






目录
post多个 WR 时,用list串起它们在一次post完成
避免使用原子操作|Avoid using atomic operations
一次Read多个WC|Read multiple Work Completions at once
为某个任务或进程绑核运行|Set processor affinity for a certain task or process
使用本地 NUMA 节点|Work with local NUMA node
使用内存对齐的buffer|Work with cache-line aligned buffers
避免进入重传流|Avoid getting into retransmission flows
2)增加带宽|Improving the Bandwidth
Find the best MTU for the RDMA device
Work with multiple outstanding Send Requests处理多个未完成的发送请求
Work with selective signaling in the Send Queue在发送队列中使用选择性信号
使用polling读取WC|Read Work Completions by polling
Send small messages as inline发送小消息作为内联
Use low values in QP's timeout and min_rnr_timer在 QP 的超时和 min_rnr_timer 中使用较低的值
If immediate data is used, use RDMA Write with immediate instead of Send with immediate
如果使用即时数据,使用带有即时的 RDMA 写入而不是带有即时的发送
4)减少内存消耗|Reducing memory consumption
Register physical contiguous memory注册物理连续内存
Reduce the size of the used Queues to the minimum将所用队列的大小降至最低
5)降低CPU使用率|Reducing CPU consumption
Work with Work Completion events使用Work Completion events
Work with solicited events in Responder side在响应方处理请求事件
6)增加可扩展性|Increase the scalability
Use Unreliable Datagram (UD) QP
参考:RDMA性能优化经验浅谈(一)https://zhuanlan.zhihu.com/p/522332998
二、基础概念背后的硬件执行方式和原理
RDMA性能优化理论依据
首先介绍一些核心概念,关注这些基础概念背后的硬件执行方式和原理,对于这些原理的理解是能够写出高性能RDMA程序的关键。
Memory Region
RDMA的网卡(下文以RNIC指代)通过DMA来读写系统内存,由于DMA只能根据物理地址访问,所以RNIC需要保存一份目标内存区域的[虚拟内存]到[物理内存]的映射表,这个映射表被存储在RNIC的MTT(Memory Translation Table,内存翻译表)中。同时,由于目前RDMA的访问大都基于Direct Cache Access,不支持page-fault,所以我们还需要保证目标内存区域是被pagelock住以防止操作系统将这部分内存页换出(注册内存的目的)。
总结一下就是,使用RDMA来访问一块内存前,这块内存首先要被pagelock,接着把这块[内存虚拟地址]到[逻辑地址]的映射表发送给RNIC缓存起来,用于后续的访问查找,这个过程就叫Memory Registeration(内存注册),这块被注册的内存就是Memory Region。
