






最近在工作中接触到了高频交易的场景,这种对于延迟要求极短,计算准确性和效率要求极高的需求场景很让我头疼,于是开始琢磨如何设计一个高频交易系统。我觉得核心需求,是对数据处理要求“快”。那么从最核心的需求入手,我调研起了如何让数据处理的效率变高,速度变快。
直到我注意到了 Nvidia 的 DPU 解决方案,和 DOCA 一些列的技术工具,我觉得问题可能有解,经过简单的一些学习,今天我通过完成一个示例来检验方案可行性。
DPA All To All 介绍(要做什么)
数据处理过程会大致经过以下环节,接口获取到信号,从磁盘地址读取数据加载到内存,CPU 拿到数据后开始计算,执行写入。这一传统环节中,从 CPU 发出指令到设备,到设备传输到 CPU(内存),再到 CPU 计算处理后写入内存,再返回设备接口,这每一个环节都是存在开销的,而高频交易要求低延迟,如果以上这些环节可以做优化,那么可以一定程度上提高数据处理效率。
DPA 就是这样一项技术,他将 CPU 的介入剥离开来,将原本需要通过 CPU 计算的数据,download 到 DPU 单元上来执行,这一步加速了数据的处理速度,并且释放了 CPU 的资源,可以让 CPU 专注于指令和调度任务。在 All to All 模式下,并行计算的效率还会被大大提高,这对交易系统来说非常重要,可以赋予系统同时分析和处理多个市场指标和交易机会,同时 All to All 模式还降低通信延迟,这一点其实至关重要,所以今天就以一个 DPA All to All 应用的简单示例,来初探一下这项技术。
首先,所谓的 All to All 是一种特定的集体通信操。在一个All-to-All操作中,每个进程都会向其他所有进程发送数据,并从每个进程接收数据。具体来说,假设有P个进程,每个进程都有一个数据缓冲区,那么:
- 进程
i会将它的缓冲区分成P个部分。 - 进程
i的每个部分将被发送到不同的进程。具体来说,第j部分将被发送到进程j。
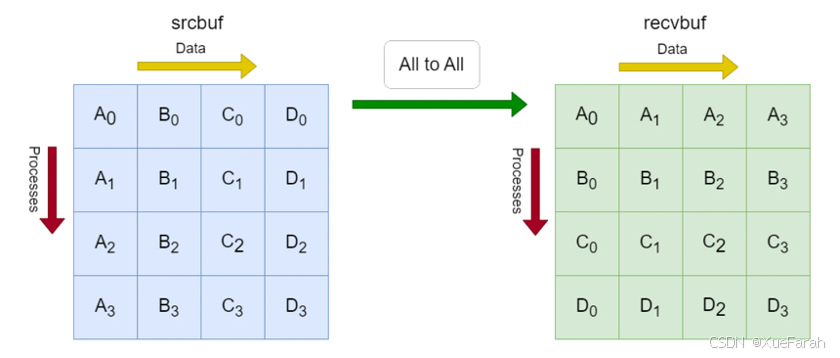
图中的每个进程将其本地sendbuf划分为n个块(本例中为4个),每个块包含sendcount元素(本例中为4个)。进程将其本地sendbuf的第 k个 块发送到进程k,进程k将数据放置在其本地recvbuf的第 i 个块中。使用DOCA DPA实现all-to-all方法将从srcbuf到recvbufs的元素复制卸载到DPA,并使CPU可以自由执行其他计算。
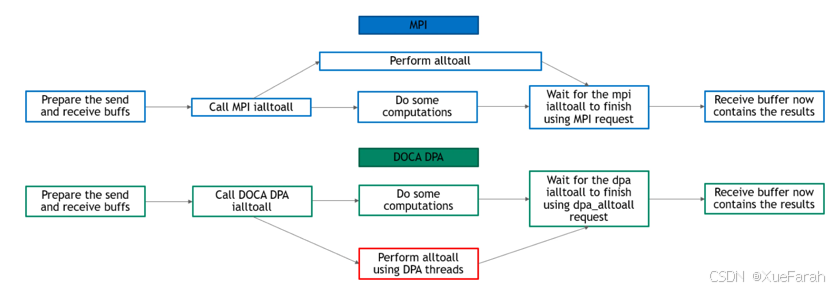
All to All 区别于 DPA 上的方式还有主机层面的 All to All,在 DPA All to All 中,DPA线程执行all-to-all,CPU可以自由执行其他计算;在基于主机的 All to All 中,CPU 在某些时候仍然必须执行数据传输任务,不能完全自由的进行其他计算。
操作步骤(怎么做)
首先,检查环境,环境中确保先装好了 DOCA 相关组件。比如 DOCA DPA、Open MPI 等。
dpkg -l |grep mpich
如果没有安装过,先执行安装操作
apt-get install mpich
