







2 数据定义
2.1 Hive中的数据库(database)
Hive中的数据库的概念本质上仅仅是表的一个目录或者命名空间。
2.1.1 查看所有数据库:show databases;
hive (default)> show databases;
创建数据库:create database [if not exists] <database_name>;
hive (default)> create database if not exists financials;注意:所有和数据库相关的命令中,都可以使用schema这个关键字来替代database。
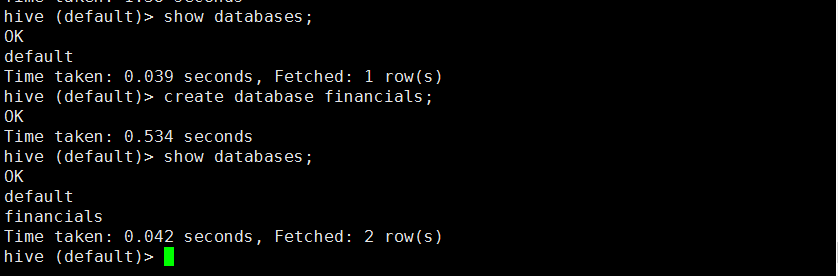
如果数据库非常多,可以使用正则表达式匹配来筛选出需要的数据库名。

创建数据库时,数据库所在的目录是配置文件中hive.metastore.warehouse.dir所配置的顶层目录之后,默认是/usr/hive/warehouse,当创建数据库financials是,Hive将会对应创建一个目录/usr/hive/warehouse/financials.db。注意,数据库的文件目录名都是以.db结尾的。
可以通过添加location来修改这个默认位置,可以通过comment来为数据库添加一个描述信息,且location必须位于comment之后。
hive (default)> create database first_database
> comment 'Holds all my data tables'
> location '/mydirection/mydatabase';2.1.2 查看数据库的信息: describle database < database_name>;
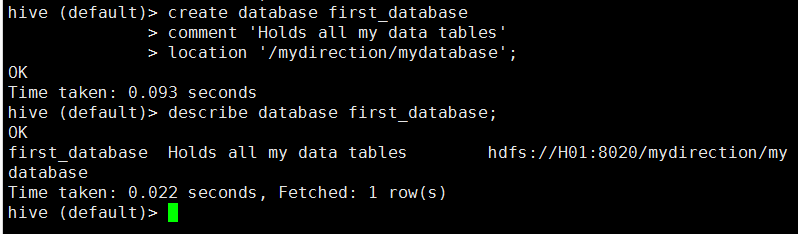
可以使用with dbproperties (key1=value1,key2=value2,...)来给数据库添加一些和其相关的键值对信息,并且必须位于location之后。
hive (default)> create database second_database
> comment 'Holds all my data ex_tables'
> location '/mydirection/mydatabase'
> with dbproperties ('creator'= 'Mark Moneybags', 'date' = '2015-11-6');可以通过describe database extended <database_name>来显示出这些所有的信息。
hive (default)> describe database extended second_database;
2.1.3 使用数据库:use <database_name>;
hive (default)> use financials;

2.1.4 删除数据库:drop database [if exists] financiasl;
hive (financials)> drop database financials;