同时我们注册内存的时候需要指定这块内存的访问权限,RNIC将这个访问权限信息存储在MPT(Memory Protection Tables)中用于用户请求时的权限验证。
MTT和MPT被存储在内存中,但是RNIC的SRAM中会进行缓存。当RNIC接收到来自用户的READ/WRITE请求的时候,首先在SRAM中的缓存中查找用户请求的目标地址对应的物理地址以及这块地址对应的访问权限,如果缓存命中了,就直接基于DMA进行操作,如果没有命中,就得通过PCIe发送请求,在内存的MTT和MPT中进行查找,这带来了相当的额外开销,尤其是当你的应用场景需要大量的、细粒度的内存访问的时候,此时RNIC SRAM中的MTT/MPT命中缺失带来的影响可能是致命的。
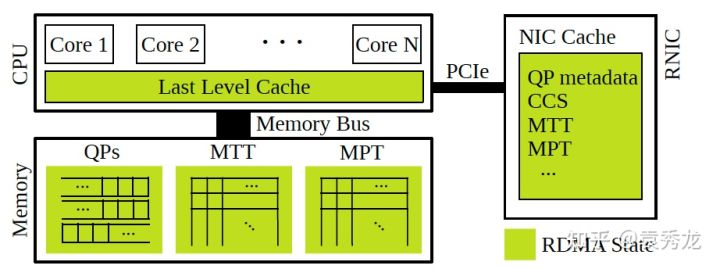
Memory Region的注册是一个耗时的操作,但大部分情况下,我们都只需要在最开始的时候做一次或者多次。现在也有不需要注册MR基于on-demand paging的方式来访问的,比如AWS的EFA协议。但今天先不展开这块的内容,因为这块更多是Unified Memory这个话题下的,之后我可能会把这个和GPU的UVM放在一起介绍下,因为他们的核心原理其实是一样的。
RDMA Verbs
用户通过RDMA的Verbs API向RNIC发送指令,Verbs分为Memory Verbs和Message Verbs,Memory Verbs主要就是READ、WRITE以及一些ATOMIC的操作,Message Verbs主要包含SEND、RECV。Memory verbs是真正的CPU Bypass以及Kernel Bypass,所以总归是性能比较好的。Message Verbs需要Responder的CPU的参与,相对而言更灵活,但是性能相比Memory Verbs而言一般不太行。
Queue Pair
RDMA的hosts之间是通过Queue Pair(QP)来通信的,一个QP包含一个Send Queue(SQ),一个Receive Queue(RQ)以及对应的Send Completion Queue(SCQ)和Receive Completion Queue(RCQ)。用户发送请求的时候,把请求封装为一个Work Queue Element(WQE)发送到SQ里面,然后RDMA网卡会把这个WQE发送出去,当这个WQE完成的时候,对应的SCQ里面会被放一个Completion Queue Element(CQE),然后用户可以从SCQ里面Poll这个CQE并通过检查状态来确认对应的WQE是否成功完成。需要指出的是,不同的QP可以共用CQ来减少SRAM的存储消耗。
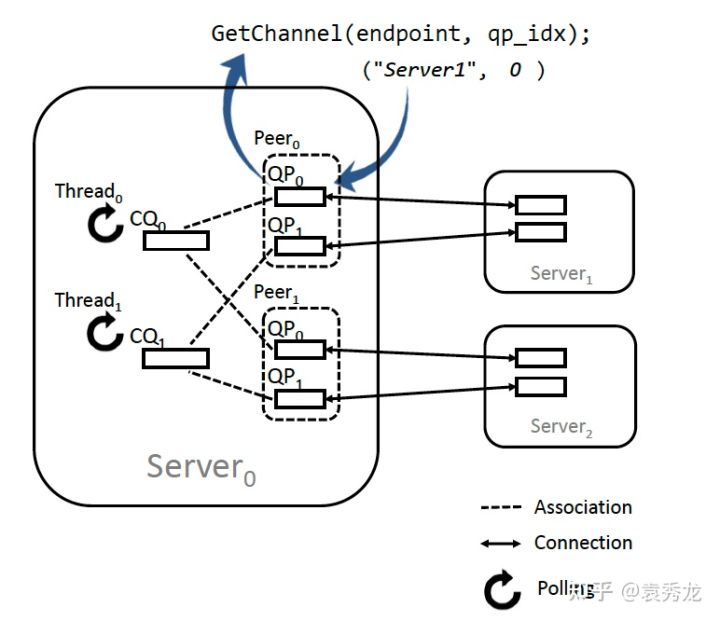
接下来,我们重点介绍一下QP背后的知识。
首先,当我们创建了QP之后,系统是需要保存状态数据的,比如QP的metadata,拥塞控制状态等等,除去QP中的WQE、MTT、MPT,一个QP大约对应375B的状态数据。这在以前RNIC的SRAM比较小的时候会是一个比较重的存储负担,所以以前的RDMA工作会有QP Sharing的研究,就是不同的处理线程去共用QP来减少meta data的存储压力,但是这会带来一定的性能的损失[1]。现在新的RNIC的SRAM已经比较大了,Mellanox的CX4、CX5系列的网卡的SRAM大约2MB,所以现在新网卡上,当规模不是很大时大家还是比较少去关注QP带来的存储开销,除非你要创建几千个,几万个QP。