之后,进入到工作目录,一般在 /opt/mellanox/doca/applications 目录下
cd /opt/mellanox/doca/applications
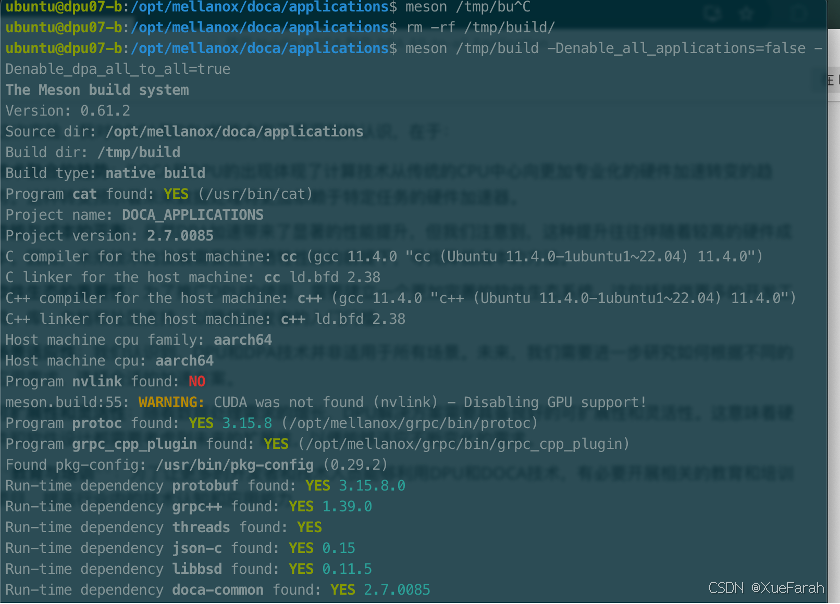
下一步进行编译,All to All 的应用示例和其他示例已经在这个目录下,我们执行
meson /tmp/build -Denbale_all_applications=false -Denable_dpa_all_to_all=true
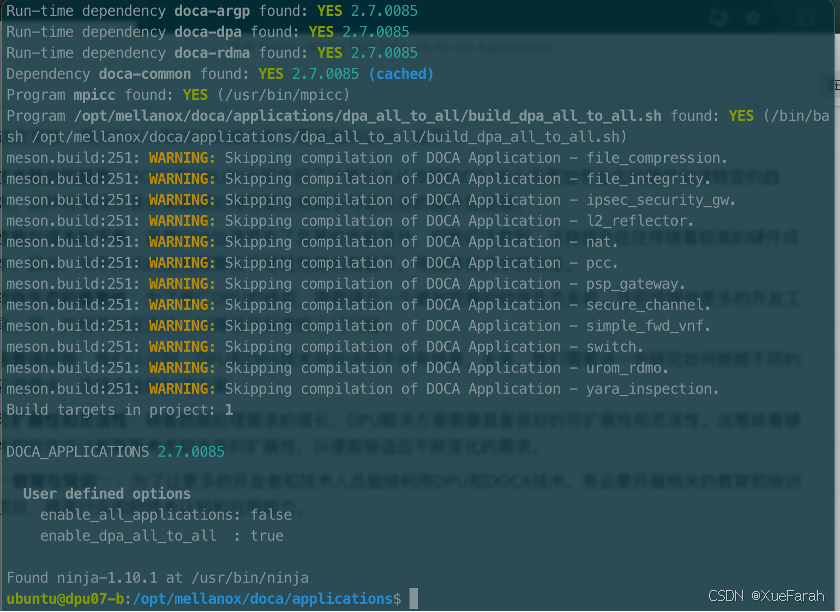
ninja -C /tmp/build
在编译这一步骤中,我们还有其他两种编译方式,一是将目录下的所有应用一起编译,二是通过 meson 配置文件来自定义编译:
meson /tmp/build
ninja -C /tmp/build
# or
vi meson_options.txt
meson /tmp/build
ninjia -C /tmp/build
在这一步执行好之后,就是运行我们编译的程序,首先,我们安装好的 doca_dpa_all_to_all 命令可以查看帮助指令:
Usage: doca_dpa_all_to_all [DOCA Flags] [Program Flags]
DOCA Flags:
-h, --help Print a help synopsis
-v, --version Print program version information
-l, --log-level Set the (numeric) log level for the program <10=DISABLE, 20=CRITICAL, 30=ERROR, 40=WARNING, 50=INFO, 60=DEBUG, 70=TRACE>
--sdk-log-level Set the SDK (numeric) log level for the program <10=DISABLE, 20=CRITICAL, 30=ERROR, 40=WARNING, 50=INFO, 60=DEBUG, 70=TRACE>
-j, --json <path> Parse all command flags from an input json file
Program Flags:
-m, --msgsize <Message size> The message size - the size of the sendbuf and recvbuf (in bytes). Must be in multiplies of integer size. Default is size of one integer times the number of processes.
-d, --devices <IB device names> IB devices names that supports DPA, separated by comma without spaces (max of two devices). If not provided then a random IB device will be chosen.