默认情况下,Hive不支持删除含有表的数据库。要么先删除数据库中的所有表,然后再删除该数据库;要么在删除命了的最后面加上关键字cascade。
hive (default)> drop database first_database cascade;
2.1.5 修改数据库的dbproperties的键值对属性:alter database <database_name> set dbproperties ('edited-by' = 'Oner');
数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录。
2.2 Hive中的表
2.2.1 管理表(内部表)
1 创建表
create table语句遵从SQL语法惯例,但是Hive的这个语句中具有的扩展功能,使其具有更广泛的灵活性。
hive (default)> create table if not exists mydb.employees (
> name string comment 'Employee name',
> salary float comment 'Employee salary',
> subordinates array<string> comment 'Names of subordinates',
> deductions map<string,float> comment 'Keys are deductions name,value are percentages',
> address struct<street:string, city:string, state:string, zip:int> comment 'Home address')
> comment 'Description of the table'
> location '/usr/hive/warehouse/mydb.db/employees'
> tblproperties ('creator'='me', 'created_at'='2015-11-6');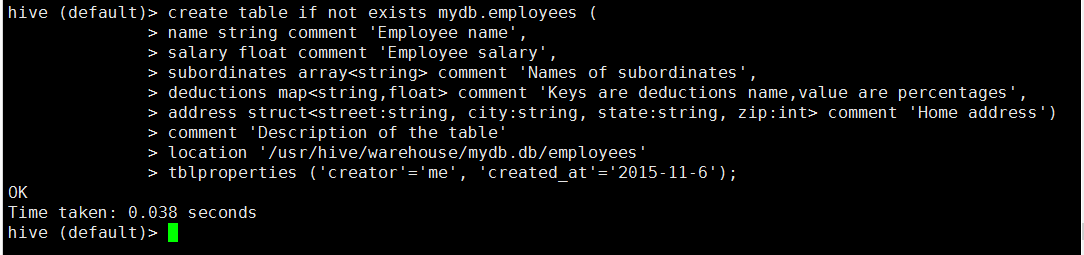
如果当前用户所处的数据库并非目标数据库,建表的时候可以在表名前面增加数据库名来指定,也就是本例中的mydb;用户可以在字段类型后为每个字段增加一个注释,也可以为这个表添加一个注释;tblproperties的主要作用是安键-值对的格式为表添加额外的文档说明。
2 使用表:use <table_name>;
hive (default)> use default;
3 列举数据库下的表:show tables [in <table_name>];
列举当前数据库下的表:
hive (default)> show tables;hive (default)> show tables in mydb;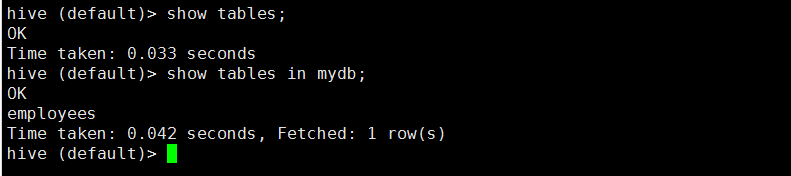
使用正则表达式过滤出所需要的表名:
hive (default)> show tables in mydb 'emp.*';
注意Hive并非支持所有正则表达式功能。
4 查看表的详细信息:describe [extended] [database_name].<table_name>;
或者describe [formatted] [database_name].<table_name>;
hive (default)> describe mydb.employees;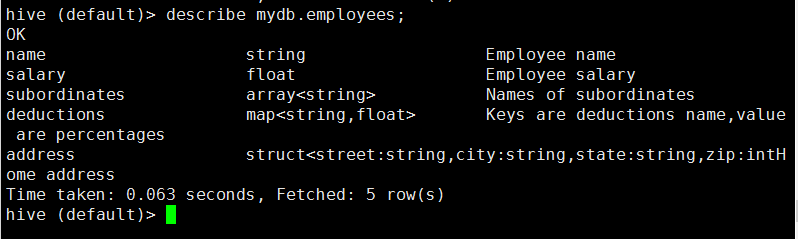
如果当前所处的工作数据库就是mydb,可以不加mydb.这个前缀。
加上extended或者formatted可以显示更详细的信息,使用formatted显示的结果可读性更好,所有formatted用的更多
hive (default)> describe formatted mydb.employees;
如果只想查看某一列的信息,只需要在表名后面添加列的字段名即可。
hive (mydb)> describe employees.salary;