其次,RNIC是包含多个Processing Unit(PU)的[2],同时由于QP内的请求处理是具有顺序的,且为了避免cross-PU的同步,一般而言我们认为一个QP对应一个PU来处理。所以,我们可以在一个线程内建立多个QP来加速你数据处理,避免RDMA程序性能瓶颈卡在PU的处理上[3]。
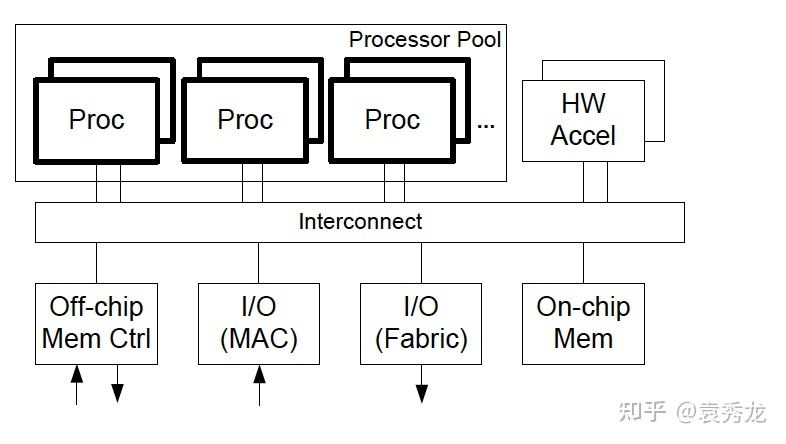
三、RDMA性能优化
1 优化思路
RDMA性能优化这个东西说复杂也复杂,说简单也简单。简单的点在于,从性能优化角度而言,其实软件层面我们可以做的设计和选择不会太多,因为性能上限是被硬件卡住的,所以我们为了追求尽可能逼近硬件上限的性能表现,其核心就在于按照硬件最友好的方式去做数据访问即可,没有特别多复杂的算法在这里面,当你想要高性能的时候,多多了解硬件就对了。对照着我们在上面介绍的三个核心概念,我们一一介绍性能优化的经验。
3.1 关注地址翻译的性能开销
前面我们提到,当待请求的数据地址在RNIC SRAM中的MTT/MPT没有命中的时候,RNIC需要通过PCIe去在内存中的MTT和MPT进行查找,这是一个耗时的操作。尤其是当我们需要 high fan-out(高扇出)、fine-grained(细粒度)的数据访问时,这个开销会尤为的明显。现有针对这个问题的优化方式主要有两种:
- Large Page:无论是MTT亦或者操作系统的Page Table,虚拟地址到物理地址的映射表项是Page粒度的,即一个Page对应一个MTT的Entry或者Page Table的Entry(PTE)。使用Large Page可以有效的减少MTT的Size,进而使得RNIC中的MTT Cache命中率更高。
- 使用Contiguous Memory + PA-MR[4, 5]。新一代的CX网卡支持用户基于物理地址访问,为了避免维护一个繁重的Page Table,我们可以通过Linux的CMA API来申请一大块连续的物理内存。这样我们的MTT就只有一项,可以保证100%的Cache命中率。但是这个本身有一些安全隐患,因为使用PA-MR会绕过访问权限验证,所以使用的时候要注意这点。
当然,其实还有一些别的优化手段,在最近我们的工作中提出一种新的方式来提升地址翻译的性能,具体等工作开源出来之后我再来介绍介绍。
3.2 关注RNIC PU/QP的执行模型
一个QP对应一个PU,这是我们对RNIC执行方式的一个简单建模。这个模型下,我们需要通过多QP来充分发挥多PU并行处理的能力,同时也要关注我们的操作减少PU之间的同步,PU之间同步对于性能有着较大的伤害。
3.3 RMDA Verbs
对于RDMA的Verbs的使用,以我个人的经验来看,就是优先使用READ/WRITE,在一些需要CPU介入且需要Batch处理逻辑的,可以尝试使用SEND/RECV。过往的工作有很多基于READ/WRITE去构建Message Passing处理语义的工作[1, 6, 7],可以着重参考。
同时,一个READ/WRITE的WQE可以通过设置对应的FLAG来设置其是否需要在完成时需要被SIGNALED,如果不需要则该WQE完成时不会产生一个CQE。此时一个常见的优化技巧是,当你需要连续在一个QP中发送K个READ/WRITE请求时,只把最后一个请求设置为SIGNALED,其他均为UNSIGNALED,由于QP的执行本身具备顺序关系,所以最后一个执行完了后一定意味着之前的WQE都已经执行完了。当然,是否执行成功需要Application-Specific的方法来确认。
2 优化技巧
RDMA is used in many places, mainly because of the high performance that it allows to achieve. In this post, I will provide tips and tricks on how to optimize RDMA code in several aspects.