说明此时已经编译好了 DPA All to All 程序,接下来,我们要运行一个 MPI 程序来模拟发送数据,所以我们用 mpirun 来启动这个程序
mpirun -np 8 /tmp/build/dpa_all_to_all/doca_dpa_all_to_all
# or
mpirun -np 8 /tmp/build/dpa_all_to_all/doca_dpa_all_to_all -m 128 -d "mlx5_0,mlx5_1"
在这个命令中,np 指的是启动的进程数,m 参数指的是消息大小,d 参数可以指定运行任务的硬件模块,也就是 DPU。
以上所有步骤的操作演示截图如下

- 结果分析
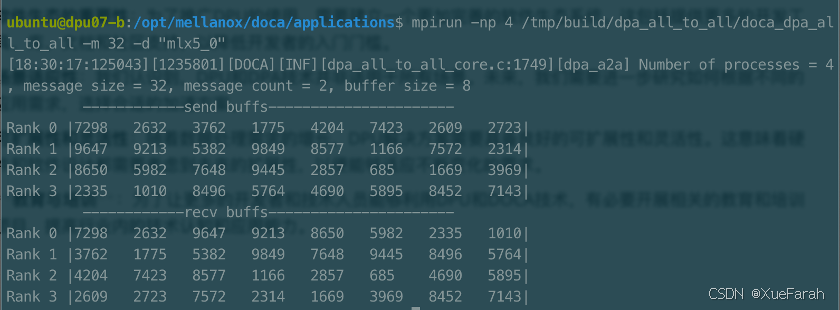
在 mpirun -np 4 /tmp/build/dpa_all_to_all/doca_dpa_all_to_all -m 32 -d "mlx5_0" 这个命令的结果中
[23:13:42:312301][1341358][DOCA][INF][dpa_all_to_all_core.c:1749][dpa_a2a] Number of processes = 4, message size = 32, message count = 2, buffer size = 8
------------send buffs----------------------
Rank 0 |3524 1653 7741 659 5558 2181 8612 8965|
Rank 1 |4496 8586 1840 8730 5289 2968 4642 9233|
Rank 2 |1517 3072 1405 4131 1639 3701 4401 7709|
Rank 3 |5770 2090 3468 5397 7735 5874 4607 2191|
------------recv buffs----------------------
Rank 0 |3524 1653 4496 8586 1517 3072 5770 2090|
Rank 1 |7741 659 1840 8730 1405 4131 3468 5397|
Rank 2 |5558 2181 5289 2968 1639 3701 7735 5874|
Rank 3 |8612 8965 4642 9233 4401 7709 4607 2191|
Rank 0 - 4 4 个进程分别有发送缓冲区和接收缓冲区,可以看到从 Rank1 发送出的 4496 这一条数据被 Rank0 的接收区收到,其他数据也都发到了其他进程中,这样就完成了一次 All to All 操作。进程间进行了一次数据通信,而通过 DPA 的这样加速,并行计算多进程任务中的数据交换就简单快速了很多,这多高频交易系统来说至关重要的。
体验总结
总体的示例体验还是很平滑的,可以借助这个示例快速直观的理解 DPA 在数据处理加速中的作用。不过在结合高频交易的真实场景中,我觉得还可能面临一系列考验,比如:
- 时间敏感性:高频交易的世界里,每一微秒都可能意味着盈利与亏损的差别。DPA All-to-All虽能提升数据处理速度,但如何进一步压缩通信延迟,成为我们首要攻克的难题。
- 数据同步的微妙平衡:在所有交易节点间实现数据的精确同步,是保证交易策略有效性的关键。我发现,即使在DPA All-to-All的加持下,数据一致性的维护仍需精心设计。
- 系统架构的复杂性:随着DPA All-to-All的集成,系统的复杂度也随之提升。如何在保持系统灵活性的同时,确保其稳定性和可维护性,成为接下来不得不面对的问题。
- 经济效益的权衡:在高性能的背后,是成本的考量。我们不得不仔细评估,DPA All-to-All带来的性能提升是否能够覆盖其昂贵的实现成本。
这些都是需要通过进一步实践来论证的,同时通过这次简单实践,还积累了一定经验,通过DPA All-to-All示例的学习,我深入理解了这种通信模式如何在多个节点之间实现高效的数据交换。这对于需要快速信息共享和同步的高频交易系统来说,是一个关键的技术点。实践过程中,亲眼见证了硬件加速(特别是DPA)在处理大规模并行通信时带来的性能提升。这对于时间敏感的高频交易来说,意味着更快的交易执行和更高的盈利潜力。在实现DPA All-to-All的过程中,我学习了如何设计和优化系统架构以支持高效的并行处理。这包括网络拓扑的选择、节点间的连接策略,以及数据流的优化。在高频交易系统中,有效地管理DPU资源是至关重要的。我了解到,合理分配和调度资源可以最大化硬件性能,同时降低运营成本。通过这次实践,我对DPU和DPA技术在高频交易领域的应用前景有了更深的洞察。我相信,随着技术的成熟和成本的降低,这类技术将在金融市场中发挥更大的作用。

















 1539
1539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