2.2.2 外部表
之前创建的表都是管理表(内部表),在删除一个管理表时,会删除该表的元数据,也会删除表中的数据,如果想要在删除表后,只删除元数据信息,而不删除表中内容,可以考虑使用外部表。
创建外部表
hive (default)> create external table if not exists stocks (
> trade string,
> symbol string,
> ymd string,
> price_open float,
> price_high float,
> price_low float,
> price_close float,
> volume int,
> price_adj_close float)
> row format delimited fields terminated by ','
> location '/data/stocks';关键字external表示这个表示外部的,而后面的location...子句表示外部表指向的数据在哪里。
2.2.3 分区表
1 创建分区表
1)创建内部分区表
创建一个employees表,先按照country在按照state进行分区。
hive (mydb)> create table employees (
> name string,
> salary float,
> subordinates array<string>,
> deductions map<string,float>,
> address struct<street:string, city:string, state:string,zip:int>)
> comment 'Description of the table'
> partitioned by (country string, state string)
> location '/user/hive/warehouse/mydb.db/employees';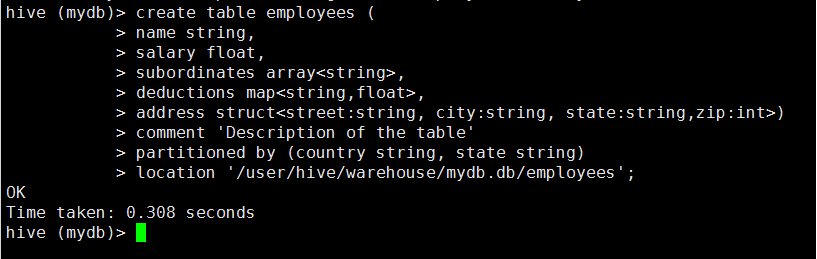
2)创建外部分区表
hive (mydb)> create external table if not exists logs_message (
> hms int,
> severity string,
> server string,
> process_id int,
> message string)
> partitioned by (year int, month int, day int)
> row format delimited fields terminated by '\t';
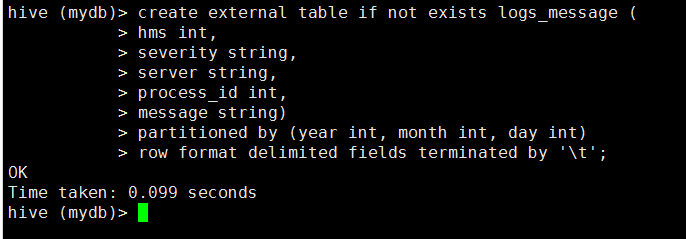
分区表改变了Hive对数据存储的组织方式。
2 显示分区表
show partitions <table_name>;
hive (mydb)> show partitions employees;
2.2.4 修改表
大多数的表的属性可以通过alter table语句来进行修改,这种操作会修改元数据,但不会修改数据本身。
1 表重命名
alter table <table_name> renamt to l<table_newname>;
2 增加、修改和删除表分区
增加分区:alter table <table_name> add partition (partcol=value) [location ...];
hive (mydb)> alter table logs_message add
> partition (year=2015, month=1, day=1) location '/logs/2015/01/01'
> partition (year=2015, month=1, day=2) location '/logs/2015/01/02';
hive (mydb)> alter table logs_message
> partition (year=2015, month=1, day=2) set location 'H01://out/2015/01/02';2.2.5 修改列信息
alter table <table_name> change [column] col_old_name col_new_name column_type [comment col_comment] [first|after column_name];
hive (mydb)> alter table logs_message
> change column hms hours_minutes_seconds int
> comment 'The hours,minutes,and seconds part of the timestamp'
> first;其中,column和comment子句是可选的,first|after column_name是用来指定修改后该列的位置。
2.2.6 增加列
alter table <table_name> add columns (new_column column_type[partition (partcol1=val1, partcol2=val2 ...)]);
hive (mydb)> alter table logs_message add columns (
> app_name string comment 'Application name',
> session_name int comment 'The current session id');
2.2.7 删除/替换列
alter table <table_name> replace columns (new_column column_type[partition (partcol1=val1, partcol2=val2 ...)]);
hive (mydb)> alter table logs_message replace columns (
> hours_mins_secs int comment 'hour,minute,seconds from timestamp',
> severity string comment 'The message severity',
> message string comment 'The rest of the message');2.2.8 修改表属性
alter table <table_name> set tblproperties ('key'='value');
hive (mydb)> alter table logs_message set tblproperties (
> 'notes' = 'The process id is no longer captured, this column is always NULL');2.2.9 修改存储属性
alter table <table_name>[partition (partcol1=val1, partcol2=val2 ...)] set fileformat <fileformat_name>;
hive (mydb)> alter table logs_message
> partition (year=2015, month=1, day=2)
> set fileformat sequencefile;3 数据操作
3.1 向管理表中装载数据
load data [local] inpath 'filepath' [overwrite] into table <table_name> [partition (partcol1=val1, partcol2=val2 ...)];
hive (mydb)> load data local inpath '${env:HOME}/employees.txt'
> overwrite into table employees
> partition (country='US',state='CA');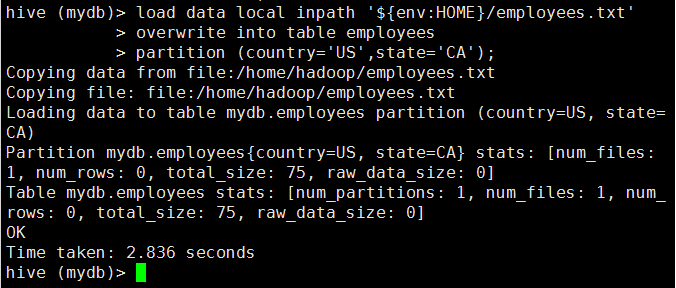
local:
指定了local,代表数据源路径是本地文件系统的路径,该数据将会被copy到目标位置;如果未指定local关键字,这个路径代表的是HDFS上的路径,这种情况下,文件会被move到目标位置。
overwrite:
指定了overwrite目标表(或者分区)中的内容(如果有)会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中;如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,那么现有的文件会被新文件所替代。
partition:
指定了partition,目标分区目录如果不存在的话,系统会自动创建分区目录,然后将数据copy到该目录下;如果目标是非分区表,应省去partition子句。
3.2 将查询结果写入Hive表
3.2.1 基本模式
insert overwrite table <table_name> [partition (partcol1=val1, partcol2=val2 ...)] select_statement fromfrom_statement;
hive (mydb)> insert overwrite employees
> partition (country='US', state='OR')
> select * from staged_employees se
> where se.cnty = 'US' and se.st = 'OR';
3.2.2 多插入模式
from <from_statement>
insert overwrite table <table_name1> [partition (partcol1=val1, partcol2=val2 ...)] select_statement1
insert overwrite table <table_name2> [partition (partcol1=val1, partcol2=val2 ...)] select_statement2;
3.2.3 自动分区模式
insert overwrite table <table_name> partition (partcol1[=val1], partcol2[=val2] ...) select_statement form form_statement;
3.3 导出数据
insert overwrite [local] directory 'directory' select_statement;
导出数据到本地目录:
insert overwrite local directory '${env:HOME}/data' select * from employees;
导出数据到HDFS中:
insert overwrite directory '/user/hive/warehouse/table' select value from employees;
同一个查询结果可以同时插入到多个表或者多个目录中:
from employees se
insert overwrite local directory '${env:HOME}/data' select *
insert overwrite directory '/user/hive/warehouse/table' select * where se.cty='US';

















 1126
1126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