1)一般建议
避免在数据路径中使用控制操作
Unlike the data operations that stay in the same context that they were called in (i.e. don't perform a context switch) and they are written in optimized way, the control operations (all create/destroy/query/modify) operations are very expensive because:
- Most of the time, they perform a context switch
- Sometimes they allocate or free dynamic memory
- Sometimes they involved in accessing the RDMA device
As a general rule of thumb, one should avoid calling control operations or decrease its use in the data path.
The following verbs are considered as data operations:
与调用时保持在同一上下文中的数据操作(即不执行上下文切换)并且以优化的方式编写不同,控制操作(所有创建/销毁/查询/修改操作)非常昂贵,原因在于:
- 大多数情况下,它们会执行一次上下文切换
- 有时它们会分配或释放动态内存
- 有时候它们涉及到访问RDMA设备
作为一个通用的经验法则,在数据路径中应该避免调用控制操作或减少其使用。
以下动词被视为数据操作:
- ibv_post_send()
- ibv_post_recv()
- ibv_post_srq_recv()
- ibv_poll_cq()
- ibv_req_notify_cq
post多个 WR 时,用list串起它们在一次post完成
(When posting multiple WRs, post them in a list in one call)
When posting several Work Requests to one of the ibv_post_*() verbs, posting multiple Work Requests as a linked list in one call instead of several calls each time with one Work Request will provide better performance since it allows the low-level driver to perform optimizations.
当向 ibv_post_*() 函数之一提交多个工作请求时,一次性以链表的形式提交多个工作请求,而不是每次提交一个工作请求进行多次调用,可以提供更好的性能,因为这允许低层驱动程序执行优化。
处理WC时,不要一个一个回复,攒几个再一次同时回复多个
(When using Work Completion events, acknowledge several events in one call)
When handling Work Completions using events, acknowledging several completions in one call instead of several calls each time will provide better performance since less mutual exclusion locks are being performed.
避免使用许多聚散表条目
(Avoid using many scatter/gather entries)
Using several scatter/gather entries in a Work Request (either Send Request or Receive Request) mean that the RDMA device will read those entries and will read the memory that they refer to. Using one scatter/gather entry will provide better performance than more than one.
在WR(发送请求SR或接收请求RR)中使用多个分散/收集item,意味着 每个item RDMA 网卡有两次读内存的操作,第一次读取这些item本身,第二不根据item中描述信息取它们描述的内存。使用一个分散/聚集item将提供比多个item更好的性能(减少了分两次读取的次数)。
避免使用 Fence|Avoid using Fence
Send Request with the fence flag set will be blocked until all prior RDMA Read and Atomic Send Requests will be completed. This will decrease the BW.
发送带有 fence 标志的请求将被阻塞,直到所有先前的 RDMA Read 和 Atomic Send 请求完成。这会降低带宽。
避免使用原子操作|Avoid using atomic operations
Atomic Operations allow to perform read-modify-write in an atomic way. This usually will decrease the performance since doing this usually involved in locking the access to the memory (implementation dependent).
原子操作允许以原子的方式执行读-修改-写操作。这通常会降低性能,因为这样做通常涉及锁定对内存的访问(具体实现依赖)。
一次Read多个WC|Read multiple Work Completions at once
ibv_poll_cq() allows to reading multiple completions at once. If the number of Work Completions in the CQ is less than the number of Work Completion that one tried to read, it means that the CQ is empty and there isn't any need to check if there are more Work Completions in it.
ibv_poll_cq() 允许一次读取多个wc。如果 CQ 中的 Work Completion 数量小于尝试读取的 Work Completion 数量,则表示 CQ 为空,无需检查其中是否有更多的 Work Completion。
为某个任务或进程绑核运行|Set processor affinity for a certain task or process
When working with a Symmetric MultiProcessing (SMP) machines, binding the processes to a specific CPU(s)/core(s) may provide better utilization of the CPU(s)/core(s) thus provide better performance. Executing processes as the number of CPU(s)/core(s) in a machine and spread a process to each CPU(s)/core(s) may be a good practice. This can be done with the "taskset" utility.
