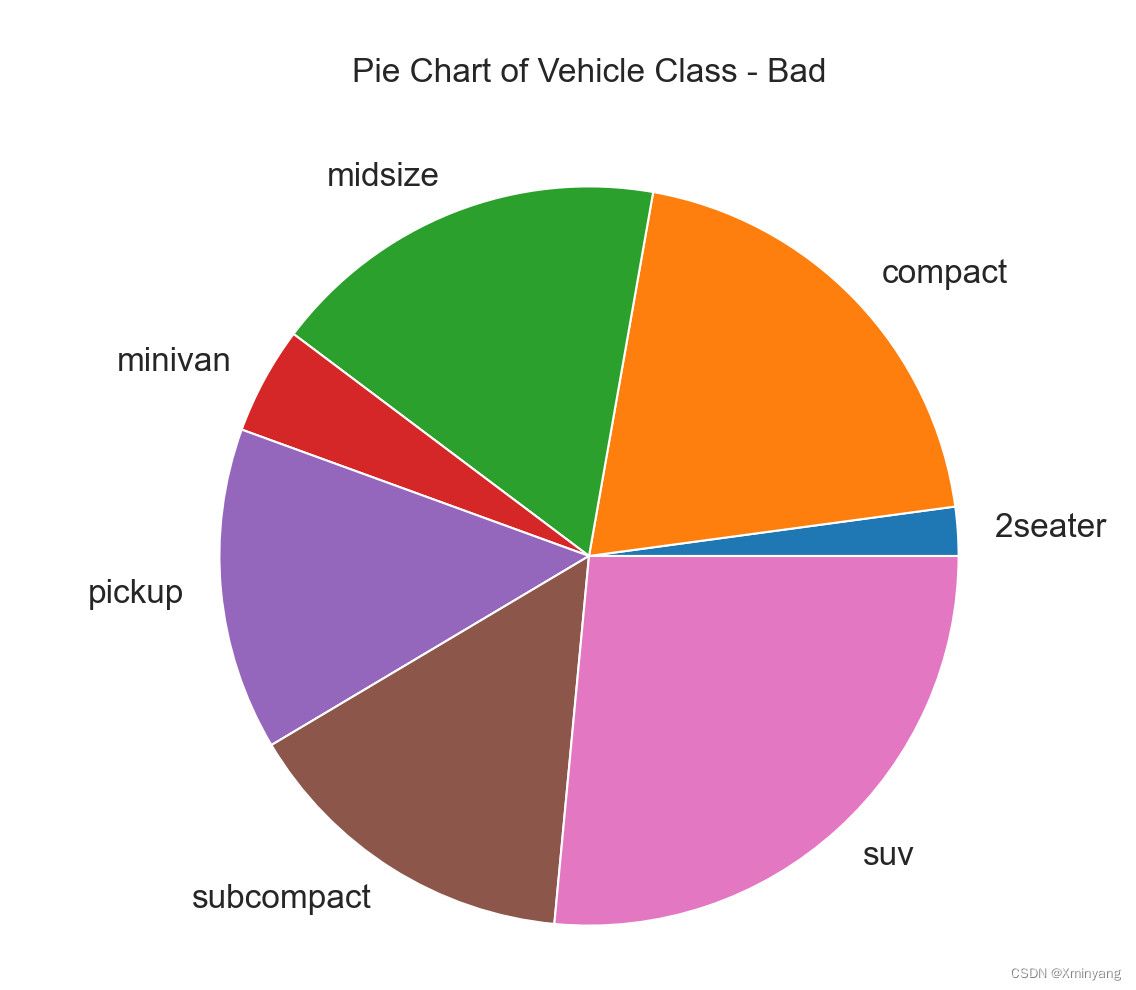
3 Treemap
树状图类似于饼状图,它的工作效果更好,不会误导每个组的贡献。
新建文件Treemap.py:
# Import Setup
from Setup import pd
from Setup import plt
# pip install squarify
import squarify
# Import Data
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('class').size().reset_index(name='counts')
labels = df.apply(lambda x: str(x[0]) + "\n (" + str(x[1]) + ")", axis=1)
sizes = df['counts'].values.tolist()
colors = [plt.cm.Spectral(i/float(len(labels))) for i in range(len(labels))]
# Draw Plot
plt.figure(figsize=(12,8), dpi= 80)
squarify.plot(sizes=sizes, label=labels, color=colors, alpha=.8)
# Decorate
plt.title('Treemap of Vechile Class')