在操作对称多处理(SMP)机器时,将进程绑定到特定的 CPU/核心可能会更好地利用这些 CPU/核心,从而提供更好的性能。在机器中以 CPU/核心的数量执行进程,并将进程分布到每个 CPU/核心上可能是一个好的实践。这可以通过 “taskset” 工具来完成。
使用本地 NUMA 节点|Work with local NUMA node
When working on a Non-Uniform Memory Access (NUMA) machines, binding the processes to CPU(s)/core(s) which are considered local NUMA nodes for the RDMA device may provide better performance because of faster CPU access. Spreading the processes to all of the local CPU(s)/core(s) may be a good practice.
在操作非统一内存访问(NUMA)机器时,将进程绑定到被认为是 RDMA 设备的本地 NUMA 节点的 CPU/核心可能会提供更好的性能,因为 CPU 访问速度更快。将进程分布到所有本地 CPU/核心上可能是一个好的实践。
使用内存对齐的buffer|Work with cache-line aligned buffers
Working with cache-line aligned buffers (in S/G list, Send Request, Receive Request and data) will improve performance compared to working with unaligned memory buffers; it will decrease the number of CPU cycles and number of memory accesses.
使用缓存行对齐的缓冲区(在 S/G 列表、发送请求、接收请求和数据中)将比使用未对齐的内存缓冲区提高性能;它会减少 CPU 周期和内存访问次数。
避免进入重传流|Avoid getting into retransmission flows
Retransmission is a performance killer. There are 2 major reasons for retransmission in RDMA:
- Transport retransmission - remote QP isn't at a state that can process incoming messages, i.e. didn't get to, at least, RTR state, or moved to Error state
- RNR retransmission - there is a message that should consume a Receive Request in the responder side, but there isn't any Receive Request in the Receive Queue
There are RDMA devices that provide counters to indicate that retry flows occurred, but not all of them.
Setting QP.retry_cnt and QP.rnr_retry to zero will cause a failure (i.e. Completion with error) when the QP enters those flows.
However, if retry flows can't be avoided, use low (as possible) delay between the retransmission.
有些 RDMA 设备提供了计数器来指示重试流程的发生,但并非所有设备都提供这些计数器。
将 QP.retry_cnt 和 QP.rnr_retry 设置为零会导致 QP 进入这些流程时失败(即出现错误完成)。
然而,如果无法避免重试流程,应尽量缩短重传之间的延迟。
2)增加带宽|Improving the Bandwidth
Find the best MTU for the RDMA device
The MTU value specifies the maximum packet payload size (i.e. excluding the packet headers) that can be sent. As a rule of thumb since the packet header sizes are the same for all MTU values, using the maximum available MTU size will decrease the "paid price" per packet; the percent of the payload data in the total used BW will be increased. However, there are RDMA devices which provide the best performance for MTU values which are lower than the maximum supported value. One should perform some testing in order to find the best MTU for the specific device that he works with.
Use big messages
Sending a few big messages is more effective than sending a lot of small messages. In application level one should collect data and send big messages over RDMA.
发送几条大消息比发送大量小消息更有效。在应用层,应该收集数据并发送大消息通过 RDMA。
Work with multiple outstanding Send Requests处理多个未完成的发送请求
Working with multiple outstanding Send Requests and keeping the Send Queue always full (i.e. for every polled Work Completion post a new Send Request) will keep the RDMA device busy and prevents it from being idle.
保持多个未完成的发送请求并始终保持发送队列满(即,每轮询一个工作完成就提交一个新的发送请求)将使 RDMA 设备保持忙碌状态,防止其空闲。
Configure the Queue Pair to allow several RDMA Reads and Atomic in parallel配置队列对以允许多个 RDMA 读取和原子操作并行进行
If one uses RDMA Read or Atomic operations, it is advised to configure the QP to work with several RDMA Read and Atomic operations in flight since it will provide higher BW.
如果使用 RDMA 读取或原子操作,建议配置队列对(QP)以支持多个 RDMA 读取和原子操作同时进行,这将提供更高的带宽。
Work with selective signaling in the Send Queue在发送队列中使用选择性信号
Working with selective signaling in the Send Queue means that not every Send Request will produce a Work Completion when it ends and this will reduce the number of Work Completions that should be handled.
在发送队列中使用选择性信号意味着并非每个发送请求在结束时都会生成一个工作完成,这将减少需要处理的工作完成的数量。
3)减少延迟|Reducing the latency
使用polling读取WC|Read Work Completions by polling
为了尽快将放入CQ的wc读出来,polling相比于event polling提供更好的结果。
In order to read the Work Completion as soon as they are added to the Completion Queue, polling will provide the best results (rather than working with Work Completion events).
为了在工作完成一添加到完成队列时就立即读取它们,polling 将提供最佳结果(而不是使用工作完成事件)。
Send small messages as inline发送小消息作为内联
In RDMA devices which supports sending data as inline, sending small messages as inline will provide better latency since it eliminates the need of the RDMA device to perform extra read (over the PCIe bus) in order to read the message payload.
在支持以内联方式发送数据的 RDMA 设备中,将小消息作为内联发送将提供更好的延迟,因为它消除了 RDMA 设备执行额外读取(通过 PCIe 总线)以读取消息负载的需要。
Use low values in QP's timeout and min_rnr_timer在 QP 的超时和 min_rnr_timer 中使用较低的值
Using lower values in the QP's timeout and min_rnr_timer means that in case that something gets wrong and retry is required (whether if because the remote QP doesn't answer or if it doesn't have outstanding Receive Request) the waited time before a retransmission will be short.
在 QP 的超时和 min_rnr_timer 中使用较低的值意味着,如果出现问题并且需要重试(无论是因为远程 QP 没有响应还是没有未完成的发送请求),在重新传输之前等待的时间将缩短。
If immediate data is used, use RDMA Write with immediate instead of Send with immediate
如果使用即时数据,使用带有即时的 RDMA 写入而不是带有即时的发送
When sending a message that has only immediate data, RDMA Write with immediate will provide better performance than Send With immediate since the latter causes the outstanding posted Receive Request to be read (in the responder side) and not only be consumed.
当发送仅包含即时数据的消息时,带有即时的 RDMA Write 将比带有即时的Send 提供更好的性能,因为后者会导致未完成的发送请求被读取(在响应方),而不仅仅是被消费。
4)减少内存消耗|Reducing memory consumption
Use Shared Receive Queue (SRQ)使用共享接收队列(SRQ)
Instead of posting many Receive Requests for each Queue Pair, using SRQ can save the total number of outstanding Receive Request thus reduce the total consumed memory.
与为每个QP发布多个RQ相比,使用共享接收队列可以减少派发的RQ的总数,从而降低总内存消耗。
Register physical contiguous memory注册物理连续内存
Register physical contiguous memory, such as huge pages, can allow the low-level driver(s) to perform optimizations since lower amount of memory address translations will be required (compared to 4KB memory pages buffer).
注册物理连续内存(如大页内存)可以使底层驱动程序进行优化,因为这将减少所需的内存地址转换次数(与4KB内存页缓冲区相比)。
Reduce the size of the used Queues to the minimum将所用队列的大小降至最低
Creating the various Queues (Queue Pairs, Shared Receive Queues, Completion Queues) may consume a lot of memory. One should set the size of them to the minimum that is required by his application.
创建各种队列(队列对、共享接收队列、完成队列)可能会消耗大量内存。用户应将队列的大小设置为应用程序所需的最小值。
5)降低CPU使用率|Reducing CPU consumption
Work with Work Completion events使用Work Completion events
Reading the Work Completions using events will eliminate the need to perform constant polling on the CQ since the RDMA device will send an event when a Work Completion was added to the CQ.