plt.axis('off')
plt.show()
运行结果为:
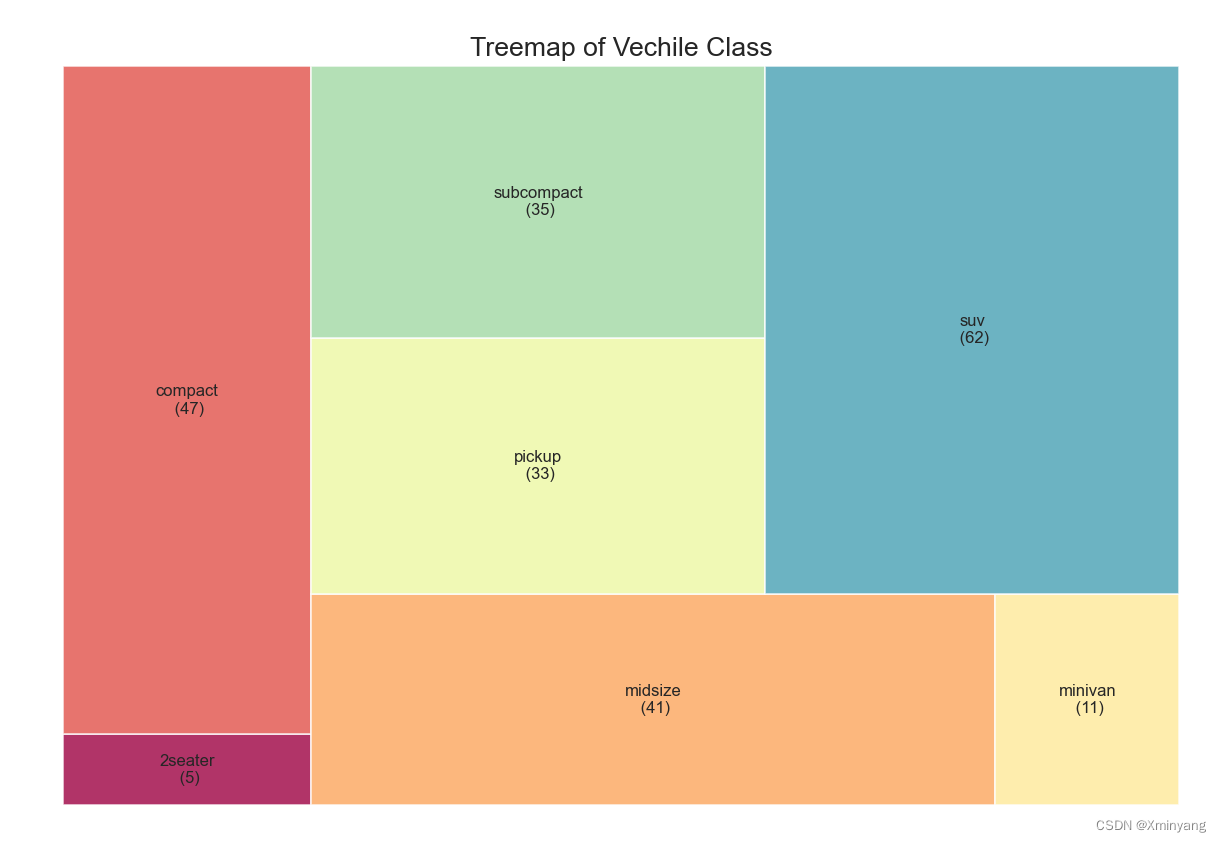
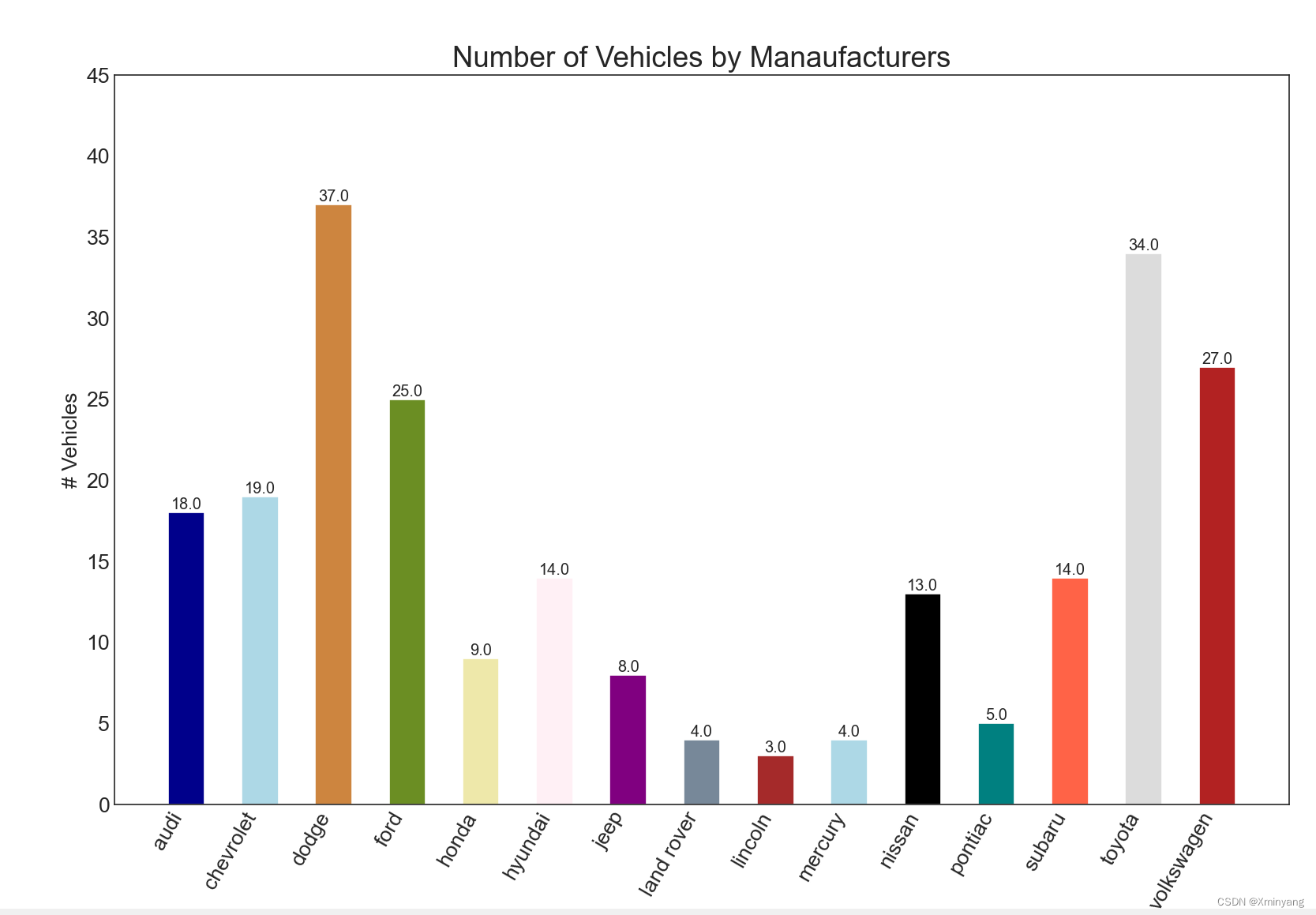
4 Bar Chart
条形图是根据计数或任何给定指标可视化项目的经典方式。在下图中,我为每个项目使用了不同的颜色,但您通常可能希望为所有项目选择一种颜色,除非您按组为它们着色。在下面的代码中,颜色名称存储在 all_colors 中。您可以通过在 plt.plot() 中设置颜色参数来更改条形的颜色。
新建文件Bar Chart.py:
# Import Setup
from Setup import pd
from Setup import plt
import random
# Import Data
df_raw = pd.read_csv("https://github.com/selva86/datasets/raw/master/mpg_ggplot2.csv")
# Prepare Data
df = df_raw.groupby('manufacturer').size().reset_index(name='counts')
n = df['manufacturer'].unique().__len__()+1
all_colors = list(plt.cm.colors.cnames.keys())
random.seed(100)
c = random.choices(all_colors, k=n)
# Plot Bars
plt.figure(figsize=(16,10), dpi= 80)
plt.bar(df['manufacturer'], df['counts'], color=c, width=.5)
for i, val in enumerate(df['counts'].values):
plt.text(i, val, float(val), horizontalalignment='center', verticalalignment='bottom', fontdict={'fontweight':500, 'size':12})
# Decoration
plt.gca().set_xticklabels(df['manufacturer'], rotation=60, horizontalalignment= 'right')
plt.title("Number of Vehicles by Manaufacturers", fontsize=22)
plt.ylabel('# Vehicles')
plt.ylim(0, 45)
plt.show()
运行结果为:














 20万+
20万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