通过事件读取工作完成状态,将无需持续polling 完成队列(CQ),因为当向CQ中添加一个工作完成时,RDMA设备会发送一个事件。
Work with solicited events in Responder side在响应方处理请求事件
When reading the Work Completions in the Responder side, the solicited event can be a good way to the Requestor to provide a hint that now is a good time to read the completions. This reduces the total number of handled Work Completions.
在响应方读取工作完成状态时,请求事件可以成为请求方获得提示的一个好方法,表明现在是读取完成状态的良机。这减少了处理的工作完成总数。
Share the same CQ with several Queues多个队列共享同一个完成队列
Using the same CQ with several Queues and reducing the total number of CQs will eliminate the need to check several CQs in order to understand if an outstanding Work Request was completed. This can be done by sharing the same CQ with multiple Send Queues, multiple Receive Queues or with a mix of them.
多个队列使用同一个完成队列,并减少完成队列的总数,将无需检查多个完成队列来了解未决工作请求是否已完成。这可以通过让多个发送队列、多个接收队列或它们的组合共享同一个完成队列来实现。
6)增加可扩展性|Increase the scalability
Use collective algorithms
Using collective algorithms will reduce the total number of messages that cross the wire and will decrease the total number of messages and resources that each node in a cluster will use. There are RDMA devices that provide special collective offload operations that will help reducing the CPU utilization.
Use Unreliable Datagram (UD) QP
If every node needs to be able to receive or send a message to any other node in the subnet, using a connected QP (either Reliable or Unreliable) may be a bad solution since many QPs will be created in every node. Using a UD QP is better since it can send and receive messages from any other UD QP in the subnet.
减少并发数
【RDMA】qp数量和RDMA性能(节选翻译)https://blog.csdn.net/bandaoyu/article/details/122947096
四、 RNIC+ X
最经典的RNIC的使用方式自然是RNIC + System Memory,即直接通过RNIC来访问内存。但是随着GP-GPU、NVM的发展,通过RNIC来直接访问GPU或者通过RNIC来直接访问NVM都是目前比较成熟和热门的技术。RDMA + GPU可以大幅度加速GPU和GPU之间的通信,RDMA + NVM则可以大幅度的扩大内存容量,减少网络通信的需求。这块内容既涉及到硬件又涉及到操作系统的虚拟内存机制,要讲清楚需要不少篇幅,我们放在下一篇进行介绍。
五、总结
本篇文章主要是介绍一些RDMA的基础概念以及背后的原理,基于这些概念和原理我们介绍了RDMA的常见性能优化技巧,下一篇我们将会介绍RNIC + X,包括RNIC + GPU以及RNIC + NVM的内容介绍,感兴趣的读者朋友可以保持关注~。
六、引用
[1] Dragojević, A., Narayanan, D., Castro, M., & Hodson, O. (2014). {FaRM}: Fast Remote Memory. In 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI 14) (pp. 401-414).
[2] Hauger, S., Wild, T., Mutter, A., Kirstaedter, A., Karras, K., Ohlendorf, R., ... & Scharf, J. (2009, May). Packet processing at 100 Gbps and beyond-challenges and perspectives. In 2009 ITG Symposium on Photonic Networks (pp. 1-10). VDE.
[3] Kalia, A., Kaminsky, M., & Andersen, D. G. (2016). Design guidelines for high performance {RDMA} systems. In 2016 USENIX Annual Technical Conference (USENIX ATC 16) (pp. 437-450).
[4] Physical Address Memory Allocation
[5] Contiguous Memory Allocator - CMA (Linux) | Toradex Developer Center
[6] Kalia, A., Kaminsky, M., & Andersen, D. G. (2014, August). Using RDMA efficiently for key-value services. InProceedings of the 2014 ACM Conference on SIGCOMM(pp. 295-306).
[7] https://github.com/pytorch/tensorpipe
编辑于 2022-06-01 09:43


















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









